1.6 MiB
Cобеседование по Java. Разбор вопросов и ответов.
с 678 вопроса по 1606 вопрос
Нажмите ★, если вам нравится проект. Ваш вклад сердечно ♡ приветствуется.
Если вам интересно мое резюме: https://github.com/DEBAGanov
3 Блок вопросов
Содержание:
- Типы данных, переменные, операторы, циклы, массивы
- ООП
- Исключения
- Коллекции
- Строки
- Потоки ввода/вывода
- Потоки выполнения/многопоточность
1. Типы данных, переменные, операторы, циклы, массивы (перейти в раздел)
678. Сколько ключевых слов зарезервировано языком, что это за слова, какие из них не используются?
В языке Java зарезервировано 50 ключевых слов, которые не могут быть использованы как имена переменных, методов и т. д. Вот список этих слов:
abstract, assert, boolean, break, byte, case, catch, char, class, const (unused), continue, default, do, double, else, enum, extends, false, final, finally, float, for, goto (unused), if, implements, import, instanceof, int, interface, long, native, new, null, package, private, protected, public, return, short, static, strictfp, super, switch, synchronized, this, throw, throws, transient, true, try, void, volatile, while
Слова const и goto зарезервированы, но не используются в настоящее время в языке Java.
679. Из каких символов может состоять имя переменной (корректный идентификатор)?
Имя переменной в Java может состоять из букв любого регистра (a-z, A-Z), цифр (0-9), символа подчёркивания (_) и знака доллара ($). Однако, имя переменной не должно начинаться с цифры и не должно совпадать с ключевым словом языка Java. Кроме того, в Java принято использовать camelCase для именования переменных (например, myVariableName), чтобы переменные были легко читаемыми и понятными.
680. Что значит слово “инициализация”?
Инициализация - это процесс присвоения начального значения переменной при объявлении или до первого использования переменной. Присваивание начального значения переменной при объявлении называется "полями класса инициализации", а присваивание начального значения локальной переменной перед ее первым использованием называется "инициализацией переменной". Поля класса могут инициализироваться явно, как например:
public class MyClass {
int x = 5;
}
Или могут быть инициализированы в блоке инициализации:
public class MyClass {
int x;
{
x = 5;
}
}
Локальные переменные должны быть инициализированы перед использованием, например:
public class MyClass {
public void myMethod() {
int x = 5; // переменная x должна быть инициализирована перед использованием
System.out.println(x);
}
}
Иначе компилятор Java выдаст ошибку компиляции.
681. На какие основные группы можно поделить типы данных?
В Java типы данных можно поделить на примитивные (primitive data types) и ссылочные (reference data types). К примитивным типам данных относятся:
- byte
- short
- int
- long
- float
- double
- boolean
- char
Эти типы данных хранятся в стеке и могут быть использованы для простого хранения целых, вещественных и логических значений.
Кроме того, существуют также ссылочные типы данных, такие как классы, массивы и перечисления. Эти типы данных хранятся в куче и представляют более сложные структуры данных, состоящие из различных примитивных типов данных и ссылок на другие объекты.
В целом, основным критерием разделения типов данных в Java является то, где они хранятся в памяти и как они могут быть использованы в программах.
682. Какие примитивные типы вы знаете?
В Java есть 8 примитивных типов данных: byte, short, int, long, float, double, char, boolean.
byte- 8-битное целое число со знаком в диапазоне от -128 до 127short- 16-битное целое число со знаком в диапазоне от -32768 до 32767int- 32-битное целое число со знаком в диапазоне от -2147483648 до 2147483647long- 64-битное целое число со знаком в диапазоне от -9223372036854775808 до 9223372036854775807float- 32-битное число с плавающей точкойdouble- 64-битное число с плавающей точкойchar- 16-битный Unicode символboolean- логический тип данных, который может принимать значение true или false
Примеры объявления переменных с примитивными типами данных в Java:
byte b = 10;
short s = 20;
int i = 100;
long l = 1000000L;
float f = 1.5f;
double d = 3.14159;
char c = 'A';
boolean bool = true;
683. Что вы знаете о преобразовании примитивных типов данных, есть ли потеря данных, можно ли преобразовать логический тип?
В языке Java есть возможность преобразования примитивных типов данных из одного типа в другой. Это может потребоваться, например, для выполнения арифметических операций, когда операнды имеют разные типы данных.
При преобразовании типов данных может происходить потеря данных, если значение, которое мы пытаемся преобразовать, выходит за пределы допустимого диапазона целевого типа. Например, при преобразовании числа типа int в тип byte могут потеряться старшие биты числа, что приведет к изменению его значения.
В языке Java также есть возможность преобразования логического типа данных boolean в другие типы данных и наоборот. При этом значение true преобразуется в число 1, а значение false в число 0.
Вот примеры преобразований между типами данных в Java:
int i = 42;
long l = i; // автоматическое преобразование типов данных
double d = 3.14;
int j = (int) d; // явное преобразование типов данных
boolean b = true;
int k = b ? 1 : 0; // преобразование логического типа данных в число
При преобразовании типов данных может потребоваться явное преобразование или приведение типов, чтобы избежать потери данных.
684. Какими значениями инициализируются переменные по умолчанию?
В Java, переменные по умолчанию инициализируются следующим образом:
Числовые типы (byte, short, int, long, float, double) и тип char инициализируются нулевым значением (0 или 0.0).
Логический тип (boolean) инициализируется значением false.
Типы-объекты (Object) инициализируются значением null.
Локальные переменные (включая параметры методов) не инициализируются автоматически по умолчанию, поэтому они должны быть явно проинициализированы перед использованием в коде.
Пример:
public class MyClass {
int myInt;
double myDouble;
boolean myBoolean;
Object myObject;
public static void main(String[] args) {
MyClass example = new MyClass();
System.out.println(example.myInt); // 0
System.out.println(example.myDouble); // 0.0
System.out.println(example.myBoolean); // false
System.out.println(example.myObject); // null
}
}
685. Как передается значение переменной (по ссылке/значению)?
В Java все передается по значению, даже объекты передаются по значению ссылки на них. Это значит, что когда вы передаете переменную в метод, то передается ее значение, которое можно изменять внутри метода, но наружу метода это не влияет. Однако, если переменная ссылается на объект, то передается копия ссылки на объект, который находится в хипе, а не сам объект. Таким образом, если вы изменяете объект в методе, то эти изменения будут видны наружу метода, потому что ссылки снаружи и внутри метода указывают на один и тот же объект в хипе.
Например, рассмотрим класс Person:
class Person {
private String name;
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
}
Теперь вызовем метод, который изменяет значение поля name переданного объекта:
public static void changeName(Person p) {
p.setName("John");
}
Используя этот метод можно изменить имя объекта p, который был передан в метод:
Person p = new Person();
p.setName("Tom");
System.out.println(p.getName()); // output: Tom
changeName(p);
System.out.println(p.getName()); // output: John
Как видно, имя объекта p было изменено в методе changeName, но эти изменения были видны и при обращении к объекту p снаружи метода.
Любые примитивные типы передаются по значению, если вы попытаетесь изменить их значение в методе, то это никак не отразится на оригинальном значении.
686. Что вы знаете о функции main, какие обязательные условия ее определения?
Функция main в языке Java является точкой входа в программу, которая выполняется при запуске приложения. Она обязательно должна иметь следующую сигнатуру:
public static void main(String[] args)
где public означает , что функция доступна для вызова из любой части программы, static означает, что функция является статической и может вызываться без создания экземпляра класса, void указывает на то, что функция не возвращает значение, а String[] args представляет массив аргументов командной строки.
Таким образом, функция main должна быть обязательно определена в классе, который является точкой входа в программу. Этот класс должен быть публичным и содержать статический метод main. Аргументы командной строки, передаваемые в функцию main, можно использовать для конфигурирования приложения или передачи данных при запуске программы.
Например:
public class Main {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Этот код определяет класс Main с публичным, статическим методом main , который выводит сообщение "Hello World!" в консоль при запуске программы.
687. Какие логические операции и операторы вы знаете?
В Java есть три логических оператора: && для логического "и" (and), || для логического "или" (or) и ! для логического отрицания (not). Операторы && и || выполняются по правилу "ленивого вычисления" (short-circuiting), то есть если результат выражения может быть определен на основе первого операнда, то второй операнд не вычисляется. Кроме того, в Java есть битовые операторы & (and), | (or) и ^ (xor), которые могут быть применены к целочисленным типам и перечилям (enum).
Примеры использования логических операторов:
int x = 10, y = 5;
if (x > 5 && y < 10) {
// выполняется, если x > 5 И y < 10
}
if (x > 5 || y < 2) {
// выполняется, если x > 5 ИЛИ y < 2
}
if (!(x > 5)) {
// выполняется, если x НЕ больше 5
}
Примеры использования битовых операторов:
int x = 5, y = 3;
int z = x & y; // результат: 1 (бинарное 01 & 11 = 01)
z = x | y; // результат: 7 (бинарное 01 | 11 = 11)
z = x ^ y; // результат: 6 (бинарное 01 ^ 11 = 10)
688. В чем разница краткой и полной схемы записи логических операторов?
В Java есть два способа записи логических операторов: краткая форма (&& и ||) и полная форма (& и |).
Краткая форма используется для выполнения логических операций над булевыми операндами и имеет более высокий приоритет. Кроме того, в краткой форме операнды вычисляются лениво, то есть второй операнд не вычисляется, если первый операнд уже дает конечный результат.
Полная форма используется для выполнения логических операций над целочисленными значениями и не ленивая. Оба операнда всегда вычисляются.
Вот пример кода, который иллюстрирует разницу между этими двумя формами записи:
boolean a = true;
boolean b = false;
boolean c = true;
boolean d = false;
boolean result;
// Краткая форма, дает true, так как a и b оба являются false; операнда b не вычисляется, т.к. первый операнд уже даёт конечный результат
result = a && b;
System.out.println(result); // Вывод: false
// Полная форма, результат такой же, но оба операнда вычисляются
result = a & b;
System.out.println(result); // Вывод: false
// Краткая форма, дает true, так как хотя бы один из операндов (c) является true; операция вычисляется лениво
result = c || d;
System.out.println(result); // Вывод: true
// Полная форма, результат такой же, но оба операнда вычисляются
result = c | d;
System.out.println(result); // Вывод: true
689. Что такое таблица истинности?
Таблица истинности - это таблица, которая отображает значения логических выражений в зависимости от значений их компонентов (входов). В контексте программирования на Java, это может быть полезным для понимания логических операций, таких как операторы И (&&), ИЛИ (||) и НЕ (!).
Таблица истинности в Java показывает все возможные комбинации значений исходных данных и вычисленные результаты.
| A | B | A | B | A & B | A ^ B | !A |
|---|---|---|---|---|---|
| false | false | false | false | false | true |
| true | false | true | false | true | false |
| false | true | true | false | true | true |
| true | true | true | true | false | false |
Таблица истинности может быть полезной для проверки правильности логических выражений и операторов в Java. Вы можете использовать таблицу истинности, чтобы определить, какие значения будут возвращены при заданных исходных данных, или для проверки, будет ли выражение возвращать ожидаемый результат.
Например, если учитывать таблицу истинности оператора &&, то true && true вернет true, тогда как false && true или true && false вернут false.
В целом, таблица истинности полезна для проверки логических операторов и выражений в Java, и может помочь избежать ошибок в программировании.
690. Что такое тернарный оператор выбора?
Тернарный оператор выбора - это сокращенная форма записи условного оператора if-else в Java. Он позволяет сократить код и улучшить его читаемость, особенно если необходимо присвоить переменной значение в зависимости от некоторого условия.
Синтаксис тернарного оператора выбора:
условие ? выражение1 : выражение2
Если условие верно, тогда возвращается выражение1, иначе возвращается выражение2.
Например,
int x = 10;
int y = 20;
int max = (x > y) ? x : y;
В этом примере, если значение переменной x больше значения переменной y, то переменной max присваивается значение x, иначе переменной max присваивается значение y.
Тернарный оператор выбора можно использовать в любом месте кода, где необходимо выбрать одно из двух значений в зависимости от условия. Он также может использоваться в качестве аргумента в методах и возвращать значение.
691. Какие унарные и бинарные арифметические операции вы знаете?
Для целочисленных типов данных в Java доступны следующие унарные и бинарные арифметические операции:
Унарные операции:
унарный плюс (+)- не меняет знак числаунарный минус (-)- меняет знак числа на противоположныйинкремент (++)- увеличивает значение переменной на 1декремент (--)- уменьшает значение переменной на 1
Бинарные операции:
сложение (+)вычитание (-)умножение (*)деление (/)остаток от деления (%)побитовое И (&)побитовое ИЛИ (|)побитовое исключающее ИЛИ (^)побитовый сдвиг влево (<<)побитовый сдвиг вправо с заполнением нулями (>>)побитовый сдвиг вправо с заполнением знаковым битом (>>>)
В Java также доступны операции сравнения (==, !=, >, >=, <, <=), логические операторы (&&, ||, !) и тернарный оператор (условие ? значение_если_истина : значение_если_ложь).
Некоторые из этих операций также доступны для вещественных типов данных (float и double), однако при работе с вещественными числами наличие округлений может привести к неточным результатам.
692. Какие побитовые операции вы знаете?
В Java есть несколько побитовых операций, которые могут быть полезны при работе с битами двоичных чисел. Некоторые из них перечислены ниже:
-
& (логическое И): возвращает бит 1 только в том случае, если оба операнда имеют значение 1, в противном случае возвращает 0. -
| (логическое ИЛИ): возвращает бит 1 только в том случае, если хотя бы один из операндов имеет значение 1, в противном случае возвращает 0. -
^ (исключающее ИЛИ): возвращает бит 1 только в том случае, если только один из операндов имеет значение 1, в противном случае возвращает 0. -
~ (унарный оператор НЕ): инвертирует значения всех битов операнда. -
<< (левый сдвиг): сдвигает биты операнда влево на заданное количество позиций. -
>> (правый сдвиг с сохранением знака): сдвигает биты операнда вправо на заданное количество позиций, при этом знак операнда сохраняется. -
>>> (беззнаковый правый сдвиг): сдвигает биты операнда вправо на заданное количество позиций, при этом знак операнда не сохраняется.
Примеры:
Побитовый AND (&) - возвращает бит, который установлен в обоих операндах.
int a = 5;
int b = 3;
int c = a & b; // c будет равно 1
Побитовый OR (|) - возвращает бит, который установлен хотя бы в одном из операндов. Например:
int a = 5;
int b = 3;
int c = a | b; // c будет равно 7
Побитовый XOR (^) - возвращает бит, который установлен только в одном из операндов. Например:
int a = 5;
int b = 3;
int c = a ^ b; // c будет равно 6
Побитовый NOT (~) - инвертирует все биты операнда. Например:
int a = 5;
int b = ~a; // b будет равно -6
Сдвиг вправо (>>) - сдвигает биты операнда вправо на указанное число позиций. Например:
int a = 10;
int b = a >> 2; // b будет равно 2
Сдвиг влево (<<) - сдвигает биты операнда влево на указанное число позиций. Например:
int a = 10;
int b = a << 2; // b будет равно 40
Сдвиг вправо с заполнением нулями (>>>) - сдвигает биты операнда вправо на указанное число позиций, при этом заполняет освободившиеся позиции нулями. Например:
int a = -10;
int b = a >>> 2;
693. Какова роль и правила написания оператора выбора (switch)?
В Java оператор выбора switch используется для проверки значения выражения и выполнения соответствующего блока кода в зависимости от значения этого выражения. Оператор switch следует за ключевым словом switch, которое за ним следует выражение, которое нужно проверить. Затем внутри блока кода switch можно объявить несколько блоков case, каждый из которых содержит значение, с которым нужно сравнить выражение, после которого следует блок кода, который нужно выполнить, если значение выражения соответствует значению case.
Вот пример использования оператора выбора switch в Java:
int day = 3;
String dayName;
switch (day) {
case 1:
dayName = "Monday";
break;
case 2:
dayName = "Tuesday";
break;
case 3:
dayName = "Wednesday";
break;
case 4:
dayName = "Thursday";
break;
case 5:
dayName = "Friday";
break;
case 6:
dayName = "Saturday";
break;
case 7:
dayName = "Sunday";
break;
default:
dayName = "Invalid day";
break;
}
System.out.println(dayName);
В этом примере оператор switch проверяет значение переменной day, после чего выполняет соответствующий блок кода. В данном случае переменная day имеет значение 3, поэтому переменная dayName будет установлена на "Wednesday". Если значение day не соответствует ни одному из значений case, выполнится блок кода по умолчанию (default).
Один из важных моментов при использовании оператора switch - не забывать про ключевое слово break для окончания блока case.
694. Какие циклы вы знаете, в чем их отличия?
В Java существует несколько типов циклов:
-
Цикл for- используется, когда необходимо выполнить некоторый код заданное количество раз. For имеет три выражения, разделенных точками с запятой: инициализация, условие и инкремент. -
Цикл while- используется, когда количество итераций неизвестно заранее. Цикл выполняется, пока условие остается истинным. -
Цикл do-while- выполняется до тех пор, пока условие, заданное в while, остается истинным. Этот цикл гарантирует, что код внутри цикла будет выполнен хотя бы один раз.
Вот простой пример каждого:
for (int i = 0; i < 10; i++) {
System.out.println(i);
}
int i = 0;
while (i < 10) {
System.out.println(i);
i++;
}
int j = 0;
do {
System.out.println(j);
j++;
} while (j < 10);
В этом примере for выполняет код внутри тела цикла 10 раз, пока переменная i не достигнет 10.
While продолжает выполнение, пока переменная i меньше 10.
Do-while также продолжает выполнение, пока переменная j меньше 10, но гарантирует, что код внутри блока do выполнится, как минимум, один раз.
Это основные типы циклов в Java с их основными отличиями.
695. Что такое “итерация цикла”?
"Итерация цикла" в Java означает один проход цикла через тело цикла. Например, в цикле for, каждая итерация выполняет блок кода между открывающей и закрывающей фигурными скобками. Затем проверяется условие цикла и, если оно истинно, выполняется еще одна итерация. Этот процесс продолжается до тех пор, пока условие не станет ложным.
В цикле while и do-while, итерация будет происходить до тех пор, пока условие остается истинным. В случае цикла do-while тело цикла выполнится хотя бы один раз, независимо от того, выполнится ли условие цикла впоследствии.
В циклах for-each каждая итерация перебирает элементы массива или коллекции, к которым она применяется.
Итерация цикла - это основной механизм управления поведением повторяющихся блоков кода в Java и других языках программирования.
696. Какие параметры имеет цикл for, можно ли их не задать?
Цикл for в Java имеет три параметра, разделенных точкой с запятой (;):
-
Инициализация переменной. В этом параметре обычно создают переменную и присваивают ей начальное значение. -
Условие продолжения цикла. Это булевское выражение, которое определяет, должен ли продолжаться цикл в текущей итерации или нет. Если условие истинно, то цикл продолжается, если ложно, то цикл завершается. -
Выражение обновления. Это выражение выполняется после каждой итерации цикла перед проверкой условия продолжения. Обычно это выражение используется для изменения значения переменной, созданной в первом параметре.
Примеры:
В Java цикл for используется для повторения блока кода заданное количество раз или для прохождения через элементы коллекции или массива. Параметры цикла включают в себя инициализацию счетчика, условие продолжения цикла и выражение обновления счетчика. Вот как выглядит общий синтаксис цикла for в Java:
for (initialization; condition; update) {
// блок кода для повторения
}
Инициализация устанавливает начальное значение для счетчика, например int i = 0. Условие продолжения цикла проверяется на каждой итерации цикла, и если оно истинно, цикл продолжается. Выражение обновления обновляет счетчик на каждой итерации, например i++.
В цикле for можно не задавать все три параметра. Если вам нужно только повторять блок кода определенное количество раз, вы можете опустить условие продолжения. Например, следующий цикл выполнится точно десять раз:
for (int i = 0; i < 10; i++) {
// блок кода для повторения
}
Если вам нужно бесконечно повторять блок кода, вы можете опустить все три параметра:
for (;;) {
// блок кода для повторения бесконечного количества раз
}
697. Какой оператор используется для немедленной остановки цикла?
В Java для немедленной остановки цикла можно использовать оператор break. Он позволяет выйти из цикла на любой итерации и продолжить выполнение кода после цикла. Пример:
for (int i = 0; i < 10; i++) {
if (i == 5) {
break; // выходим из цикла при i=5
}
System.out.println(i);
}
Этот код выведет числа от 0 до 4 включительно.
698. Какой оператор используется для перехода к следующей итерации цикла?
В Java оператор continue используется для перехода к следующей итерации цикла. Когда continue вызывается в цикле, текущая итерация цикла прерывается, и выполнение переходит к следующей итерации. Пример использования оператора continue в цикле for:
for (int i = 0; i < 10; i++) {
if (i == 5) {
continue; // пропустить итерацию i=5
}
System.out.println(i);
}
В этом примере в цикле for вызывается оператор continue, когда i равно 5. В результате этой итерация цикла пропускается, и выполнение продолжается со следующей итерации.
699. Что такое массив?
Массив (array) в Java это объект, который хранит фиксированное количество значений одного типа. Длина массива устанавливается при его создании, и после этого изменить длину массива уже нельзя. Каждое значение в массиве имеет свой индекс, начиная с 0. Индексы в Java массивах могут быть целочисленного типа. Массивы могут содержать как примитивные типы данных (например, int, double, char), так и объекты (например, строки, другие массивы и т.д.).
Пример создания и инициализации одномерного массива целых чисел:
int[] numbers = {1, 2, 3, 4, 5};
Пример создания двумерного массива целых чисел:
int[][] matrix = {{1, 2}, {3, 4}, {5, 6}};
Для доступа к элементам массива используется индексация:
int firstNumber = numbers[0]; // первый элемент массива numbers
int secondNumber = numbers[1]; // второй элемент массива numbers
int element = matrix[1][0]; // элемент матрицы matrix во второй строке и первом столбце
Для получения длины массива используется свойство length:
int length = numbers.length; // длина массива numbers (равна 5)
700. Какие виды массивов вы знаете?
Вы можете использовать обычный одномерный массив, многомерные массивы, динамические массивы, массивы объектов и массивы списков.
Вот примеры объявления каждого из них:
Одномерный массив:
int[] arr = new int[10];
Многомерный массив:
int[][] multiArr = new int[10][5];
Динамический массив:
ArrayList<Integer> arrList = new ArrayList<Integer>();
Массив объектов:
MyObject[] objArr = new MyObject[10];
Массив списков:
List<Integer>[] listArr = new List[10];
for(int i = 0; i < 10; i++) {
listArr[i] = new ArrayList<Integer>();
}
В каждом из этих случаев мы можем обращаться к элементам массива по индексу и выполнять различные операции с массивами, такие как добавление, удаление или изменение элементов.
Однако, убедитесь, что используете соответствующий тип массива для конкретной задачи, чтобы добиться наилучшей производительности и оптимизировать свой код.
701. Что вы знаете о классах оболочках?
Классы оболочки (Wrapper classes) - это классы в Java, которые инкапсулируют типы данных примитивов и предоставляют методы и конструкторы для работы с этими типами данных в объектно-ориентированном стиле. Классы оболочки могут быть полезны при работе с коллекциями, фреймворками и другими библиотеками, которые требуют объектных типов данных.
В Java существует 8 классов оболочек: Byte, Short, Integer, Long, Float, Double, Character, Boolean.
Каждый из этих классов имеет конструкторы для создания объектов, методы для преобразования между примитивными значениями и объектными значениями, методы для сравнения значений, а также набор статических методов для работы с соответствующими типами данных, например, метод parseInt() у класса Integer для парсинга целочисленных строк.
Пример создания объекта класса Integer:
Integer myInt = new Integer(42);
Пример использования метода parseInt() класса Integer:
int myInt = Integer.parseInt("42");
Кроме того, для каждого класса оболочки есть статические поля для представления минимального и максимального значений этого типа данных.
Например, для класса Integer минимальное и максимальное значение можно получить следующим образом:
int minValue = Integer.MIN_VALUE;
int maxValue = Integer.MAX_VALUE;
702. Что такое автоупаковка (boxing/unboxing)?
Автоупаковка (autoboxing) и автораспаковка (unboxing) в Java - это механизмы, которые автоматически преобразуют примитивные типы данных в их соответствующие классы-оболочки и наоборот.
Например, вы можете объявить переменную Integer и присвоить ей значение типа int, как показано ниже:
Integer myInteger = 10;
Это возможно благодаря автоупаковке, которая автоматически преобразует примитивный тип данных int в Integer. Автораспаковка работает в обратном направлении - она автоматически преобразует объект Integer в примитивный тип данных int.
Вот пример:
Integer myInteger = 10;
int myInt = myInteger;
В этом примере автораспаковка автоматически преобразует объект Integer в примитивный тип данных int.
Автоупаковка и автораспаковка упрощают код и делают его более читаемым, но могут привести к некоторым проблемам производительности, особенно если они используются в больших или часто вызываемых методах.
2. ООП (перейти в раздел)
703. Назовите принципы ООП и расскажите о каждом.
ООП (объектно-ориентированное программирование) - это методология программирования, в которой программа организована вокруг объектов, которые могут содержать данные (поля) и функциональность (методы). ООП позволяет создавать гибкие, расширяемые и повторно используемые программы.
Классы являются основными сущностями в Java, и они определяют состояние (поля) и поведение (методы) объектов.
Основными принципами объектно-ориентированного программирования (ООП) являются абстракция, инкапсуляция, наследование и полиморфизм.
-
Абстракция- это концепция, которая позволяет скрыть ненужные детали и подробности реализации объектов, фокусируясь на их важных характеристиках и свойствах. Абстракция позволяет создавать более понятный и легко поддерживаемый код. -
Инкапсуляция- это механизм, который позволяет объединить данные и методы, которые работают с этими данными, в одном классе, скрыть внутреннюю реализацию объекта и обеспечить доступ к ним только через определенный интерфейс. Это делает код более организованным и уменьшает возможность ошибок взаимодействия компонентов. -
Наследование- это способность класса наследовать свойства и методы от другого базового класса, что позволяет повторно использовать код, упрощает его сопровождение и расширение. В результате наследования, новый класс содержит все свойства и методы базового класса, а также может добавлять свои собственные свойства и методы. -
Полиморфизм- это способность объектов одного и того же базового класса проявлять свои свойства и методы по-разному в зависимости от ситуации. Это позволяет программисту управлять поведением объекта в различных контекстах. Методы могут быть переопределены для предоставления новой реализации в производных классах.
704. Дайте определение понятию “класс”.
Класс - это шаблон или определение для создания объектов, который описывает состояние и поведение объекта. Он является основной концепцией объектно-ориентированного программирования (ООП) в Java.
Класс в Java состоит из переменных класса, методов, конструкторов и вложенных классов или интерфейсов. Переменные класса хранят состояние объекта, методы определяют поведение объекта и конструкторы создают экземпляры объектов.
В Java каждый объект является экземпляром класса, а класс определяет атрибуты и методы, которые доступны для каждого экземпляра объекта. Классы также могут наследоваться друг от друга, что позволяет создавать иерархии классов и создавать более сложные системы объектов.
705. Что такое поле/атрибут класса?
Поле или атрибут класса в Java - это переменная, объявленная внутри класса, и которая содержит данные, относящиеся к этому классу. Она может быть статической или нестатической.
Статическое поле класса принадлежит классу, а не объекту, и используется общим для всех экземпляров этого класса. Статические поля могут использоваться без создания экземпляра класса.
Нестатическое поле или экземпляр переменной принадлежит объекту класса и каждый объект имеет свою собственную копию этой переменной. Нестатические поля не могут быть использованы, пока не создан экземпляр класса.
Пример объявления поля в Java:
public class MyClass {
int x; // нестатическое поле класса
static int y; // статическое поле класса
}
Код int x объявляет нестатическое поле класса, а static int y объявляет статическое поле класса.
Для доступа к нестатическому полю класса, нужно создать экземпляр класса и использовать точечный (" . ") оператор. Для доступа к статическому полю, можно использовать имя класса, за которым следует точечный (" . ") оператор.
Пример использования полей класса:
MyClass obj = new MyClass();
obj.x = 5; // устанавливаем нестатическое поле для экземпляра obj
MyClass.y = 10; // устанавливаем статическое поле для класса MyClass
706. Как правильно организовать доступ к полям класса?
Для организации доступа к полям класса в Java используются методы-геттеры (get) и методы-сеттеры (set). Геттеры позволяют получать значение поля, а сеттеры - устанавливать его. Они возвращают и принимают соответственно значение поля.
Пример:
public class MyClass {
private int myField;
public int getMyField() {
return myField;
}
public void setMyField(int myField) {
this.myField = myField;
}
}
В этом примере myField - приватное поле класса. Метод getMyField() позволяет получить значение поля, а метод setMyField(int myField) устанавливать его.
Таким образом, чтобы получить доступ к приватным полям класса в Java, можно использовать соответствующие геттеры и сеттеры. Это позволяет контролировать доступ к полям класса и изменять их значение только в том случае, когда это необходимо.
Также можно использовать модификаторы доступа для ограничения доступа к полям и методам класса. Например, чтобы разрешить доступ только из класса и его подклассов, можно использовать модификатор protected.
public class MyClass {
protected int myField;
public int getMyField() {
return myField;
}
public void setMyField(int value) {
myField = value;
}
}
В этом примере myField является защищенным полем класса MyClass, что означает, что к нему можно обращаться из класса и его подклассов, но не из других классов.
707. Дайте определение понятию “конструктор”.
Конструктор в Java - это метод, который вызывается при создании нового объекта класса. Он используется для инициализации свойств объекта и выполнения других операций, которые должны быть выполнены при создании объекта. Конструктор имеет тот же самый имя, что и класс, в котором он определен, и может принимать аргументы, которые используются для инициализации свойств объекта.
Конструкторы могут быть перегружены, то есть класс может иметь несколько конструкторов с разным количеством и типом аргументов. При вызове конструктора Java автоматически резервирует память для объекта в памяти и вызывает конструктор для инициализации его свойств.
Пример определения конструктора в Java для класса Person:
public class Person {
private String name;
private int age;
// Конструктор с двумя аргументами
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// Конструктор без аргументов
public Person() {
this.name = "Unknown";
this.age = 0;
}
}
Здесь Person - это класс с двумя свойствами: name и age. У него есть два конструктора: один принимает два аргумента - имя и возраст - и используется для создания объекта Person с заданными значениями свойств, а другой не принимает аргументов и используется для создания объекта с значениями свойств по умолчанию - "Unknown" и 0.
708. Чем отличаются конструкторы по умолчанию, копирования и конструктор с параметрам?
В Java конструктор по умолчанию создается автоматически, когда вы не создаете конструктор явно. Он не принимает аргументов и инициализирует все переменные-члены значениями по умолчанию.
Конструктор копирования в Java позволяет создать новый объект с такими же значениями переменных-членов, как у существующего объекта. Конструктор копирования принимает аргумент, который является другим объектом того же типа, что и создаваемый объект.
Конструктор с параметрами в Java позволяет передать значения для инициализации переменных-членов класса при создании объекта. Он принимает один или несколько аргументов, которые используются для инициализации переменных-членов класса.
Основное отличие между этими тремя типами конструкторов заключается в том, как они инициализируют переменные-члены объекта при его создании. Конструктор по умолчанию инициализирует переменные-члены значениями по умолчанию, конструктор с параметрами инициализирует их переданными значениями, а конструктор копирования копирует значения из другого объекта.
Примеры реализации конструкторов в Java:
public class MyClass {
int x;
String s;
// конструктор по умолчанию
public MyClass() {
x = 0;
s = "";
}
// конструктор с параметрами
public MyClass(int x, String s) {
this.x = x;
this.s = s;
}
// конструктор копирования
public MyClass(MyClass other) {
this.x = other.x;
this.s = other.s;
}
}
Здесь this используется для обращения к переменным-членам класса внутри конструкторов.
709. Какие модификации уровня доступа вы знаете, расскажите про каждый из них.
В языке Java существуют четыре модификатора уровня доступа:
-
public- доступен из любого места в программе, а также из других программ. -
protected- доступен внутри пакета и в наследниках класса. -
default (или package-private)- доступен только внутри пакета. -
private- доступен только внутри класса, где он был объявлен.
Ключевое слово public используется тогда, когда требуется, чтобы методы, переменные или классы были доступны из любой части программы. Модификатор protected используется для того, чтобы сделать члены класса доступными только для классов, наследующих данный класс, или для всех классов внутри того же пакета. Default является модификатором по умолчанию и допускает доступ только из тех классов и пакетов, которые находятся в том же пакете, что и класс с модификатором по умолчанию. Private используется для ограничения доступа к члену класса только для внутреннего использования в этом классе.
Примеры:
// public modifier
public class Example {
public int num = 10;
public void method() {
System.out.println("This is a public method");
}
}
// protected modifier
public class Example {
protected int num = 10;
protected void method() {
System.out.println("This is a protected method");
}
}
// default (package-private) modifier
class Example {
int num = 10;
void method() {
System.out.println("This is a default method");
}
}
// private modifier
public class Example {
private int num = 10;
private void method() {
System.out.println("This is a private method");
}
}
710. Расскажите об особенностях класса с единственным закрытым (private) конструктором.
Класс с единственным закрытым (private) конструктором - это класс, который не может быть создан вне своего собственного класса. Это означает, что объекты этого класса могут быть созданы только внутри самого класса. Этот подход называется Singleton Pattern.
Конструктор становится закрытым (private) для того, чтобы предотвратить создание новых объектов с помощью ключевого слова new. Вместо этого, для создания объекта используется статический метод или переменная класса, которые также обычно имеют модификатор доступа private.
Этот подход широко используется в приложениях для управления ресурсами, например, для создания одного экземпляра класса, который будет обслуживать все запросы на сетевое соединение, базу данных или файловую систему.
Вот пример класса с единственным закрытым (private) конструктором на языке Java:
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
}
В данном классе мы создаем статический объект Singleton, и закрываем конструктор для создания новых объектов с помощью ключевого слова private. Вместо этого мы создаем публичный метод getInstance(), который возвращает единственный объект Singleton и который можно использовать в других частях программы.
711. О чем говорят ключевые слова “this”, “super”, где и как их можно использовать?
Ключевое слово this в Java используется для обращения к текущему объекту. Оно используется, например, для доступа к полям и методам объекта.
Ключевое слово super используется для обращения к родительскому классу (суперклассу) текущего объекта. Оно часто используется в случаях, когда требуется вызвать конструктор суперкласса или переопределить метод суперкласса.
this и super можно использовать в любом месте, где есть доступ к объекту или суперклассу. Например, их можно использовать в конструкторах классов или в методах экземпляра класса.
Пример использования this:
public class MyClass {
private int myField;
public MyClass(int myField) {
this.myField = myField; // Обращение к полю myField текущего объекта
}
public void doSomething() {
System.out.println(this.myField); // Обращение к полю myField текущего объекта
}
}
Пример использования super:
public class MySubClass extends MySuperClass {
public MySubClass(int myField) {
super(myField); // Вызов конструктора суперкласса
}
@Override
public void doSomething() {
super.doSomething(); // Вызов метода doSomething() суперкласса
// Дополнительный функционал
}
}
712. Дайте определение понятию “метод”.
Метод в Java - это фрагмент кода, который выполняет определенную функцию или задачу, и который можно вызывать из других частей программы. Методы обычно используются для уменьшения дублирования кода и упрощения программы с помощью разбиения ее на более мелкие и управляемые куски. Методы могут принимать параметры и возвращать значения. Определение метода в Java включает имя метода, тип возвращаемого значения (если есть), список параметров и тело метода.
Например, вот пример определения метода greet(), который принимает аргумент name типа String и возвращает приветствие, содержащее это имя:
public String greet(String name) {
return "Hello, " + name + "!";
}
Этот метод может быть вызван из другой части программы следующим образом:
String message = greet("John");
System.out.println(message); // выводит "Hello, John!"
Cуществует ряд встроенных методов, которые являются частью классов ядра Java и могут быть использованы в любой программе. Например, метод System.out.println() используется для вывода текста в консоль.
713. Что такое сигнатура метода?
В Java сигнатура метода - это уникальное имя метода, которое содержит его имя, аргументы и тип возвращаемого значения. Сигнатура метода используется для определения перегруженных методов - методов с одинаковым именем, но разным числом или типом аргументов. В Java, перегруженные методы должны иметь разные сигнатуры методов, но могут иметь одно и то же имя. Например, возьмем следующий класс:
public class MyClass {
public int sum(int a, int b) {
return a + b;
}
public double sum(double a, double b) {
return a + b;
}
}
У класса MyClass два перегруженных метода sum - один для суммирования двух целых чисел и один для суммирования двух дробных чисел. Эти методы имеют разные сигнатуры, так как они принимают аргументы разных типов, и компилятор Java может различить их и использовать подходящий метод в зависимости от типов аргументов.
714. Какие методы называются перегруженными?
В Java методы называются перегруженными, если у них одинаковое имя, но разные параметры (тип и/или количество). Это позволяет создавать несколько методов с одним именем, но разными параметрами, что делает код более читабельным и удобным в использовании. Например:
public void print(int n) {
System.out.println("Integer: " + n);
}
public void print(String s) {
System.out.println("String: " + s);
}
Эти два метода называются перегруженными, так как имеют одно и то же имя print, но принимают разные типы параметров (целое число int и строку String соответственно).
715. Могут ли нестатические методы перегрузить статические?
Нет, нестатические методы не могут перегрузить статические методы в Java. Это связано с тем, что статические методы связаны с классом, в то время как нестатические методы связаны с экземпляром класса. При вызове метода Java использует сигнатуру метода, которая определяется именем метода и типами его параметров. Компилятор Java разрешает перегрузку методов на основе сигнатуры метода, и нестатический метод с той же сигнатурой, что и статический метод, будет рассматриваться как перегрузка, а не как переопределение.
716. Расскажите про переопределение методов.
В Java переопределение методов позволяет определить реализацию метода в подклассе, которая может отличаться от реализации метода в суперклассе. Чтобы переопределить метод в подклассе, нужно использовать аннотацию @Override и написать реализацию метода с тем же именем и типами параметров. Например, если у нас есть класс Animal с методом move(), мы можем переопределить метод в классе Dog следующим образом:
class Animal {
public void move() {
System.out.println("Moving...");
}
}
class Dog extends Animal {
@Override
public void move() {
System.out.println("Running...");
}
}
В этом примере мы переопределили метод move() в классе Dog, чтобы он выводил "Running..." вместо "Moving...". При вызове метода move() для объекта класса Dog будет вызываться его переопределенная реализация.
Переопределение методов является важным механизмом объектно-ориентированного программирования, так как позволяет методам работать по-разному в разных классах, но сохраняет общий интерфейс для пользователей этих классов.
717. Может ли метод принимать разное количество параметров (аргументы переменной длины)?
Да, в Java метод может принимать разное количество параметров, используя аргументы переменной длины. В Java это достигается с помощью синтаксиса ... после типа параметра. Это означает, что метод может принимать любое количество аргументов указанного типа. Вот простой пример метода, который принимает аргументы переменной длины типа int:
public void printNumbers(int... numbers) {
for (int number : numbers) {
System.out.println(number);
}
}
Этот метод может быть вызван с любым количеством параметров типа int:
printNumbers(1);
printNumbers(1, 2, 3);
printNumbers(new int[]{1, 2, 3});
Во всех трех случаях метод будет работать правильно, выводя переданные ему числа.
718. Можно ли сузить уровень доступа/тип возвращаемого значения при переопределении метода?
Да, в Java можно сузить уровень доступа и тип возвращаемого значения при переопределении метода. Любой метод может быть сузен до уровня доступа, ниже чем у его базового метода. Кроме того, тип возвращаемого значения может быть сузен до любого подтипа типа возвращаемого значения базового метода.
Например, если есть класс Animal с методом makeSound возвращающим тип Object, и подкласс Cat переопределяет метод makeSound, то можно сузить тип возвращаемого значения до String, как показано в примере ниже:
class Animal {
public Object makeSound() {
return "Some sound";
}
}
class Cat extends Animal {
@Override
public String makeSound() {
return "Meow";
}
}
В этом примере переопределенный метод makeSound унаследован от Animal, но тип возвращаемого значения был изменен с Object до String. Теперь для объектов типа Cat метод makeSound возвращает строку "Meow", в то время как для объектов типа Animal, makeSound возвращает объект типа Object.
719. Как получить доступ к переопределенным методам родительского класса?
Для доступа к переопределенным методам родительского класса в Java можно использовать ключевое слово super. super позволяет обратиться к методам и полям суперкласса из подкласса.
Например, если у нас есть класс-родитель ParentClass и класс-потомок ChildClass, который переопределяет метод someMethod() из класса-родителя, то можно вызвать версию метода из суперкласса следующим образом:
public class ParentClass {
public void someMethod() {
System.out.println("Hello from ParentClass");
}
}
public class ChildClass extends ParentClass {
@Override
public void someMethod() {
super.someMethod(); // вызываем метод из суперкласса
System.out.println("Hello from ChildClass");
}
}
// вызываем метод из класса-потомка
ChildClass child = new ChildClass();
child.someMethod();
В данном примере при вызове метода someMethod() из объекта класса ChildClass будет сначала вызвана версия метода из суперкласса ParentClass, а затем из класса ChildClass.
Ключевое слово super также может использоваться для доступа к конструктору суперкласса из конструктора подкласса:
public class ChildClass extends ParentClass {
public ChildClass() {
super(); // вызываем конструктор суперкласса
// ...
}
}
// создаем объект класса-потомка
ChildClass child = new ChildClass();
Этот код вызовет конструктор суперкласса ParentClass при создании объекта класса-потомка ChildClass.
720. Какие преобразования называются нисходящими и восходящими?
Преобразование от потомка к предку называется восходящим, от предка к потомку — нисходящим.
Нисходящее преобразование должно указываться явно с помощью указания нового типа в скобках.
Преобразование типов в Java может быть либо нисходящим (downcasting), либо восходящим (upcasting).
Нисходящее преобразование происходит, когда объект класса преобразуется в объект класса-наследника. Например:
Animal animal = new Cat(); // upcasting, преобразуем объект класса Cat в объект класса Animal
Cat cat = (Cat) animal; // downcasting, преобразуем объект класса Animal обратно в объект класса Cat
Восходящее преобразование происходит, когда объект класса-наследника преобразуется в объект класса-родителя. Например:
Cat cat = new Cat(); // создаем объект класса Cat
Animal animal = cat; // upcasting, преобразуем объект класса Cat в объект класса Animal
Во время нисходящего преобразования необходимо явное приведение типа, т.к. объект класса-наследника содержит дополнительные методы и поля, которых нет в родительском классе. Поэтому перед использованием этих методов и полей необходимо преобразовать объект к типу класса-наследника.
721. Чем отличается переопределение от перегрузки?
Переопределение (override) и перезагрузка (overloading) - это два понятия в объектно-ориентированном программировании, которые описывают способы использования методов в наследовании классов.
Переопределение (override) - это процесс изменения или замены реализации метода, унаследованного от базового класса, в производном классе. То есть, производный класс предоставляет свою собственную реализацию метода, который уже определен в базовом классе.
Например:
class MyBaseClass {
public void printMessage() {
System.out.println("Hello, world!");
}
}
class MyDerivedClass extends MyBaseClass {
@Override
public void printMessage() {
System.out.println("Hi there!");
}
}
Здесь метод printMessage() переопределяется в производном классе MyDerivedClass. Вызов этого метода на объекте MyDerivedClass приведет к выводу "Hi there!" вместо "Hello, world!", которые выводятся при вызове на объекте MyBaseClass.
Перегрузка (overloading) - это процесс создания нескольких методов с одним именем, но разными параметрами, внутри одного класса. В этом случае, каждая версия метода может иметь свою собственную реализацию.
Например:
class MyMathClass {
public int add(int a, int b) {
return a + b;
}
public double add(double a, double b) {
return a + b;
}
}
Здесь класс MyMathClass имеет два метода с именем add(), но каждый принимает разные типы параметров. Это называется перегрузкой метода. Вызов метода add() на объекте класса MyMathClass с целочисленными аргументами
722. Где можно инициализировать статические/нестатические поля?
723. Зачем нужен оператор instanceof?
Оператор instanceof в Java используется для проверки, является ли объект экземпляром определенного класса, интерфейса или подкласса любого класса. Например, если у вас есть объект obj и вы хотите проверить, является ли он экземпляром класса MyClass, вы можете написать следующий код:
if (obj instanceof MyClass) {
// do something
}
Это можно использовать для проверки типов во время выполнения и для принятия решений на основе этой информации. Например, вы можете использовать instanceof для проверки типа объекта и затем вызывать определенный метод в зависимости от типа:
if (obj instanceof MyClass) {
((MyClass)obj).myMethod();
} else if (obj instanceof MyOtherClass) {
((MyOtherClass)obj).myOtherMethod();
}
Это избавляет вас от необходимости использовать множественные условные операторы if и else или switch-case конструкции, особенно если у вас есть множество типов объектов, которые необходимо проверить на равенство.
724. Зачем нужны и какие бывают блоки инициализации?
Блоки инициализации в Java - это блоки кода, которые выполняются при инициализации класса или экземпляра класса. Они используются для выполнения определенных задач, таких как инициализация переменных, установка соединения с базой данных и т.д.
В Java есть два типа блоков инициализации: Статический блок инициализации и блок инициализации экземпляра.
Статический блок инициализации выполняется при загрузке класса, а блок инициализации экземпляра выполняется при создании экземпляра класса.
Пример статического блока инициализации:
public class MyClass {
static {
// код, который выполнится при загрузке класса
}
}
Пример блока инициализации экземпляра:
public class MyClass {
{
// код, который выполнится при создании экземпляра класса
}
}
Блоки инициализации позволяют упростить инициализацию объектов и добавить дополнительную логику при их создании.
725. Каков порядок вызова конструкторов и блоков инициализации двух классов: потомка и его предка?
В Java конструкторы и блоки инициализации вызываются в определенном порядке при создании объекта. Для класса-потомка порядок вызова конструкторов и блоков инициализации следующий:
-
Сначала вызывается статический блок инициализации класса-родителя (если он есть).
-
Затем вызывается конструктор класса-родителя.
-
Выполняются блоки инициализации экземпляра класса-родителя (обычный блок инициализации, блок инициализации инстанса и блок инициализации final-полей).
-
Вызывается статический блок инициализации класса-потомка (если он есть).
-
Затем вызывается конструктор класса-потомка.
-
Выполняются блоки инициализации экземпляра класса-потомка (обычный блок инициализации, блок инициализации инстанса и блок инициализации final-полей).
Например, если у вас есть класс-родитель Parent и класс-потомок Child, то порядок вызова конструкторов и блоков инициализации будет следующим:
class Parent {
static {
System.out.println("Static init block in Parent");
}
{
System.out.println("Instance init block in Parent");
}
public Parent() {
System.out.println("Constructor in Parent");
}
}
class Child extends Parent {
static {
System.out.println("Static init block in Child");
}
{
System.out.println("Instance init block in Child");
}
public Child() {
System.out.println("Constructor in Child");
}
}
// Создаем объект класса Child
Child child = new Child();
Этот код выведет следующий результат в консоль:
Static init block in Parent
Constructor in Parent
Instance init block in Parent
Static init block in Child
Constructor in Child
726. Где и для чего используется модификатор abstract?
Модификатор abstract используется в Java, чтобы указать, что метод или класс не имеют реализации в данном классе и должны быть реализованы в подклассе.
Абстрактные классы используются, когда нужно создать класс, но необходимо, чтобы дочерние классы добавили свои уникальные свойства или методы. Абстрактные классы могут содержать абстрактные методы, которые не имеют реализации, и дочерние классы должны реализовать эти методы.
Абстрактные методы могут быть определены только в абстрактных классах, и они не имеют тела (реализации). Дочерние классы должны предоставить реализацию абстрактных методов, иначе они также должны быть определены как абстрактные классы.
Например, следующий код демонстрирует абстрактный класс Animal, который содержит абстрактный метод makeSound(). Класс Cow расширяет абстрактный класс Animal и предоставляет реализацию метода makeSound():
abstract class Animal {
public abstract void makeSound();
}
class Cow extends Animal {
public void makeSound() {
System.out.println("Moo");
}
}
727. Можно ли объявить метод абстрактным и статическим одновременно?
Нет, в Java нельзя объявить метод одновременно абстрактным и статическим, потому что такое объявление будет некорректным. Метод, объявленный статическим, принадлежит классу и может быть вызван без создания экземпляра класса, в то время как абстрактный метод не имеет тела и должен быть реализован в подклассах. Из-за этой разницы в семантике объединение этих двух модификаторов невозможно.
Пример некорректного объявления метода:
public abstract static void myMethod();
Этот код вызовет ошибку компиляции с сообщением "Illegal combination of modifiers: 'abstract' and 'static'".
Методы абстрактные, как правило, должны быть реализованы в подклассах, чтобы предоставить конкретную имплементацию, тогда как статические методы могут быть использованы для предоставления утилитарных функций, которые не зависят от состояния экземпляра.
728. Что означает ключевое слово static?
В Java ключевое слово static используется для создания переменных и методов, которые общие для всех экземпляров класса, а не относятся к конкретному экземпляру. Иными словами, переменная или метод, объявленные как static, могут быть использованы без создания экземпляра класса и доступны в рамках всего класса.
Static переменные хранятся в общей памяти и инициализируются при загрузке класса, а static методы могут быть вызваны напрямую через класс, не требуя создания экземпляра класса.
Например, если у вас есть класс Car с переменной numberOfWheels, которая должна иметь одно и то же значение для всех экземпляров класса, можно объявить эту переменную как static:
public class Car {
public static int numberOfWheels = 4;
// other class members here
}
Теперь значение переменной numberOfWheels будет общим для всех экземпляров класса Car.
Кроме того, вы можете объявлять static методы, которые будут доступны в рамках всего класса и не требуют создания экземпляра класса для вызова. Один из стандартных примеров - это метод main(), который используется для запуска Java-программ.
public class MyClass {
public static void main(String[] args) {
//code to be executed
}
}
Этот метод может быть вызван напрямую через класс MyClass, без необходимости создавать экземпляр этого класса.
В общем, static это механизм, позволяющий в Java создавать переменные и методы, которые общие для всего класса, а не для его экземпляров.
729. К каким конструкциям Java применим модификатор static?
Модификатор static в Java может быть применен к методам, полям и вложенным классам. Когда метод или поле объявлены как static, они принадлежат классу, а не экземпляру класса. Это означает, что они могут быть вызваны или использованы без создания экземпляра класса. Когда вложенный класс объявлен как static, он связан со своим внешним классом, но не зависит от создания экземпляра внешнего класса.
Пример использования модификатора static для поля и метода:
public class MyClass {
static int myStaticField = 42;
int myNonStaticField = 0;
static void myStaticMethod() {
System.out.println("This is a static method");
}
void myNonStaticMethod() {
System.out.println("This is a non-static method");
}
}
// Для доступа к статическому полю или методу, необходимо использовать имя класса
int val = MyClass.myStaticField;
MyClass.myStaticMethod();
730. Что будет, если в static блоке кода возникнет исключительная ситуация?
Если в блоке кода static возникнет исключительная ситуация, то при первом обращении к классу, в котором находится этот блок, JVM (среда выполнения Java) не будет выполнять блок кода static, и вместо этого выбросится исключение. Класс не будет инициализирован, и его статические переменные или методы не будут доступны до тех пор, пока блок кода static не будет выполнен успешно. Это может привести к проблемам, если статические переменные не инициализированы и используются в других частях кода, поэтому важно обрабатывать исключения в блоке static.
Например, в следующем примере при попытке инициализировать класс будет выброшено исключение NullPointerException:
public class MyClass {
static {
String s = null;
s.length(); // throws NullPointerException
}
}
731. Можно ли перегрузить static метод?
Да, в Java можно перегружать статические методы так же, как и нестатические методы. Однако в отличие от нестатических методов, где динамический полиморфизм решает, какая версия метода будет вызвана во время выполнения, перегруженный статический метод, который будет вызываться, решается во время компиляции, основываясь на типах параметров метода, переданных в него. Например:
public class MyClass {
public static void myMethod(int x) {
System.out.println("Method with int parameter: " + x);
}
public static void myMethod(String x) {
System.out.println("Method with String parameter: " + x);
}
}
Здесь мы определили два перегруженных статических метода myMethod, один с параметром типа int, а другой с параметром типа String.
Eще пример, представим класс с двумя перегруженными static методами:
public class MyClass {
public static void printMessage() {
System.out.println("Hello, world!");
}
public static void printMessage(String message) {
System.out.println(message);
}
}
В этом примере мы создали два перегруженных static метода printMessage, один без аргументов и второй с одним аргументом типа String. Эти методы можно вызвать следующим образом:
MyClass.printMessage(); // вызовет метод printMessage() без аргументов
MyClass.printMessage("Hi there"); // вызовет метод printMessage() с аргументом "Hi there"
Таким образом, перегрузка static методов предоставляет гибкость и удобство в программировании на Java, позволяя создавать методы с одним именем, но разными списками параметров.
732. Что такое статический класс, какие особенности его использования?
Статический класс в Java - это вложенный класс, который имеет модификатор доступа static. Это означает, что экземпляры статического класса не создаются вместе с экземплярами внешнего класса, а независимы от него и могут быть созданы самостоятельно. К классу высшего уровня модификатор static неприменим.
Особенности использования статического класса:
-
Статический класс может содержать только статические методы, поля, и другие статические классы.
-
В статическом классе нельзя использовать поля или методы внешнего класса (только если они тоже являются статическими).
-
К статическим методам и полям статического класса можно обращаться без создания экземпляра класса.
Например, вот как определить статический класс в Java:
public class OuterClass {
static class StaticNestedClass {
static int staticField;
static void staticMethod() {
// метод статического класса
}
}
}
К статическим полям и методам статического класса можно обращаться из других классов используя полный путь к классу, например:
OuterClass.StaticNestedClass.staticField = 42;
OuterClass.StaticNestedClass.staticMethod();
733. Какие особенности инициализации final static переменных?
В Java, final static переменные обычно инициализируются либо непосредственно при объявлении, либо в блоке статической инициализации класса. Обе эти опции гарантируют, что переменная будет инициализирована только один раз во время выполнения программы.
Примеры инициализации final static переменных:
- Непосредственная инициализация при объявлении:
public class MyClass {
public static final int MY_CONSTANT = 42;
}
- Инициализация в блоке статической инициализации класса:
public class MyClass {
public static final int MY_CONSTANT;
static {
MY_CONSTANT = 42;
}
}
- Комбинация непосредственной инициализации и статического блока инициализации:
public class MyClass {
public static final int MY_CONSTANT = 42;
static {
System.out.println("Initializing MyClass");
}
}
В любом случае, final static переменные должны быть инициализированы до того, как они будут использованы в программе. Кроме того, они не могут быть изменены после их инициализации.
734. Как влияет модификатор static на класс/метод/поле?
Модификатор static в Java влияет на класс, метод или поле, делая их доступными без создания экземпляра класса. Модификатор static в Java может быть применен к полям, методам и вложенным классам.
-
Когда применяется к полям, это означает, что это статическое поле относится к классу в целом, а не к конкретному экземпляру класса. Таким образом, все экземпляры класса будут иметь общее значение этого поля.
-
Когда применяется к методам, метод можно вызывать независимо от каких-либо экземпляров класса.
-
Когда применяется к вложенным классам, они могут быть созданы, даже если экземпляры внешнего класса не созданы.
Использование модификатора static позволяет существенно сократить использование памяти и повысить производительность вашей программы. Однако его следует использовать осторожно, так как это может затруднить тестирование и обнаружение ошибок.
- Статический метод: метод является статическим, если он принадлежит классу, а не экземпляру класса. Статический метод можно вызвать без создания экземпляра класса. Пример:
public class MyClass {
public static void myStaticMethod() {
System.out.println("Static method");
}
public void myPublicMethod() {
System.out.println("Public method");
}
}
MyClass.myStaticMethod(); // Call the static method
MyClass obj = new MyClass(); // Create an object of MyClass
obj.myPublicMethod(); // Call the public method
- Статическое поле класса: статическое поле принадлежит классу, а не экземпляру класса, и доступно без создания экземпляра класса. Пример:
public class MyClass {
public static String myStaticField = "Static field";
public String myPublicField = "Public field";
}
System.out.println(MyClass.myStaticField); // Output the static field
MyClass obj = new MyClass(); // Create an object of MyClass
System.out.println(obj.myPublicField); // Output the public field
- Статический блок инициализации: статический блок инициализации выполняется при загрузке класса и используется для инициализации статических полей. Пример:
public class MyClass {
static {
// Code to execute
}
}
Статические методы и поля не могут обращаться к нестатическим методам и полям без создания экземпляра класса. Если статический метод или поле ссылается на нестатический метод или поле, то необходимо создать экземпляр класса.
735. О чем говорит ключевое слово final?
Ключевое слово "final" в Java используется для обозначения неизменяемости значения переменной, метода или класса.
- Для переменных: если переменная объявлена с ключевым словом "final", это означает, что ее значение не может быть изменено после инициализации, то есть она становится константой. Например:
final int x = 5;
- Для методов: если метод объявлен с ключевым словом "final", его тело не может быть изменено в подклассах. Это может быть полезно в случае, если мы хотим, чтобы метод в подклассах оставался неизменным. Например:
public class MyClass {
final void myMethod() { /* тело метода */ }
}
- Для классов: если класс объявлен с ключевым словом "final", его нельзя наследовать. Таким образом, это означает, что мы не можем создавать подклассы для данного класса. Например:
final class MyClass { /* тело класса */ }
- Значение локальных переменных, а так же параметров метода помеченных при помощи слова final не могут быть изменены после присвоения
Использование ключевого слова "final" может повысить производительность и обеспечить более безопасный код в некоторых ситуациях, когда мы хотим гарантировать неизменность значения или поведения переменной, метода или класса.
736. Дайте определение понятию “интерфейс”.
В Java интерфейс - это абстрактный класс, который содержит только абстрактные методы (методы без тела), и константы. Интерфейс позволяет определить конкретный комплект методов, которые должен реализовывать любой класс, который реализует этот интерфейс. Интерфейс может определять методы, аргументы для методов и возвращаемые значения, но он не предоставляет реализации для этих методов. Вместо этого реализация предоставляется классами, которые реализуют интерфейс.
Для объявления интерфейса в Java используется ключевое слово interface. Затем определяются методы, которые должны быть реализованы в классе, который реализует интерфейс. Класс может реализовать несколько интерфейсов, что позволяет ему наследовать поведение нескольких интерфейсов.
Пример интерфейса в Java:
public interface MyInterface {
public void doSomething();
public int getNumber();
}
Класс, который реализует интерфейс, должен реализовать все его методы, например:
public class MyClass implements MyInterface {
public void doSomething() {
System.out.println("Doing something");
}
public int getNumber() {
return 42;
}
}
Теперь объект класса MyClass можно использовать, где ожидается объект типа MyInterface.
737. Какие модификаторы по умолчанию имеют поля и методы интерфейсов?
Поля и методы интерфейсов в Java по умолчанию имеют модификаторы public и abstract, соответственно. Если в интерфейсе определяется метод, но не указывается модификатор доступа, то он автоматически считается public и abstract.
Интерфейс может содержать поля, но они автоматически являются статическими (static) и неизменными (final). Все методы и переменные неявно объявляются как public.
Начиная с Java 8, интерфейсы могут также иметь методы по умолчанию (default methods), которые имеют реализации по умолчанию и могут быть переопределены в классах, реализующих интерфейс.
Нововведением Java 9 стало добавление приватных методов и приватных статических методов в интерфейсы, которые могут использоваться для того, чтобы скрыть детали реализации и облегчить повторное использование кода.
Например, интерфейс с одним методом может выглядеть так:
public interface MyInterface {
void myMethod();
default void myDefaultMethod() {
System.out.println("Default implementation of myDefaultMethod()");
}
private void myPrivateMethod() {
System.out.println("Private implementation of myPrivateMethod()");
}
private static void myPrivateStaticMethod() {
System.out.println("Private static implementation of myPrivateStaticMethod()");
}
}
738. Почему нельзя объявить метод интерфейса с модификатором final или static
В Java нельзя объявить метод в интерфейсе с модификатором final или static, потому что все методы в интерфейсе считаются неявно абстрактными и public, и поэтому они не могут быть статическими или final, так как это нарушает их природу абстракции. Static методы могут быть только в статических классах, а final методы можно объявить только в классах и не имеет смысла в интерфейсе, где не реализуются методы. Вместо этого вы можете объявить константы в интерфейсе с модификаторами static и final:
public interface MyInterface {
int MY_CONSTANT = 100; // объявление константы
}
Но если вы хотите иметь какой-то общий функционал для всех реализующих интерфейс классов, вы можете использовать статический метод или метод по умолчанию, объявленный в интерфейсе:
public interface MyInterface {
static void myStaticMethod() {
System.out.println("This is a static method in the interface.");
}
default void myDefaultMethod() {
System.out.println("This is a default method in the interface.");
}
}
class MyClass implements MyInterface {
public static void main(String[] args) {
MyInterface.myStaticMethod();
MyClass obj = new MyClass();
obj.myDefaultMethod();
}
}
Это позволит вам вызывать методы в интерфейсе без создания экземпляра класса, а также предоставлять реализацию методов по умолчанию для всех реализующих интерфейс классов.
739. Какие типы классов бывают в java (вложенные… и.т.д.)
В Java есть несколько типов вложенных (nested) классов:
-
Внутренние (Inner) классы: это классы, которые объявлены внутри другого класса и имеют доступ к его полям и методам, даже к приватным. Внутренние классы могут быть объявлены как статическими или нестатическими.Есть возможность обращения к внутренним полям и методам класса обертки. Не может иметь статических объявлений. Нельзя объявить таким образом интерфейс. А если его объявить без идентификатора static, то он автоматически будет добавлен.Внутри такого класса нельзя объявить перечисления.Если нужно явно получить this внешнего класса — OuterClass.this -
Вложенные (Nested) классы: это классы, которые объявлены внутри другого класса, но не имеют доступа к его полям и методам. Вложенные классы могут быть объявлены как статическими или нестатическими. -
Локальные (Local) классы: это классы, которые объявлены внутри метода или блока кода и имеют доступ к переменным и параметрам этого метода или блока кода.Видны только в пределах блока, в котором объявлены. Не могут быть объявлены как private/public/protected или static (по этой причине интерфейсы нельзя объявить локально). Не могут иметь внутри себя статических объявлений (полей, методов, классов). Имеют доступ к полям и методам обрамляющего класса. Можно обращаться к локальным переменным и параметрам метода, если они объявлены с модификатором final. -
Анонимные (Anonymous) классы: это классы, которые не имеют имени и создаются "на лету" при создании объекта интерфейса или абстрактного класса. Они используются, когда требуется реализовать какой-то метод "на месте". -
Статические (Static) классы: это вложенные классы, которые объявлены как статические и не имеют доступа к нестатическим полям и методам внешнего класса. Они обычно используются для группировки связанных сущностей в рамках одного пакета или модуля. Есть возможность обращения к внутренним статическим полям и методам класса обертки. Внутренние статические классы могут содержать только статические методы. -
Обычные классы (Top level classes) -
Интерфейсы (Interfaces) -
Перечисления (Enum)
740. Какие особенности создания вложенных классов: простых и статических.
В Java есть два основных типа вложенных классов: внутренние классы (inner classes) и статические вложенные классы (static nested classes).
Внутренние классы - это классы, объявленные внутри другого класса без использования модификатора static. Такие классы имеют доступ к членам внешнего класса, включая приватные поля и методы, и могут использоваться для создания более читаемого и логически законченного кода.
Статические вложенные классы - это классы, объявленные внутри другого класса с использованием модификатора static. Эти классы не имеют доступа к членам внешнего класса и используются для логической группировки классов и для создания пространства имен.
Пример создания статического вложенного класса:
public class OuterClass {
// Код внешнего класса
public static class InnerStaticClass {
// Код статического вложенного класса
}
}
Пример создания внутреннего класса:
public class OuterClass {
// Код внешнего класса
public class InnerClass {
// Код внутреннего класса
}
}
Обратите внимание, что внутренний класс может быть создан только в контексте экземпляра внешнего класса, тогда как статический вложенный класс может быть создан без создания экземпляра внешнего класса.
741. Что вы знаете о вложенных классах, зачем они используются? Классификация, варианты использования, о нарушении инкапсуляции.
В Java вложенные классы делятся на статические и внутренние (inner classes).
Статические вложенные классы (static nested classes) - это классы, которые являются членами внешнего класса, но при этом не имеют доступа к нестатическим членам внешнего класса. Они часто используются для логической группировки классов внутри другого класса.
Внутренние классы (inner classes) - это классы, которые объявлены внутри другого класса и имеют доступ к членам и методам внешнего класса, даже если они объявлены как private. Внутренние классы могут быть обычными (обычно объявляются как private) и анонимными (не имеют имени и используются для реализации интерфейсов или абстрактных классов).
Внутренние классы могут быть полезны для реализации определенных паттернов проектирования, таких как фабрики и стратегии. Они также позволяют улучшить читабельность кода и уменьшить объем повторяющегося кода.
Однако, использование внутренних классов может нарушать инкапсуляцию и затруднять чтение и понимание кода, поэтому их использование следует ограничивать только в тех случаях, где это действительно необходимо.
742. В чем разница вложенных и внутренних классов?
В Java вложенные классы (nested classes) могут быть статическими или нестатическими. Статические вложенные классы используются, когда класс находится внутри другого класса, но не зависит от экземпляра внешнего класса. Нестатические вложенные классы (inner classes), также известные как внутренние классы, наоборот, зависят от экземпляра внешнего класса.
Объявление нестатического внутреннего класса происходит с использованием ключевого слова 'class' внутри тела внешнего класса. Вот пример:
class OuterClass {
private int x;
class InnerClass {
public int getX() {
return x;
}
}
}
Объявление статического вложенного класса выглядит следующим образом:
class OuterClass {
static class NestedClass {
// Код класса
}
}
Различия между вложенными и внутренними классами заключаются в том, что внутренние классы имеют доступ к полям и методам экземпляра внешнего класса, в то время как вложенные классы не имеют такого доступа. Внутренние классы также могут быть созданы только в контексте экземпляра внешнего класса, в то время как статические вложенные классы могут быть созданы вне контекста экземпляра внешнего класса.
743. Какие классы называются анонимными?
Анонимный класс - это класс, который объявлен без имени внутри другого класса или метода, и который реализует либо наследует какой-то интерфейс.
В Java классы, которые не имеют имени, называются анонимными классами. Они используются для создания одиночных объектов с определенным поведением, которые обычно не нуждаются в создании отдельного класса. Анонимный класс объявляется и создается в одной строке кода, обычно в качестве аргумента для метода или конструктора. Вот пример:
interface MyInterface {
void doSomething ();
}
MyInterface myObject = new MyInterface () {
public void doSomething () {
System.out.println ("I am doing something.");
}
};
Здесь мы объявляем интерфейс MyInterface с единственным методом doSomething(), а затем создаем анонимный класс, который реализует этот метод и создает объект типа MyInterface. Этот объект присваивается переменной myObject. Когда myObject.doSomething() вызывается, на экране появляется "I am doing something."
744. Каким образом из вложенного класса получить доступ к полю внешнего класса?
Для получения доступа к полю внешнего класса из вложенного класса в Java можно использовать ключевое слово this с именем внешнего класса и оператором точки, например: OuterClass.this.outerField. Вот пример кода:
public class OuterClass {
private int outerField;
public class InnerClass {
public void accessOuterField() {
int fieldValue = OuterClass.this.outerField;
// do something with the fieldValue
}
}
}
Здесь InnerClass является вложенным классом в OuterClass, и метод accessOuterField() использует this.outerField для доступа к полю outerField внешнего класса OuterClass.
745. Каким образом можно обратиться к локальной переменной метода из анонимного класса, объявленного в теле этого метода? Есть ли какие-нибудь ограничения для такой переменной?
Для доступа к локальной переменной метода из анонимного класса, объявленного в теле этого метода в Java, её следует сделать final. Это необходимо, чтобы гарантировать, что значение переменной не будет изменено после создания анонимного класса. Для получения доступа к переменной в анонимном классе, можно обратиться к ней по имени, как это делается в лямбда-выражениях. Например:
public void someMethod() {
final int localVar = 42;
// Создание анонимного класса
Runnable r = new Runnable() {
public void run() {
System.out.println(localVar); // Доступ к локальной переменной
}
};
r.run();
}
Это позволит получить доступ к localVar внутри анонимного класса. Важно отметить, что локальные переменные, объявленные внутри статических методов, не могут быть делегированы анонимным классам, так как эти переменные не находятся на стеке вызовов.
Также стоит заметить, что начиная с Java 8, можно использовать локальные переменные метода в лямбда-выражениях без явного объявления как final.
746. Как связан любой пользовательский класс с классом Object?
В Java все классы являются подклассами класса Object. Это означает, что любой пользовательский класс, который вы определяете в Java, автоматически наследуется от класса Object. Это также означает, что вы можете использовать методы класса Object, такие как toString(), equals(), hashCode(), и другие, для любого вашего пользовательского класса.
Например, если у вас есть класс Person, вот как можно переопределить метод toString() класса Object для этого класса:
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// override the toString() method to print out the person's name and age
@Override
public String toString() {
return "Person{name='" + name + "', age=" + age + "}";
}
}
Благодаря наследованию, вы можете использовать этот код для создания объекта класса Person, вызова его метода toString() и присваивания этот результат переменной типа Object:
Person p = new Person("John Doe", 30);
Object o = p;
System.out.println(o.toString()); // выводит: Person{name='John Doe', age=30}
Таким образом, любой пользовательский класс в Java неявно связан с классом Object посредством наследования.
747. Расскажите про каждый из методов класса Object.
Класс Object является базовым классом для всех классов в Java. Он определяет ряд методов, которые наследуются всеми классами. Эти методы включаю (8):
-
equals()- определяет, равен ли данный объект другому объекту. Возвращает true если объекты равны, false если они не равны. -
hashCode()- возвращает хеш-код объекта. -
toString()- возвращает строковое представление объекта. -
getClass()- возвращает класс объекта. -
wait()- заставляет текущий поток ждать до тех пор, пока другой поток не выполнит определенное действие. -
notify()- возобновляет выполнение потока, остановленного методом wait(). -
notifyAll()- возобновляет выполнение всех потоков, остановленных методом wait() на текущем объекте. -
finalize()- вызывается сборщиком мусора при удалении объекта.
Данные методы могут быть переопределены в производных классах, но, как правило, это не рекомендуется, так как они выполняют важные функции и их неправильная реализация может привести к ошибкам в программе.
748. Что такое метод equals(). Чем он отличается от операции ==.
В Java метод equals() используется для сравнения содержимого объектов, тогда как операция == сравнивает ссылки на объекты. Когда вы используете операцию == с объектами, она проверяет, указывает ли каждая ссылка на один и тот же объект в памяти, в то время как метод equals() сравнивает содержимое объектов, чтобы узнать, являются ли они эквивалентными. В большинстве случаев операция == используется для примитивных типов данных, таких как int, boolean, char, а метод equals() используется для объектов и ссылочных типов данных, таких как String, Date и других.
Вот пример использования метода equals() на объекте String:
String str1 = "Hello";
String str2 = "Hello";
if(str1.equals(str2)) {
System.out.println("Strings are equal");
} else {
System.out.println("Strings are not equal");
}
В данном примере метод equals() сравнивает содержимое двух строк str1 и str2, и выводит сообщение "Strings are equal", потому что содержимое обеих строк эквивалентно. Если бы мы использовали операцию == вместо метода equals(), она бы вернула false, потому что ссылки обеих строк указывают на разные объекты в памяти.
749. Если вы хотите переопределить equals(), какие условия должны удовлетворяться для переопределенного метода?
Если вы хотите переопределить метод equals() в Java, важно понимать, что этот метод используется для сравнения двух объектов на равенство. Для того, чтобы ваш переопределенный метод equals() работал должным образом, он должен удовлетворять определенным условиям:
-
Рефлексивность: Объект всегда должен быть равен самому себе. То есть, a.equals(a) должен всегда возвращать true. -
Симметричность: Если объект a равен объекту b, то b также должен быть равен a. То есть, если a.equals(b) возвращает true, то b.equals(a) должен также возвращать true. -
Транзитивность: Если объекты a, b и c равны между собой (a.equals(b) возвращает true, b.equals(c) возвращает true), то объект a также должен быть равен объекту c (a.equals(c) должен возвращать true). -
Непротиворечивость: Если вы сравниваете два объекта в разное время, и их состояние не изменялось, результатом должно быть одно и то же. То есть, повторный вызов метода equals() для двух одинаковых объектов должен всегда возвращать true. -
Сравнение с null: Метод equals() должен возвращать false, если объект, с которым сравнивается, равен null. -
Рефлексивность: a.equals(a) должен возвращать true.
-
Симметричность: a.equals(b) должен возвращать true тогда и только тогда, когда b.equals(a) возвращает true.
-
Транзитивность: если a.equals(b) возвращает true и b.equals(c) возвращает true, то и a.equals(c) должен возвращать true.
-
Согласованность: если a и b не изменяются, то многократные вызовы a.equals(b) должны последовательно возвращать true или false.
-
Не равен null: a.equals(null) должен возвращать false.
Например, для класса "Person" переопределение метода может выглядеть так:
class Person {
private String name;
private int age;
// Конструктор и геттеры/сеттеры
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof Person)) {
return false;
}
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
Обратите внимание, что вместе с методом equals() нужно переопределить метод hashCode() для обеспечения согласованности и корректной работы хэш-коллекций.
750. Если equals() переопределен, есть ли какие-либо другие методы, которые следует переопределить?
Если метод equals() переопределен в классе Java, то обычно также следует переопределить метод hashCode(). Это связано с тем, что hashCode() используется вместе с equals() при работе с хеш-таблицами и другими коллекциями, которые хранят элементы на основании их хеш-кодов. Если equals() переопределен, а hashCode() - нет, то могут возникнуть проблемы с поиском и удалением элементов в коллекциях.
Вот пример переопределения этих методов для класса Person:
public class Person {
private String name;
private int age;
// constructor, getter and setter methods...
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
Здесь метод equals() сравнивает имя и возраст двух объектов класса Person, а метод hashCode() использует имя и возраст для вычисления их хеш-кода.
751. В чем особенность работы методов hashCode и equals?
В Java метод equals используется для сравнения двух объектов на равенство, в то время как метод hashCode возвращает целочисленный хэш-код объекта.
hashCode используется во многих коллекциях Java (например, HashMap, HashSet и т.д.), чтобы определить расположение объекта в хранилище. Он должен быть реализован таким образом, чтобы каждый объект имел уникальный хэш-код, если это возможно.
equals должен быть переопределен в классе, если мы хотим сравнивать не ссылки на объекты, а их содержимое. При переопределении метода equals также должен быть переопределен метод hashCode таким образом, чтобы объекты, которые равны по содержимому, имели одинаковый хэш-код.
Кроме того, для корректной работы метода equals необходимо соблюдать ряд требований, таких как рефлексивность, транзитивность, симметричность и консистентность.
В целом, для правильной работы многих стандартных классов и интерфейсов Java, таких как коллекции, необходимо корректно реализовать методы hashCode и equals в своих классах.
752. Каким образом реализованы методы hashCode и equals в классе Object?
В Java, класс Object является базовым классом для всех объектов и имеет два метода, hashCode() и equals().
Метод hashCode() возвращает целочисленный хеш-код объекта. Хеш-код обычно используется для уникальной идентификации объекта в коллекциях, таких как HashSet и HashMap. Этот метод должен быть реализован вместе с методом equals(), чтобы обеспечить согласованность между ними.
Метод equals() используется для сравнения объектов на равенство. Он возвращает булево значение true, если объекты равны, и false в противном случае. Этот метод также должен быть реализован вместе с методом hashCode(), чтобы обеспечить согласованность между ними.
Код equals() должен быть рефлексивным, симметричным, транзитивным и консистентным. Код hashCode() должен возвращать одинаковый хеш-код для равных объектов.
753. Какие правила и соглашения существуют для реализации этих методов? Когда они применяются?
В Java методы hashCode() и equals() используются для сравнения объектов и поиска элементов в коллекциях. Эти методы должны быть реализованы с определенным набором правил.
Правила hashCode():
-
Если метод equals() возвращает true для двух объектов, то hashCode() для этих объектов должен возвращать одно и то же значение.
-
Если метод equals() возвращает false для двух объектов, то hashCode() для этих объектов может возвращать одно и то же значение, но это не обязательно.
Правила equals():
-
Рефлексивность: Метод equals() должен возвращать true для объекта идентичного самому себе (a.equals(a)).
-
Cимметричность: Если a.equals(b) возвращает true, то b.equals(a) также должен возвращать true.
-
Транзитивность: Если a.equals(b) возвращает true и b.equals(c) возвращает true, то a.equals(c) также должен возвращать true.
-
Консистентность: Если объекты a и b не меняются, то результат a.equals(b) должен оставаться неизменным.
-
Неравенство: a.equals(null) должен возвращать false, а не вызывать исключение.
Эти правила делают возможным корректное сравнение объектов и применение их в различных структурах данных, таких как HashSet или HashMap.
При реализации hashCode() и equals() важно учитывать не только значения полей объекта, но и его реальную сущность и состояние. Также следует позаботиться о реализации hashCode() и equals() во всех классах, который будут использоваться в качестве ключей в HashMap или HashSet, так как это позволит корректно их использовать в Java.
Хеш-код — это число. Если более точно, то это битовая строка фиксированной длины, полученная из массива произвольной длины. В терминах Java, хеш-код — это целочисленный результат работы метода, которому в качестве входного параметра передан объект.
Этот метод реализован таким образом, что для одного и того же входного объекта, хеш-код всегда будет одинаковым. Следует понимать, что множество возможных хеш-кодов ограничено примитивным типом int, а множество объектов ограничено только нашей фантазией. Отсюда следует утверждение: “Множество объектов мощнее множества хеш-кодов”. Из-за этого ограничения, вполне возможна ситуация, что хеш-коды разных объектов могут совпасть.
Здесь главное понять, что:
- Если хеш-коды разные, то и входные объекты гарантированно разные.
- Если хеш-коды равны, то входные объекты не всегда равны.
Ситуация, когда у разных объектов одинаковые хеш-коды называется — коллизией. Вероятность возникновения коллизии зависит от используемого алгоритма генерации хеш-кода.
754. Какой метод возвращает строковое представление объекта?
Метод toString() возвращает строковое представление объекта в Java. Каждый объект в Java имеет реализацию метода toString(), которая по умолчанию возвращает строку, содержащую имя класса и хэш-код объекта. Метод toString() может быть переопределен для любого класса, чтобы возвращать нужное строковое представление объекта, например, свойства объекта.
Например, для получения текстового представления числа 42, нужно создать объект Integer и вызвать метод toString() следующим образом:
Integer myInt = 42;
String intStr = myInt.toString();
System.out.println(intStr); // выводит "42" на консоль
Альтернативной короткой записью может быть:
System.out.println(Integer.toString(42));
Некоторые классы в стандартной библиотеке Java переопределяют метод toString() для возврата более информативных описаний объекта. Например, toString() для класса Date возвращает дату и время в определенном формате.
Ниже пример с созданием объекта и его выводом в консоль:
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{name='" + name + "', age=" + age + "}";
}
}
Person person = new Person("John", 30);
System.out.println(person.toString()); // выводит "Person{name='John', age=30}"
755. Что будет, если переопределить equals не переопределяя hashCode? Какие могут возникнуть проблемы?
В Java, если вы переопределяете метод equals(), вы также должны переопределить метод hashCode(). Это связано с тем, что объекты, реализующие метод equals(), могут использоваться в качестве ключей в хеш-таблицах. При этом вычисление индекса в хеш-таблице осуществляется с помощью метода hashCode(), и если hashCode() не переопределен, то объект может получить неправильный индекс в хеш-таблице или привести к коллизиям.
Таким образом, если переопределить equals() без переопределения hashCode(), то созданные объекты могут работать неправильно в хеш-таблицах и коллекциях, использующих хеш-коды, включая HashMap, HashSet и Hashtable. Поэтому, если вы переопределяете метод equals(), убедитесь, что переопределяете и метод hashCode().
756. Есть ли какие-либо рекомендации о том, какие поля следует использовать при подсчете hashCode?
Метод hashCode() в Java используется для получения хэш-кода объекта. Хэш-код обычно представляет собой целочисленное значение, которое используется для идентификации объектов в хеш-таблице. Как правило, нет необходимости переопределять метод hashCode(), но если вы это сделаете, следуйте некоторым рекомендациям.
Одна из рекомендаций состоит в том, что вы должны использовать те же поля для вычисления хэш-кода, которые вы используете для проверки на равенство в методе equals(). Это означает, что если два объекта равны согласно методу equals(), они должны иметь одинаковый хэш-код. Кроме того, обычно рекомендуется рассчитывать хэш-код только на основе значений неизменяемых полей, чтобы гарантировать, что хэш-код не изменится после создания объекта.
Вот пример того, как вы можете переопределить метод hashCode() для простого класса Person с двумя полями, именем и возрастом:
class Person {
private final String name;
private final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
// ...
}
В этом примере мы используем метод Objects.hash(), представленный в Java 7, для вычисления хэш-кода на основе полей имени и возраста. Метод Objects.hash() принимает любое количество аргументов и возвращает хэш-код на основе их значений.
Важно отметить, что даже если хэш-код рассчитан неправильно, код все равно скомпилируется и запустится, но хеш-таблица может работать неправильно, что приведет к ошибкам, которые трудно отлаживать.
757. Как вы думаете, будут ли какие-то проблемы, если у объекта, который используется в качестве ключа в hashMap изменится поле, которое участвует в определении hashCode?
Да, могут возникнуть проблемы при изменении поля ключа объекта, который используется в HashMap. HashMap использует метод hashCode() ключа для определения индекса внутреннего массива, где хранятся значения. Если изменить поле ключа объекта, которое участвует в определении значения hashCode() метода, то это может привести к тому, что ключ не будет найден в HashMap, даже если он должен быть там находиться.
Чтобы избежать таких проблем, необходимо использовать неизменяемые ключи объектов в HashMap, например, String или примитивные типы данных. Если же вы используете свой класс в качестве ключа, то убедитесь, что вы правильно переопределили методы hashCode() и equals() для вашего класса, чтобы они работали корректно при изменении значений полей.
758. Чем отличается абстрактный класс от интерфейса, в каких случаях что вы будете использовать?
Абстрактные классы и интерфейсы являются двумя различными механизмами для моделирования полиморфизма в Java.
Абстрактные классы:
-
Они могут содержать как абстрактные, так и конкретные методы.
-
Абстрактный класс может содержать переменные экземпляра.
-
Абстрактный класс может быть расширен подклассом, который может реализовать все абстрактные методы в нем.
-
Абстрактный класс не может быть инициализирован.
-
Абстрактный класс является чем-то похожим на класс-шаблон, который могут использовать подклассы.
Интерфейсы:
-
Они могут содержать только абстрактные методы и константы.
-
Интерфейсы не могут содержать переменные экземпляра.
-
Подкласс может реализовать один или несколько интерфейсов.
-
Интерфейсы могут быть множественно реализованы.
-
Интерфейс является спецификацией того, что должен делать класс, но не как это делать.
Использование одного или другого зависит от конкретной задачи, но в целом интерфейсы удобнее тем, что они не создают иерархию наследования классов и не связывают подклассы с реализацией конкретных методов. Если вы хотите определить только поведение, которое классы должны реализовать, лучше использовать интерфейсы. Если вы хотите определять общие свойства, используйте абстрактные классы.
759. Можно ли получить доступ к private переменным класса и если да, то каким образом?
Да, это возможно, но только с помощью рефлексии. В Java рефлексия - это механизм, который позволяет получить доступ к информации о классах, методах, полях и конструкторах во время выполнения программы. Используя рефлексию, можно получить доступ к private полям класса. Ниже приведен пример получения доступа к private полю класса:
import java.lang.reflect.Field;
public class MyClass {
private String myPrivateField = "private";
public static void main(String[] args) throws Exception {
MyClass obj = new MyClass();
// Получаем объект класса Class, представляющий MyClass
Class cls = obj.getClass();
// Получаем объект Field, представляющий поле myPrivateField
Field field = cls.getDeclaredField("myPrivateField");
// Разрешаем доступ к полю
field.setAccessible(true);
// Получаем значение поля
String value = (String) field.get(obj);
// Выводим значение поля
System.out.println(value);
}
}
В этом примере мы создаем экземпляр класса MyClass, заходим в метаданные класса и получаем доступ к private-полю myPrivateField, устанавливаем доступ к полю, берем значение этого поля и выводим его на экран.
Однако следует понимать, что нарушение инкапсуляции может привести к ошибкам в программе, поэтому использование данного подхода должно быть ограничено крайне необходимыми случаями.
760. Что такое volatile и transient? Для чего и в каких случаях можно было бы использовать default?
В языке Java доступ к private переменным класса можно получить только внутри этого же класса. То есть, если вы пытаетесь обратиться к private переменной другого класса, то вы получите ошибку компиляции.
Однако, есть несколько способов обойти это ограничение. Один из них - использовать сеттеры и геттеры (setter и getter методы), которые позволяют получать и устанавливать значение private переменной через открытые методы. Другой способ - использовать рефлексию, но это не рекомендуется, так как нарушает инкапсуляцию и может привести к непредсказуемому поведению программы.
Вот пример использования сеттера и геттера для доступа к private переменной класса:
public class MyClass {
private String myPrivateVariable;
public void setMyPrivateVariable(String value) {
myPrivateVariable = value;
}
public String getMyPrivateVariable() {
return myPrivateVariable;
}
}
Использование:
MyClass obj = new MyClass();
obj.setMyPrivateVariable("Hello");
String value = obj.getMyPrivateVariable(); // value равно "Hello"
В этом примере мы использовали публичные методы setMyPrivateVariable и getMyPrivateVariable для установки и получения значения private переменной myPrivateVariable.
761. Расширение модификаторов при наследовании, переопределении и сокрытии методов. Если у класса-родителя есть метод, объявленный как private, может ли наследник расширить его видимость? А если protected? А сузить видимость?
При наследовании, по умолчанию, методы, объявленные как private, не наследуются и не могут быть доступны в наследнике. При переопределении метода в наследнике, уровень доступа в наследнике не может быть более ограничен, чем в родителе. То есть, если родитель объявил метод с модификатором protected, то метод переопределенный в наследнике может иметь только protected или public уровень доступа.
Таким образом, наследник не может увеличить уровень доступа метода, объявленного как private, но может изменить уровень доступа метода, объявленного как protected, на public при переопределении.
Насколько я понимаю, при сокрытии метода в наследнике, это не относится к уровням доступа, так как сокрытие - это создание нового метода с тем же именем в наследнике. Таким образом, уровень доступа зависит только от модификатора доступа, указанного в сокрываемом методе, и может быть любым, включая private.
762. Имеет ли смысл объявлять метод private final?
Если метод в Java объявлен как private final, то это означает, что метод может быть вызван только из класса, в котором он был объявлен. Модификатор private обеспечивает доступ только внутри класса, а модификатор final гарантирует, что метод не будет переопределен в подклассах.
Если метод не вызывается из других мест в коде и не должен быть переопределен, то можно объявить его как private final. Однако это может привести к трудностям при тестировании, поскольку тестовые классы не смогут вызвать такой метод.
В целом, объявление метода как private final имеет смысл, если он используется только внутри класса и не должен быть переопределен в подклассах. Если метод должен вызываться из других классов или подклассов, то модификаторы доступа нужно сделать более открытыми, например, protected или public.
Например:
public class MyClass {
private final void doSomethingPrivateAndFinal() {
// some code here
}
}
В данном примере метод doSomethingPrivateAndFinal() будет доступен только внутри класса MyClass и не сможет быть переопределен.
Но не стоит злоупотреблять объявлением методов как private final, так как это может привести к трудностям переиспользования кода и модификации приложения в будущем.
763. Какие особенности инициализации final переменных?
В Java переменные final могут быть инициализированы только один раз. Инициализация final переменных может происходить как при их объявлении, так и в конструкторе класса. Важно отметить, что не инициализированная final переменная является ошибкой во время компиляции. Если final переменная имеет ссылочный тип данных, то после ее инициализации вы можете изменять ее содержимое, но нельзя присвоить ей новое значение:
public class Example {
final int x = 1; // объявление и инициализация final переменной
public Example () {
final int y; // объявление final переменной без инициализации
y = 2; // инициализация final переменной
}
public void modify(final int z) {
// нельзя присваивать новое значение z, так как он помечен как final
System.out.println("z = " + z);
}
}
В данном примере мы можем изменять содержимое ссылочной final переменной s, но не можем присвоить ей новый объект:
public class Example {
final String s = "Hello"; // объявление и инициализация final переменной
public void modify() {
s = "World"; // ошибка компиляции! final переменную нельзя изменить
System.out.println("String: " + s);
}
}
При объявлении переменной final без ее инициализации компилятор выдаст ошибку. Инициализация может быть произведена при объявлении переменной, в блоках инициализации экземпляра и конструкторе.
764. Что будет, если единственный конструктор класса объявлен как final?
В Java нельзя объявить конструктор как final, потому что модификатор final применяется к переменным, а не к методам или конструкторам. Конструкторы не могут быть переопределены, но их можно наследовать. Однако это может привести к проблемам в производных классах, если конструктор не может быть вызван из них.
Например, если только конструктор базового класса является final, производный класс не сможет его переопределить и может не иметь доступа к каким-то полям или методам базового класса.
Другими словами, объявление конструктора как final является неправильной практикой программирования и может сильно ограничить функциональность класса и его производных классов.
764. Что такое finalize? Зачем он нужен? Что Вы можете рассказать о сборщике мусора и алгоритмах его работы.
finalize() - это метод в Java, который позволяет объекту выполнить очистку ресурсов перед удалением сборщиком мусора. Он позволяет объекту выполнить действия перед тем, как он будет удален из памяти. Это может включать закрытие файлов, сетевых соединений или других ресурсов, которые были выделены для использования объектом.
Сборщик мусора в Java является автоматическим механизмом сборки мусора, который автоматически удаляет объекты, которые больше не нужны. Сборщик мусора может работать в различных режимах, например, различных алгоритмах, таких как "метка и очистка" или "копирование", чтобы максимизировать использование доступной памяти и минимизировать время простоя.
Когда объект больше не нужен и в нём больше нет ссылок на него, он будет собран сборщиком мусора, который вызовет метод finalize() перед освобождением памяти, занимаемой объектом. Это позволяет объекту выполнить операции по своей уборке, прежде чем он будет удален из памяти.
Важно заметить, что метод finalize() не гарантирует, что объект будет немедленно удален из памяти. Он может быть вызван сборщиком мусора только после того, как объект станет неотдостижимым для всех потоков исполнения.
Использование finalize() не рекомендуется в Java. Его использование может привести к непредсказуемому поведению, сложностям с производительностью и задержками в сборке мусора. Вместо этого лучше использовать блок try...finally, чтобы гарантировать освобождение ресурсов.
Пример использования finalize():
public class MyClass {
// переменные и методы класса MyClass
// Переопределение метода finalize()
protected void finalize() {
// освобождение ресурсов
}
}
Здесь finalize() в классе MyClass вызывается перед удалением объекта из памяти, т.е., когда сборщик мусора удаляет объект.
765. Почему метод clone объявлен как protected? Что необходимо для реализации клонирования?
Метод clone() в Java объявлен как protected, потому что было решено, что это должен быть метод, доступный только для классов и их подклассов. Более того, для реализации клонирования необходимо реализовать интерфейс Cloneable. Этот интерфейс не имеет методов. Он нужен, чтобы указать, что класс поддерживает клонирование. Если класс не имплементирует Cloneable, то при попытке клонировать объект этого класса будет выброшено исключение CloneNotSupportedException.
Чтобы реализовать клонирование в своем классе, необходимо переопределить метод clone() и вернуть клонированный экземпляр класса, используя метод super.clone(). Затем этот метод должен быть вызван из подкласса в соответствии со своей реализацией клонирования.
Пример реализации клонирования в классе MyClass может выглядеть так:
public class MyClass implements Cloneable {
private int value;
public MyClass(int value) {
this.value = value;
}
public int getValue() {
return value;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
Этот код объявляет класс MyClass как Cloneable , переопределяет метод clone() и вызывает super.clone(). Затем, чтобы склонировать экземпляр, можно сделать следующее:
MyClass obj1 = new MyClass(10);
MyClass obj2 = (MyClass) obj1.clone();
Теперь obj2 является клоном obj1.
3. Исключения (перейти в раздел)
766. Дайте определение понятию “исключение”
Исключение ("Exception" в Java) - это объект, который представляет ошибку или необычную ситуацию, которая произошла во время выполнения программы. Когда происходит ошибка, Java-машина обычно выбрасывает исключение, чтобы сообщить о проблеме. Это может быть вызвано неверным вводом, попыткой доступа к недействительным данным, сетевыми проблемами и т.д. Обычно исключение можно обработать, используя блок try-catch, либо объявляя их в методах с помощью ключевых слов throws или throw. Обработка исключений в Java дает возможность более гибкого управления ошибками в приложении.
767. Какова иерархия исключений.
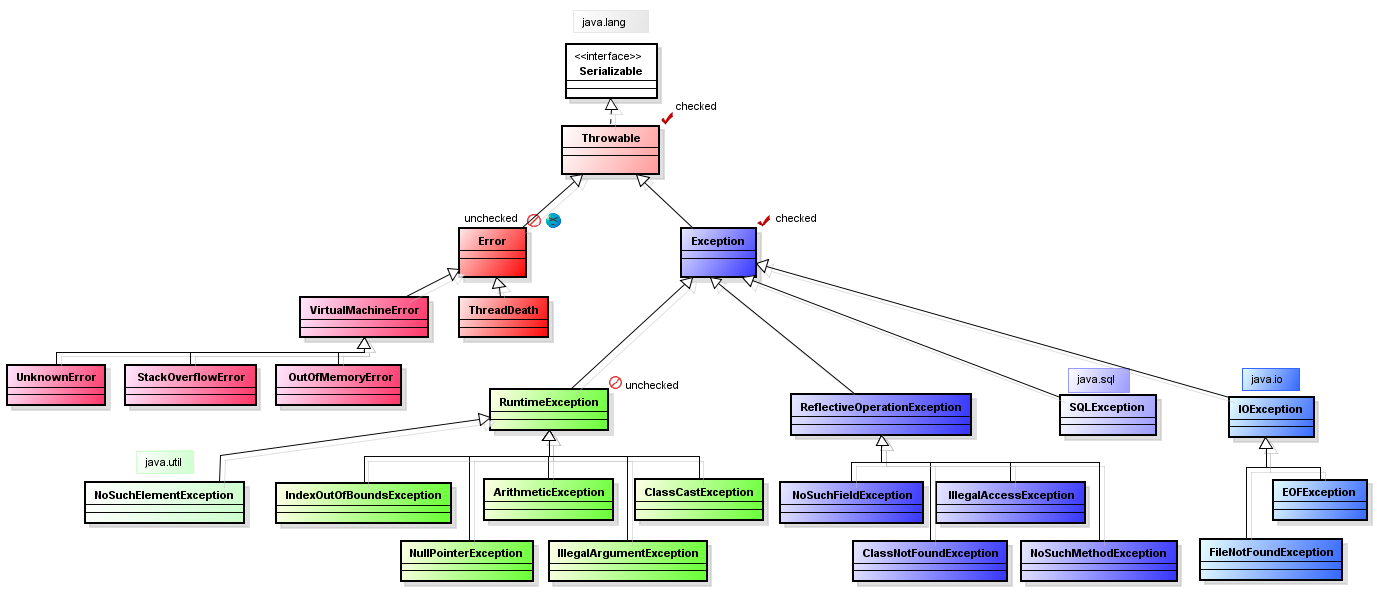
Исключения делятся на несколько классов, но все они имеют общего предка — класс Throwable. Его потомками являются подклассы Exception и Error.
Исключения (Exceptions) являются результатом проблем в программе, которые в принципе решаемы и предсказуемы. Например, произошло деление на ноль в целых числах.
Ошибки (Errors) представляют собой более серьёзные проблемы, которые, согласно спецификации Java, не следует пытаться обрабатывать в собственной программе, поскольку они связаны с проблемами уровня JVM. Например, исключения такого рода возникают, если закончилась память, доступная виртуальной машине. Программа дополнительную память всё равно не сможет обеспечить для JVM.
Исключения в Java делятся на два типа: проверяемые и непроверяемые (unchecked). Проверяемые исключения – это те, которые могут возникнуть при выполнении блока кода, и для их обработки требуется явно указывать блок try-catch или передавать их с помощью оператора throws. Непроверяемые исключения – это те, которые наследуются от RuntimeException, их можно не обрабатывать явно в блоке try-catch.
Контролируемые исключения представляют собой ошибки, которые можно и нужно обрабатывать в программе, к этому типу относятся все потомки класса Exception (но не RuntimeException).
768. Можно/нужно ли обрабатывать ошибки jvm?
Да, в Java можно и нужно обрабатывать ошибки JVM (Java Virtual Machine), которые могут возникнуть при выполнении программы. Ошибки JVM относятся к серьезным проблемам, которые обычно не могут быть восстановлены или обработаны на уровне пользовательского кода.
Ошибки JVM могут быть вызваны различными факторами, такими как выделение памяти, переполнение стека, отсутствие классов и т.д. В случае возникновения таких ошибок, выполнение программы будет немедленно прервано, и сообщение об ошибке будет выведено на консоль или записано в журнал.
Хотя ошибки JVM обычно не обрабатываются непосредственно в коде программы, можно предпринять некоторые действия для лучшего контроля и обработки этих ошибок. Например, можно использовать блоки try-catch-finally для перехвата и обработки исключений, которые могут предшествовать ошибкам JVM, и выполнять соответствующие действия, такие как запись сообщения об ошибке, закрытие ресурсов и т.д.
Важно отметить, что хотя обработка ошибок JVM может помочь в лучшем контроле программы, они обычно указывают на серьезные проблемы, требующие внимания системного администратора или разработчика для их устранения.
769. Какие существуют способы обработки исключений?
В Java есть несколько способов обработки исключений:
Использование блока try-catch: это позволяет обработать исключение, выброшенное внутри блока try, и выполнить код в блоке catch для обработки этого исключения. Пример:
try {
// код, который может вызвать исключение
} catch (Exception e) {
// код для обработки исключения
}
Использование блока try-finally: это позволяет выполнить некоторый код, даже если возникает исключение. Пример:
try {
// код, который может вызвать исключение
} finally {
// код, который будет выполнен всегда, даже если возникло исключение
}
Использование блока try-catch-finally: это сочетание двух предыдущих способов и позволяет обработать исключение и выполнить код, даже если оно возникло. Пример:
try {
// код, который может вызвать исключение
} catch (Exception e) {
// код для обработки исключения
} finally {
// код, который будет выполнен всегда, даже если возникло исключение
}
Оператор throws: это позволяет выбросить исключение из метода, чтобы обработать его в другом месте. Пример:
public void someMethod() throws Exception {
// код, который может вызвать исключение
}
Использование оператора throwдля выброса исключения внутри кода. Например:
if (a == 0) {
throw new Exception("Деление на ноль");
}
Создание собственных исключений. Это позволяет создавать свои собственные классы исключений и генерировать их при необходимости. Например
public class MyException extends Exception {
public MyException() {}
public MyException(String message) {
super(message);
}
}
// генерируем исключение
throw new MyException("Мое исключение");
Эти способы позволяют обрабатывать исключения в Java и делать код более безопасным и устойчивым к сбоям.
770. О чем говорит ключевое слово throws?
Ключевое слово throws в Java используется в объявлении метода для указания списка исключений, которые могут возникнуть, когда метод вызывается. Это помогает вызывающей стороне лучше понимать, какие исключения может выбросить метод, и как нужно обрабатывать их. Если метод может выбросить исключения, то они должны быть обработаны с помощью try-catch или декларированы в блоке throws самого метода.
Например, в следующей сигнатуре метода calculateDivision объявлено ключевое слово throws для указания списка исключений, которые могут возникнуть:
public double calculateDivision(int numerator, int denominator) throws ArithmeticException {
if (denominator == 0) {
throw new ArithmeticException("Division by zero");
}
return numerator / denominator;
}
Это означает, что при вызове метода calculateDivision могут возникнуть исключения типа ArithmeticException, и вызывающая сторона должна либо обработать их с помощью блока try-catch, либо декларировать блок throws в собственной сигнатуре метода.
771. В чем особенность блока finally? Всегда ли он исполняется?
Блок finally в Java выполняется всегда, независимо от того, возникло ли исключение или нет. Это позволяет гарантировать, что определенные критические операции будут выполнены независимо от того, что произойдет в блоке try-catch. Например, если вы используете ресурс, например, открытый файл или соединение с базой данных, блок finally гарантирует, что ресурс будет правильно закрыт, даже если в блоке try произошло исключение.
Если вы используете блок try-catch без блока finally, то может возникнуть ситуация, когда ресурс не будет закрыт, поскольку код, находящийся после блока try-catch, не будет выполнен.
Но стоит отметить, что блок finally не выполняется только в тех случаях, когда программа "упала" или был прерван процесс выполнения посредством вызова метода System.exit().
772. Может ли не быть ни одного блока catch при отлавливании исключений?
В Java, при отлавливании исключений можно не использовать блок catch, но в этом случае необходимо использовать блок finally. Этот блок будет выполнен в любом случае, независимо от того, генерируется исключение или нет.
Например, следующий код отлавливает исключение IOException с помощью блока finally:
try {
// code that can throw an IOException
}
finally {
// cleanup code that will run regardless of whether an exception is thrown or not
}
Блок finally может быть использован для освобождения ресурсов, например, закрытия потоков ввода/вывода или сетевых соединений.
Однако, в большинстве ситуаций, следует использовать блок catch для обработки исключений, чтобы обеспечить корректную обработку ошибок в вашем коде.
773. Могли бы вы придумать ситуацию, когда блок finally не будет выполнен?
В Java блок finally всегда будет выполнен, за исключением следующих ситуаций:
-
Если процесс JVM прерывается или останавливается во время работы блока try или catch, или происходит сбой питания.
-
Если в блоке try или catch вызван System.exit(). Во всех остальных случаях блок finally будет выполнен.
774. Может ли один блок catch отлавливать несколько исключений (с одной и разных веток наследований)?
Да, в Java блок catch может отлавливать несколько исключений. Для этого нужно перечислить типы исключений через символ |. Например:
try {
// выполнение кода, которое может привести к исключению
} catch (IOException | SQLException ex) {
// обработка исключения типа IOException или SQLException
}
Здесь блок catch отлавливает исключения типа IOException или SQLException. Также возможно использование иерархии классов исключений. Например, если класс SQLException является подклассом Exception, то его можно указать как catch (IOException | Exception ex).
775. Что вы знаете об обрабатываемых и не обрабатываемых (checked/unchecked) исключениях?
В Java есть два типа исключений: обрабатываемые (checked) и необрабатываемые (unchecked).
Обрабатываемые исключения - это те, которые должны быть обработаны в блоке try-catch или быть перехваченными вызывающим методом. Это исключения, которые могут возникнуть в процессе выполнения программы, но которые программа может и должна обработать. Примерами обрабатываемых исключений являются IOException (возникает, когда происходит сбой ввода-вывода), SQLException (ошибка при выполнении SQL-запроса) и ClassNotFoundException (если класс, на который ссылается программа, не найден во время выполнения).
Необрабатываемые исключения, также называемые ошибками, отличаются от обрабатываемых тем, что вызывающий метод не обязан их перехватывать или обрабатывать. Обычно это исключения, которые указывают на ошибки в самой программе, и их следует исправлять, а не обрабатывать. Примеры необрабатываемых исключений включают в себя NullPointerException (возникает, когда программа пытается обратиться к объекту, который не был инициализирован), ArrayIndexOutOfBoundsException (возникает, когда индекс массива находится за пределами допустимого диапазона) и ClassCastException (возникает, когда программа пытается привести объект к неправильному типу).
Пример кода для обработки checked исключений в Java:
try {
FileInputStream fileInputStream = new FileInputStream("file.txt");
// do something with the input stream
} catch (FileNotFoundException e) {
System.out.println("The file was not found.");
}
Пример кода для обработки unchecked исключений в Java:
String str = null;
try {
System.out.println(str.length()); // вызывает java.lang.NullPointerException
} catch (NullPointerException e) {
System.out.println("The string is null.");
}
776. В чем особенность RuntimeException?
public class RuntimeException extends Exception — базовый класс для ошибок во время выполнения.
Особенность класса RuntimeException в том, что этот класс наследуется от класса Exception, но является подклассом непроверяемых исключений, то есть не требует обработки или объявления с помощью оператора throws. Это сделано для того, чтобы программисты могли легче обрабатывать ошибки, связанные с некорректным использованием методов класса, например, когда указывается неправильный индекс массива или деление на ноль. RuntimeException могут возникать в ходе выполнения программы, и обычно их нельзя заранее предотвратить. Единственное, что можно сделать, - это обработать исключение, если оно возникнет.
777. Как написать собственное (“пользовательское”) исключение? Какими мотивами вы будете руководствоваться при выборе типа исключения: checked/unchecked?
Для написания пользовательского исключения в Java необходимо создать свой класс и унаследовать его от одного из существующих классов исключений. Например, для создания непроверяемого исключения можно унаследоваться от класса RuntimeException, а для создания проверяемого - от класса Exception. В классе-исключении необходимо определить конструкторы и методы, а также можно добавить свои поля и методы.
Пример создания пользовательского проверяемого исключения:
public class MyCheckedException extends Exception {
public MyCheckedException() { }
public MyCheckedException(String message) {
super(message);
}
}
Пример создания пользовательского непроверяемого исключения:
public class MyUncheckedException extends RuntimeException {
public MyUncheckedException() { }
public MyUncheckedException(String message) {
super(message);
}
}
При выборе типа исключения необходимо определить, должен ли вызывающий код обрабатывать это исключение или нет. Если вызывающий код должен обработать исключение, необходимо выбрать проверяемое исключение. В противном случае, если вызывающий код не может обработать исключение или это не имеет смысла, лучше выбрать непроверяемое исключение.
Кроме того, при выборе типа исключения необходимо учитывать, что непроверяемые исключения не обязательно должны быть выброшены из метода или объявлены в его сигнатуре, в отличие от проверяемых исключений. Однако, если исключение выбрасывается и должно быть обработано вызывающим кодом, лучше использовать проверяемое исключение.
778. Какой оператор позволяет принудительно выбросить исключение?
В Java оператор, который позволяет принудительно выбросить исключение, называется throw. Он используется для отправки исключения в явном виде из метода или блока кода. Например, для выброса экземпляра исключения Exception можно использовать следующий код:
throw new Exception("Some error message");
где "Some error message" - это сообщение об ошибке, которое будет включено в исключение.
Также следует упомянуть оператор throws, который используется для указания типов исключений, которые могут быть выброшены методом. Он добавляется в сигнатуру метода после блока параметров. Например, следующая сигнатура метода указывает, что он может выбросить исключение типа IOException:
public void myMethod() throws IOException {
// some code here
}
779. Есть ли дополнительные условия к методу, который потенциально может выбросить исключение?
Да, есть. Если метод может выбросить исключение, то это должно быть указано в сигнатуре метода при помощи ключевого слова throws, за которым следует список исключений, которые могут быть выброшены. Например:
public void myMethod() throws IOException, InterruptedException {
// тело метода, которое может вызвать исключение IOException или InterruptedException
}
В этом примере метод myMethod() может выбросить два типа исключений: IOException и InterruptedException. Если метод вызывается в другом методе, который не ловит эти исключения, то также должно быть указано, что он тоже может выбросить эти исключения. Это делается аналогичным образом, через ключевое слово throws.
780. Может ли метод main выбросить исключение во вне и если да, то где будет происходить обработка данного исключения?
Да, метод main в Java может выбрасывать исключения. Если исключение не обрабатывается в самом методе main, то оно будет передано системе, которая затем обработает его соответствующим образом. Если исключение не будет обработано ни в одном из методов в стеке вызовов, то Java Virtual Machine (JVM) завершит работу с соответствующим сообщением об ошибке и стеком трассировки (stack trace), который указывает на последовательность вызовов методов, которые привели к возникновению ошибки.
Например, если в методе main было выброшено исключение IOException и оно не было обработано в этом же методе, то ошибка будет передана в систему и может быть обработана либо другими методами в программе, либо обработчиком исключений по умолчанию, который может завершить работу программы и вывести сообщение об ошибке с описанием проблемы и стеком трассировки.
Пример кода, который может выбросить IOException:
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
throw new IOException("Something went wrong");
}
}
В этом примере мы выбрасываем IOException при запуске метода main и указываем, что исключение не будет обрабатываться внутри самого метода, а будет передано выше по стеку вызовов.
781. Если оператор return содержится и в блоке catch и в finally, какой из них “главнее”?
Если оператор return содержится и в блоке catch и в блоке finally, то в конечном итоге возвращаемое значение будет зависеть от того, было ли выброшено исключение и было ли оно обработано.
Если исключение было выброшено, то выполнение перейдет в блок catch, и значение, возвращаемое в блоке catch, будет являться конечным результатом. Если исключение не было выброшено, то выполнение перейдет в блок finally, и значение, возвращаемое в блоке finally, будет являться конечным результатом.
Это довольно сложное поведение, и в целом не рекомендуется иметь оператор return в обоих блоках. Вместо этого рекомендуется использовать только один оператор return, и помещать его в блок try перед блоком catch и finally.
Например, вот как это может выглядеть на Java:
public static int myMethod() {
try {
// некоторый код, который может вызвать исключение
return 1;
} catch (Exception e) {
// обрабатывать исключение
return 2;
} finally {
// какой-то код, который всегда работает
return 3;
}
}
Здесь будет возвращено значение 3, потому что блок finally всегда выполняется, а оператор return в блоке finally имеет приоритет по отношению к операторам return в блоках try и catch.
782. Что вы знаете о OutOfMemoryError?
OutOfMemoryError - это исключение, которое возникает в языке программирования Java, когда приложение пытается выделить больше памяти, чем доступно в куче (heap).
Куча (heap) - это область памяти, выделенная для хранения объектов в Java. Когда приложение создает объекты, они размещаются в куче. Куча имеет фиксированный размер, определенный при запуске приложения или виртуальной машиной Java (JVM). Если приложение пытается создать новый объект и в куче недостаточно свободной памяти для его размещения, возникает исключение OutOfMemoryError.
OutOfMemoryError может возникнуть по нескольким причинам:
Утечка памяти (Memory Leak): Когда объекты создаются, но не освобождаются после использования, они продолжают занимать память в куче. При повторном создании объектов без освобождения памяти может произойти исчерпание ресурсов памяти и возникнет OutOfMemoryError.Выделение слишком большого объема памяти: Если приложению требуется создать массив или структуру данных очень большого размера, которые превышают доступное пространство в куче, может возникнуть OutOfMemoryError.Неправильная конфигурация JVM: Если размер кучи, выделенной для приложения, слишком мал или недостаточно настроенные параметры связанные с управлением памятью, могут возникать ошибки OutOfMemoryError.
При возникновении OutOfMemoryError рекомендуется принять следующие меры:
- Проверить код приложения на наличие утечек памяти и исправить их. Утечки памяти могут быть вызваны неправильным использованием объектов, неосвобождением ресурсов или циклическими ссылками.
- Постараться оптимизировать использование памяти. Это может включать использование более эффективных структур данных, уменьшение размера данных хранения или использование потокового обработки данных.
- Увеличить размер кучи JVM, выделенной для приложения, путем изменения параметров запуска JVM (например, -Xmx для указания максимального размера кучи).
- Использовать инструменты профилирования и отладки для анализа использования памяти и поиска проблемных участков в коде приложения.
Важно помнить, что OutOfMemoryError - это серьезная ошибка, которая может привести к сбою приложения. Поэтому необходимо внимательно следить за использованием памяти в своих Java-приложениях и регулярно проводить тестирование на утечки памяти.
783. Что вы знаете о SQLException? К какому типу checked или unchecked оно относится, почему?
SQLException — это класс исключений в языке программирования Java, представляющий ошибки, возникающие при доступе к базе данных с помощью JDBC. SQLException — это проверенное исключение, что означает, что оно должно быть либо перехвачено, либо объявлено в сигнатуре метода с помощью ключевого слова «throws». Непроверенные исключения, такие как RuntimeException и Error, могут быть выброшены без объявления в сигнатуре метода.
Причина, по которой SQLException является проверенным исключением, заключается в том, что оно представляет собой исправимую ошибку при доступе к базе данных, и код, использующий JDBC, должен иметь возможность осмысленно обрабатывать эти ошибки. Например, исключение SQLException может быть выдано, если не удается установить соединение с базой данных или если запрос не выполняется из-за синтаксической ошибки.
Делая SQLException проверенным исключением, язык Java гарантирует, что разработчики знают об этих возможных состояниях ошибок и вынуждены обрабатывать их в своем коде. Следовательно, чтобы использовать JDBC в Java, вы должны либо обрабатывать SQLException с помощью блок try-catch или объявите его, используя ключевое слово «throws» в сигнатуре метода.
784. Что такое Error? В каком случае используется Error. Приведите пример Error’а.
Error — это класс в Java, представляющий ошибку времени выполнения или ошибку, связанную с приложением, которую нельзя исправить. Исключение Error возникает, когда возникает серьезная проблема, от которой программа не должна пытаться восстановиться. Примеры ситуаций, которые могут привести к ошибке, включают исчерпание ресурсов на уровне системы, отсутствие системных файлов и переполнение стека. Вот пример того, как выдать ошибку в Java:
if (someCondition) {
throw new Error("This is an example of an Error");
}
В этом примере выдается ошибка с сообщением «Это пример ошибки», если условие истинно. Программа не должна пытаться исправить эту ошибку, а вместо этого должна завершить работу или предпринять другие соответствующие действия.
785. Какая конструкция используется в Java для обработки исключений?
В Java для обработки исключений используется конструкция try-catch. Вы можете обернуть код, который может вызвать исключение, в блок try, после которого следует один или несколько блоков catch, которые будут выполнены при возникновении исключения определенного типа. Конструкция try-catch позволяет вам обрабатывать исключения в вашем коде, избежать аварийных остановок и скрыть детали ошибок от конечного пользователя. Пример:
try {
// Код, который может вызвать исключение
} catch (SomeException e) {
// Код, который обрабатывает исключение типа SomeException
}
Если вам нужно выполнить код после завершения блока try (независимо от того, возникло исключение или нет), вы можете использовать блок finally. Пример:
try {
// Код, который может вызвать исключение
} catch (SomeException e) {
// Код, который обрабатывает исключение типа SomeException
} finally {
// Код, который будет выполнен после завершения блока try-catch, независимо от того, возникло исключение или нет.
}
786. Предположим, есть блок try-finally. В блоке try возникло исключение и выполнение переместилось в блок finally. В блоке finally тоже возникло исключение. Какое из двух исключений “выпадет” из блока try-finally? Что случится со вторым исключением?
Если в блоке try возникает исключение, а затем выполнение уходит в блок finally, и там возникает исключение, то это второе исключение "перебросится" вверх по стеку вызовов методов в вызывающий код, в то время как первое исключение будет потеряно.
Конкретная реакция на второе исключение будет зависеть от того, обрабатывается ли его кодом в вызывающем методе или перебрасывается выше. Однако, исключения в блоке finally могут затруднить отладку программы, так как первоначальная причина исключения может быть скрыта, а стек вызовов может быть запутанным. Из-за этого рекомендуется избегать использования вложенных блоков try-finally, а также тщательно обрабатывать исключения, которые могут возникнуть в блоке finally.
786 Предположим, есть метод, который может выбросить IOException и FileNotFoundException в какой последовательности должны идти блоки catch? Сколько блоков catch будет выполнено?
Если метод может выбросить исключения IOException и FileNotFoundException, то блоки catch должны следовать в порядке от конкретного к более общему, то есть сначала нужно перехватывать FileNotFoundException, а затем IOException. Это связано с тем, что FileNotFoundException является конкретным подклассом IOException, и при наличии нескольких блоков catch будет выполнен только первый, который соответствует типу выброшенного исключения.
Следующий код демонстрирует правильный порядок блоков catch для обработки исключений IOException и FileNotFoundException:
try {
// код, который может выбросить IOException или FileNotFoundException
} catch (FileNotFoundException e) {
// обработка FileNotFoundException
} catch (IOException e) {
// обработка IOException
}
В зависимости от того, какие исключения будут выброшены, будет выполнен либо первый блок catch, либо второй, но не оба сразу.
4. Коллекции (перейти в раздел)
787. Дайте определение понятию “коллекция”.
"Коллекция" - это набор элементов, которые могут храниться и использоваться вместе в рамках одной структуры данных. В Java "коллекции" обеспечивают удобную и эффективную работу с группами элементов различного типа и объема. Java Collections Framework является частью стандартной библиотеки Java, которая предоставляет реализацию множества структур данных, таких как списки, множества, отображения и т.д. Все коллекции фреймворка Java реализуют общие интерфейсы, которые позволяют использовать их единообразно и удобно в программе.
788. Назовите преимущества использования коллекций.
Использование коллекций в Java имеет несколько преимуществ:
Удобство: Коллекции предоставляют удобные и легко используемые методы для работы с данными, такие как добавление, удаление, поиск, сортировка и фильтрация элементов коллекции. Они предоставляют высокоуровневый интерфейс для манипулирования данными.Гибкость: В Java предоставляется большой набор различных типов коллекций, таких как списки (List), множества (Set), отображения (Map) и другие. Это позволяет выбрать подходящую коллекцию для конкретной задачи и оптимизировать работу с данными.Расширяемость: В Java можно создавать свои собственные реализации коллекций или расширять существующие. Это дает возможность адаптировать коллекции под специфические требования вашего приложения.Автоматическое управление памятью: Коллекции в Java автоматически управляют памятью, освобождая программиста от необходимости явно выделять и освобождать память для хранения данных.Повышение производительности: Некоторые коллекции, такие как ArrayList или HashSet, обеспечивают эффективный доступ к элементам и хорошую производительность для основных операций, таких как поиск и вставка.Поддержка обобщений: Коллекции в Java поддерживают обобщения (generics), что позволяет создавать типобезопасные коллекции. Это способствует устранению ошибок времени выполнения и повышает надежность кода.Интеграция с другими API: Коллекции интегрируются с другими API в Java, такими как потоки (Streams), параллельные вычисления (Parallel Streams) и алгоритмы для работы с коллекциями (Collections API). Это упрощает и улучшает работу с данными и их обработку.
В целом, использование коллекций в Java помогает упростить и ускорить работу с данными, обеспечивает гибкость и расширяемость кода, а также повышает надежность и производительность приложений.
789. Какие данные могут хранить коллекции?
Коллекции в Java могут хранить различные типы данных, в зависимости от типа коллекции.
Например, в ArrayList и LinkedList можно хранить любые ссылочные типы данных (например, объекты классов). В HashSet и TreeSet можно хранить уникальные элементы любого типа данных (при условии, что они реализуют интерфейс hashCode() и equals()). В HashMap и TreeMap можно хранить пары "ключ-значение" любых типов данных, и т.д.
Java Collections Framework также предоставляет специализированные коллекции для хранения определенных типов данных, например, Vector для хранения объектов в последовательности, Stack для реализации стека, PriorityQueue для хранения элементов в порядке их приоритета и т.д.
Таким образом, коллекции в Java могут хранить широкий диапазон данных, начиная от примитивных типов до сложных объектов, в зависимости от выбранной коллекции и типов данных, которые вы хотите хранить в ней.
790. Какова иерархия коллекций?
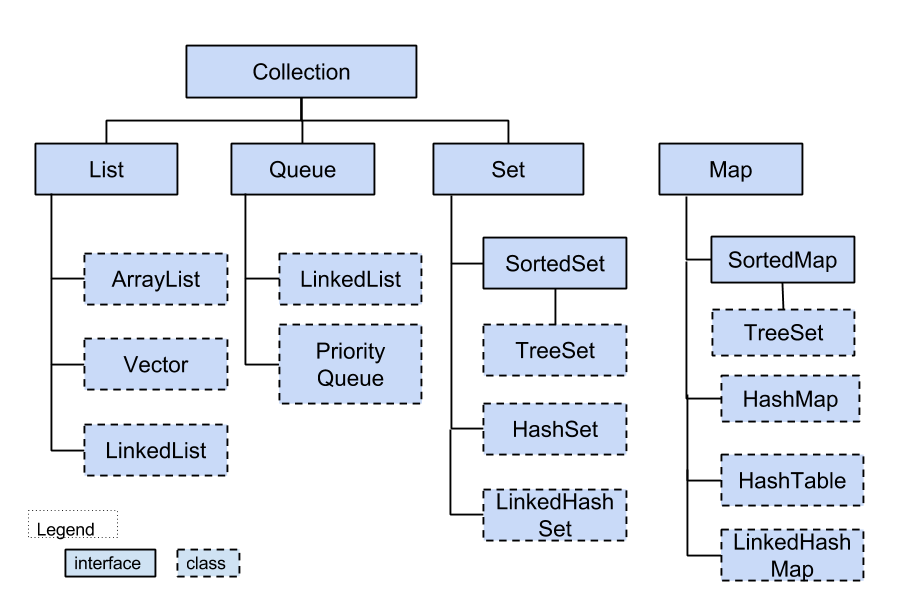
В Java коллекции организованы в виде иерархии классов и интерфейсов. На вершине этой иерархии находится интерфейс Collection, а интерфейс Map является отдельной ветвью. Вот некоторые интерфейсы и классы, относящиеся к этой иерархии:
Вот основные интерфейсы Java коллекций:
+ Collection
AbstractCollection
ArrayList
LinkedList
+ List
AbstractList
ArrayList
LinkedList
+ Set
AbstractSet
HashSet
LinkedHashSet
+ SortedSet
TreeSet
+ NavigableSet
TreeSet
+ Queue
AbstractQueue
LinkedList
PriorityQueue
+ Deque
ArrayDeque
LinkedList
Collection представляет общую структуру всех коллекций, а List, Set, Queue и Map представляют различные типы коллекций. Классы, такие как ArrayList и HashSet, предоставляют конкретную реализацию этих интерфейсов. Они значительно различаются по своим особенностям, таким как производительность, порядок хранения элементов и возможность хранения дубликатов.
791. Что вы знаете о коллекциях типа List?
Java Collections типа List - это упорядоченная коллекция элементов, которая может содержать дублирующиеся элементы. Она предоставляет методы для добавления, удаления и доступа к элементам по индексу. Некоторые из наиболее распространенных классов, реализующих интерфейс List, включают ArrayList, LinkedList и Vector.
ArrayList - это изменяемый список, который расширяется по мере необходимости и позволяет быстро доступать к элементам по индексу.
LinkedList - это двунаправленный связанный список, который позволяет быстро добавлять и удалять элементы из начала и конца списка.
Vector - это синхронизированный список, который подобен ArrayList, но обеспечивает потокобезопасность при одновременном доступе из нескольких потоков.
Интерфейс List предоставляет методы, такие как add(), remove(), get(), indexOf() и size(), которые позволяют манипулировать списком элементов.
792. Что вы знаете о коллекциях типа Set?
Set (множество) в Java - это коллекция, которая хранит уникальные элементы в неупорядоченном виде. Элементы, добавленные в Set, должны быть уникальными, то есть Set не может содержать дубликаты.
Set в Java является интерфейсом, который реализует коллекцию, содержащую только уникальные элементы. Он представлен классами HashSet, TreeSet и LinkedHashSet.
HashSet не содержит дубликатов и не гарантирует порядок хранения элементов.
TreeSet хранит элементы в отсортированном порядке, который может быть настраиваемым.
LinkedHashSet гарантирует сохранение порядка элементов в том порядке, в котором они были добавлены.
Интерфейс Set также имеет несколько полезных методов, таких как add() для добавления элемента, remove() для удаления элемента и contains() для проверки наличия элемента в наборе.
793. Что вы знаете о коллекциях типа Queue?
В Java коллекции типа Queue представляют собой структуры данных, которые управляют элементами в порядке "первым пришёл - первым вышел" (First-In-First-Out или FIFO). Это означает, что элемент, добавленный первым, будет удален первым.
Некоторые из основных интерфейсов и классов, связанных с коллекциями типа Queue в Java, включают:
Queue - это интерфейс, который представляет базовые методы для работы с очередью. Некоторые из наиболее используемых методов этого интерфейса включают add(), offer(), remove(), poll(), element() и peek().
LinkedList - это класс реализации интерфейса Queue. Он предоставляет функциональность двусвязного списка и также реализует интерфейсы List и Deque. LinkedList поддерживает все операции, определенные в интерфейсе Queue.
PriorityQueue - это еще один класс реализации интерфейса Queue. В отличие от LinkedList, PriorityQueue представляет собой очередь с приоритетом, где каждый элемент имеет определенное значение приоритета. Элементы в PriorityQueue хранятся в отсортированном порядке, в соответствии с их приоритетом.
ArrayDeque - это класс, который реализует интерфейс Deque и может использоваться в качестве очереди или стека. Он предоставляет более эффективные операции добавления и удаления в начало и конец очереди.
Коллекции типа Queue полезны во многих сценариях, таких как обработка задач в порядке их поступления, планирование алгоритмов и т. д.
794. Что вы знаете о коллекциях типа Map, в чем их принципиальное отличие?
Коллекции типа Map в Java представляют собой структуру данных, которая содержит пары ключ-значение и позволяет быстро находить значение по его ключу. Они отличаются от других коллекций, таких как List и Set, тем, что элементы в Map хранятся в виде пар ключ-значение, а не отдельных элементов. Ключи должны быть уникальными, в то время как значения могут повторяться. Map-ы могут быть реализованы различными способами, но основными реализациями являются HashMap, TreeMap и LinkedHashMap.
HashMap - это наиболее распространенная реализация Map-а в Java. Он предоставляет постоянное время выполнения для основных операций, таких как get() и put(). Однако порядок элементов в HashMap не гарантируется.
TreeMap - это реализация, которая хранит пары ключ-значение в отсортированном порядке, основанном на ключе. В отличие от HashMap, TreeMap гарантирует порядок элементов.
LinkedHashMap - это реализация, которая сохраняет порядок вставки элементов. Ключи хранятся в том порядке, в котором они были добавлены.
В целом, использование Map позволяет эффективно хранить и доступаться к данным по ключу. Конкретная реализация Map должна выбираться в зависимости от требований к производительности и составу данных.
795. Назовите основные реализации List, Set, Map.
В Java есть несколько основных реализаций интерфейсов List, Set и Map:
List:
ArrayList
LinkedList
Vector (устаревший)
Set:
HashSet
LinkedHashSet
TreeSet
Map:
HashMap
LinkedHashMap
TreeMap
Hashtable (устаревший)
Эти реализации предоставляют разные способы хранения и организации данных в список, множество или отображение.
Например, ArrayList хранит элементы в массиве и позволяет быстрый доступ к элементам по индексу, в то время как LinkedList хранит элементы в виде связанного списка и имеет быстрое добавление и удаление элементов.
HashSet использует хэш-функцию для быстрого поиска элементов в множестве, LinkedHashSet поддерживает порядок вставки элементов, а TreeSet хранит элементы в отсортированном порядке.
HashMap использует хэш-таблицу для быстрого поиска элементов по ключу, LinkedHashMap поддерживает порядок вставки элементов, а TreeMap хранит элементы в отсортированном порядке ключей.
796. Какие реализации SortedSet вы знаете и в чем их особенность?
Существует несколько реализаций интерфейса SortedSet в Java, включая:
TreeSet - основанная на TreeMap, имеет время доступа O(log n) для операций добавления, удаления и поиска элементов. Элементы будут автоматически отсортированы в порядке возрастания.
ConcurrentSkipListSet - это потокобезопасная реализация SortedSet, основанная на ConcurrentSkipListMap, с доступным временем O(log n) для операций добавления, удаления и поиска элементов. Он использует блокировки, которые позволяют нескольким потокам одновременно изменять набор.
CopyOnWriteArraySet - это потокобезопасная реализация SortedSet, основанная на CopyOnWriteArrayList, которая предоставляет последовательный доступ к элементам. Это означает, что время доступа к элементу O(n), но операции добавления, удаления и поиска элементов являются потокобезопасными, так как копия набора создается при каждой модификации.
EnumSet - это реализация SortedSet, которая предназначена только для перечислений. Он использует битовые флаги для представления элементов множества и поэтому не может изменять размер после создания. Он быстр и использует меньше памяти, чем другие реализации множества.
797. В чем отличия/сходства List и Set?
В Java, List и Set являются двумя разными типами коллекций, которые предоставляют различные способы организации и работы с набором элементов.
List представляет собой упорядоченную коллекцию элементов, которые могут содержать повторяющиеся значения. Доступ к элементам осуществляется по индексу, то есть каждый элемент имеет свой порядковый номер. Примерами реализаций List являются ArrayList и LinkedList.
Set представляет собой неупорядоченную коллекцию уникальных элементов. Каждый элемент может встречаться только один раз. Доступ к элементам осуществляется через методы, предоставляемые самим интерфейсом Set. Примерами реализаций Set являются HashSet и TreeSet.
В общем смысле List и Set имеют несколько различающиеся свойства:
-
List поддерживает дублирование элементов, Set - нет;
-
List обеспечивает доступ к элементам по индексу, а Set - нет;
-
Set гарантирует, что не будет дублирования элементов, List - нет;
-
Set хранит элементы в произвольном порядке, в то время как List - в порядке их добавления.
Выбор между List и Set зависит от конкретного случая использования коллекции и требований к ее поведению.
798. Что разного/общего у классов ArrayList и LinkedList, когда лучше использовать ArrayList, а когда LinkedList?
Оба класса ArrayList и LinkedList реализуют интерфейс List в Java и предоставляют реализацию динамического массива. Однако, есть некоторые ключевые различия:
-
Сложность операций вставки/удаления элемента:
-
- В ArrayList при вставке/удалении элемента происходит смещение всех последующих элементов в памяти, что требует больше времени для выполнения операции;
-
- В LinkedList такие операции затрагивают только соседние элементы, но требуют более сложной работы с указателями.
-
Доступ к элементам:
-
- В ArrayList к элементу можно обращаться по индексу, что позволяет производить доступ за O(1) времени;
-
- В LinkedList к элементу необходимо обращаться последовательно, что может затянуться на O(n) времени.
Поэтому, если в приложении используются операции вставки/удаления элементов, преимущественно в начале/конце списка, рекомендуется использовать LinkedList, а если приложение быстрее работает с доступом к элементу по индексу, то следует использовать ArrayList.
Небольшой exception будет, если вы работаете с большими наборами данных (несколько миллионов элементов): в таком случае ArrayList намного эффективнее, чем LinkedList.
ArrayList хранит элементы в виде массива переменной длины, который автоматически расширяется по мере добавления новых элементов в список. LinkedList представляет собой двусвязный список, который хранит ссылки на следующий и предыдущий узлы.
-
Когда использовать ArrayList: -
- если требуется доступ к элементам списка по индексу, т.е. нужен быстрый доступ к произвольным элементам
-
- если требуется итерация (перебор) списка, особенно в одном направлении.
-
Когда использовать LinkedList: -
- если необходимо добавлять или удалять элементы в середине списка
-
- при интенсивном использовании операций вставки и удаления, особенно для больших списков.
Таким образом, оба класса предоставляют реализацию списка, но используют разные методы хранения элементов, поэтому выбор зависит от конкретных требований приложения.
799. В каких случаях разумно использовать массив, а не ArrayList?
В Java массивы используются для хранения элементов фиксированного размера. Однако, если вам нужно хранить элементы переменной длины, то лучшим выбором будет ArrayList, который реализует интерфейс List и автоматически увеличивает свой размер при добавлении новых элементов.
Использование массивов в Java может оказаться разумным в случаях, когда:
-
Вы знаете заранее фиксированный размер элементов;
-
Вам нужен прямой доступ к элементам по индексу;
Вам нужно хранить примитивные типы данных (такие как int, double), которые могут быть размещены непосредственно в массиве.
Однако в остальных случаях, рекомендуется использовать ArrayList, который упрощает добавление и удаление элементов и позволяет динамически изменять размер коллекции.
800. Чем отличается ArrayList от Vector?
В Java классы ArrayList и Vector реализуют интерфейс List и имеют схожую реализацию динамического массива. Но есть несколько отличий:
-
Синхронизация: Vector'ы синхронизированы по умолчанию, что может привести к небольшому падению производительности. ArrayList'ы по умолчанию не синхронизированы и не потокобезопасны. -
Размер массива: Когда элементы добавляются в Vector, он инкрементирует размер массива на 100% (или на другой заданный процент). ArrayList инкрементирует размер массива на 50% его текущего размера. -
Итераторы:Итераторы для обоих классов реализованы одинаково, но для Vector рекомендуется использовать его старшую сестру - Enumeration.
В общем, если вы не работаете в многопоточном окружении или вам не нужна дополнительная синхронизация, то ArrayList более предпочтительный выбор благодаря своей лучшей производительности. Если нужна синхронизация, то рекомендуется использовать классы, которые реализуют интерфейс List вместо Vector.
801. Что вы знаете о реализации классов HashSet и TreeSet?
HashSet и TreeSet - это два класса в Java, которые унаследованы от интерфейса Set и предоставляют доступ к набору уникальных элементов.
HashSet реализует паттерн хэш-таблицы и является наиболее популярным классом множества в Java. В отличие от списка, который хранит элементы в последовательном порядке, HashSet хранит элементы в случайном порядке. Элементы HashSet хранятся в виде хэш-кодов, что обеспечивает быстрый поиск элементов. Класс HashSet не гарантирует порядок, в котором элементы будут возвращены при итерировании по множеству.
TreeSet реализует интерфейсы NavigableSet и SortedSet, что означает, что элементы в нем будут храниться в отсортированном порядке. Класс TreeSet сохраняет элементы в древовидной структуре, что обеспечивает быстрый доступ к элементам, а также возможность выполнять операции, связанные с диапазонами элементов. Однако, TreeSet медленнее, чем HashSet, потому что для каждой операции добавления, удаления и поиска элемента необходимо выполнить дополнительные манипуляции со структурой дерева.
Также следует учитывать, что при использовании TreeSet необходимо, чтобы добавляемые элементы были сравнимы или был передан компаратор при создании объекта TreeSet.
Несмотря на различия в их реализации, оба класса имеют одинаковую сложность времени выполнения для основных операций, таких как вставка, удаление и поиск элемента, равную O(1) в среднем случае и O(N) в худшем случае.
802. Чем отличаются HashMap и TreeMap? Как они устроены и работают? Что со временем доступа к объектам, какие зависимости?
HashMap и TreeMap являются двумя реализациями интерфейса Map в Java, оба позволяют хранить пары ключ-значение и обеспечивают быстрый доступ к элементам за O(1) и O(log n) времени соответственно.
Основное отличие между HashMap и TreeMap заключается в том, что HashMap не гарантирует порядок элементов, в то время как TreeMap поддерживает упорядоченный список элементов по ключу, основанный на естественном порядке сортировки или порядке, определяемом пользователем через реализацию интерфейсов Comparable или Comparator. HashMap реализована с помощью хеширования, тогда как TreeMap использует красно-черное дерево для хранения элементов.
Доступ к элементам в HashMap происходит быстрее, чем в TreeMap, но порядок элементов не гарантирован, а ассимптотическая сложность удаления и вставки элементов в HashMap в худшем случае O(n), хотя в большинстве случаев это O(1). TreeMap гарантирует логарифмическую асимптотическую сложность для поиска, удаления и вставки элементов за счет своей структуры хранения и поддержки упорядоченного списка элементов.
Если нам нужно упорядочить элементы по ключу, то TreeMap будет лучшим выбором, в противном случае использование HashMap является более эффективным выбором.
Что касается времени доступа к объектам, в общем случае время доступа и добавления элементов в HashMap и TreeMap относительно одинаковое и зависит от размера коллекции. Однако, в TreeMap операции прохода по коллекции и удаления элементов могут занимать больше времени из-за того, что TreeMap должен сохранять свой порядок.
803. Что такое Hashtable, чем она отличается от HashMap? На сегодняшний день она deprecated, как все-таки использовать нужную функциональность?
Hashtable и HashMap - это две разные имплементации интерфейса Map в Java. Hashtable появилась в Java 1.0, а HashMap - в Java 1.2. Основное отличие между ними заключается в том, что Hashtable является потокобезопасной структурой данных, что означает, что ее методы синхронизированы и ее можно использовать в нескольких потоках одновременно без риска возникновения проблем с параллельным доступом. Однако, это может замедлять работу программы и создавать лишние накладные расходы в случае, если этой функциональности не требуется.
Следует отметить, что на сегодняшний день Hashtable является устаревшей и не рекомендуется к использованию. Вместо нее стоит использовать ConcurrentHashMap, который также является потокобезопасной каратой, но более эффективно реализован по сравнению с Hashtable. А для непотокобезопасных задач стоит использовать HashMap.
Кроме того, можно использовать связку коллекций и методов из пакета java.util.concurrent в зависимости от требований конкретной задачи для достижения наилучшей производительности.
Пример использования ConcurrentHashMap:
Map<String, String> myMap = new ConcurrentHashMap<>();
myMap.put("key", "value");
String value = myMap.get("key");
Пример использования HashMap:
Map<String, String> myMap = new HashMap<>();
myMap.put("key", "value");
String value = myMap.get("key");
804. Что будет, если в Map положить два значения с одинаковым ключом?
Если в Map положить два значения с одинаковым ключом, то первое значение будет заменено вторым. При этом, если метод put() будет вызван второй раз с тем же ключом, то ключ будет обновлен со значением, переданным вторым аргументом.
Например, рассмотрим следующий код на Java:
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("apple", 3);
System.out.println(map.get("apple")); // выведет 3
Здесь мы создали HashMap и поместили в него две пары ключ-значение. Затем мы обновили значение, связанное с ключом "apple", вызвав метод put() еще раз с этим же ключом. В результате, выводится значение 3, поскольку ключ "apple" был перезаписан со значением 3.
Если же ключи будут различаться, то в Map будут храниться пары уникальных ключей и значений, каждый из которых можно будет получить при обращении к соответствующему ключу.
805. Как задается порядок следования объектов в коллекции, как отсортировать коллекцию?
Для задания порядка следования объектов в коллекции можно использовать интерфейс java.util.Comparable. Этот интерфейс имеет метод compareTo(), который определяет порядок следования элементов. Если вы хотите отсортировать коллекцию на основе этого порядка, вы можете использовать метод Collections.sort().
Если нужна более гибкая сортировка, можно использовать интерфейс java.util.Comparator. Этот интерфейс позволяет определить более сложные правила сортировки, например, с помощью нескольких критериев сортировки или сортировки в обратном порядке.
Вот примеры:
- Сортировка с использованием Comparable:
public class MyClass implements Comparable<MyClass> {
private int value;
public MyClass(int value) {
this.value = value;
}
public int compareTo(MyClass other) {
return Integer.compare(this.value, other.value);
}
}
Затем можно отсортировать список объектов MyClass с помощью метода Collections.sort():
List<MyClass> list = new ArrayList<>();
list.add(new MyClass(3));
list.add(new MyClass(1));
list.add(new MyClass(2));
Collections.sort(list);
Сортировка с использованием Comparator:
public class MyComparator implements Comparator<MyClass> {
public int compare(MyClass a, MyClass b) {
return Integer.compare(a.getValue(), b.getValue());
}
}
Используйте Collections.sort() для сортировки списка объектов MyClass с помощью этого компаратора:
List<MyClass> list = new ArrayList<>();
list.add(new MyClass(3));
list.add(new MyClass(1));
list.add(new MyClass(2));
Collections.sort(list, new MyComparator());
Если нет необходимости переопределять compareTo() в классе элементов коллекции, нет смысла создавать отдельный класс компаратора. Можно воспользоваться методом Collections.sort()
806. Дайте определение понятию “итератор”.
На Java, итераторы представляют собой механизм доступа к элементам коллекции без необходимости знать ее внутреннюю реализацию. Итератор позволяет проходить по коллекции последовательно и удалять элементы во время итерации. Он имеет три основных метода: hasNext(), next(), remove(). Метод hasNext() возвращает true, если есть следующий элемент в коллекции, который может быть прочитан методом next(). В свою очередь, метод next() возвращает следующий элемент и переходит к следующему. Метод remove() удаляет последний элемент, который был возвращен методом next() и удаляет его из коллекции. Итераторы являются частью Java Collections Framework, который содержит реализации множества различных типов коллекций, таких как списки, множества, словари и очереди. Вот пример использования итератора для прохода по списку и вывода каждого элемента:
List<String> myList = new ArrayList<String>();
myList.add("foo");
myList.add("bar");
myList.add("baz");
Iterator<String> iter = myList.iterator();
while (iter.hasNext()) {
String item = iter.next();
System.out.println(item);
}
Этот код выведет элементы списка в порядке добавления: foo, bar, baz.
807. Какую функциональность представляет класс Collections?
Класс Collections в Java является утилитным классом, предоставляющим различные методы для работы со структурами данных, реализующими интерфейсы Collection, List, Set и Map. Некоторые из этих методов включают сортировку, перетасовку, копирование, заполнение, объединение и другие операции над коллекциями.
Например, метод sort позволяет отсортировать список, реализующий интерфейс List, по возрастанию или убыванию, а метод shuffle перемешивает элементы списка в случайном порядке.
Пример использования метода sort:
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
Collections.sort(list); // Сортировка списка по возрастанию
System.out.println(list); // [1, 2, 3]
Пример использования метода shuffle:
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Collections.shuffle(list); // Перемешивание элементов списка
System.out.println(list); // [2, 3, 1] (результат может быть другим в зависимости от порядка элементов)
808. Как получить не модифицируемую коллекцию?
Чтобы получить неизменяемую коллекцию в Java, вы можете использовать метод Collections.unmodifiedCollection(), предоставляемый классом java.util.Collections. Например, предположим, что у вас есть ArrayList, который вы хотите сделать немодифицируемым:
import java.util.*;
List<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
Collection<String> unmodifiable = Collections.unmodifiableCollection(list);
Теперь неизменяемая коллекция содержит те же элементы, что и коллекция списка, но ее нельзя изменить. Если вы попытаетесь добавить или удалить элементы из неизменяемой коллекции, будет выдано исключение UnsupportedOperationException.
809. Какие коллекции синхронизированы?
В Java в классе Collections есть несколько коллекций, которые могут быть синхронизированы. Эти коллекции являются безопасными для использования в многопоточных приложениях, когда несколько потоков имеют доступ к одним и тем же коллекциям. Некоторые из синхронизированных коллекций в Java включают:
-
ArrayList- существует синхронизированная версия - Collections.synchronizedList(), которая возвращает синхронизированный список. -
LinkedList- также имеет синхронизированную версию - Collections.synchronizedList(). -
Hashtable- этот класс представляет устаревшую, но синхронизированную реализацию интерфейса Map. -
Vector- также представляет устаревшую, но синхронизированную реализацию интерфейса List.
Новые коллекции, такие как ArrayList и HashMap, которые были добавлены в Java, не синхронизированы по умолчанию. Однако, вы можете использовать класс Collections.synchronizedList() для создания синхронизированных версий этих коллекций.
810. Как получить синхронизированную коллекцию из не синхронизированной?
Чтобы получить синхронизированную коллекцию из несинхронизированной в Java, можно использовать методы класса Collections. Например, чтобы получить синхронизированный список из несинхронизированного, можно использовать метод synchronizedList:
List<String> unsynchronizedList = new ArrayList<>();
List<String> synchronizedList = Collections.synchronizedList(unsynchronizedList);
Аналогично можно получить синхронизированные версии Set и Map, используя методы synchronizedSet и synchronizedMap. Вот полный пример:
List<String> unsynchronizedList = new ArrayList<>();
List<String> synchronizedList = Collections.synchronizedList(unsynchronizedList);
Set<String> unsynchronizedSet = new HashSet<>();
Set<String> synchronizedSet = Collections.synchronizedSet(unsynchronizedSet);
Map<String, Integer> unsynchronizedMap = new HashMap<>();
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(unsynchronizedMap);
811. Как получить коллекцию только для чтения?
Чтобы получить неизменяемую (только для чтения) коллекцию в Java, можно использовать методы из класса Collections. Например, для создания неизменяемого списка можно использовать метод Collections.unmodifiableList(), для создания неизменяемого множества - Collections.unmodifiableSet(), и т.д. Здесь пример создания неизменяемого списка:
List<String> originalList = new ArrayList<>();
originalList.add("one");
originalList.add("two");
originalList.add("three");
List<String> unmodifiableList = Collections.unmodifiableList(originalList);
После этого unmodifiableList будет неизменяемым, то есть любые попытки изменить его содержимое приведут к генерации исключения UnsupportedOperationException. Чтобы получить неизменяемую коллекцию из какой-то другой коллекции, можно использовать метод unmodifiableXXX() из класса Collections:
List<String> originalList = new ArrayList<>();
originalList.add("one");
originalList.add("two");
originalList.add("three");
List<String> unmodifiableList = Collections.unmodifiableList(originalList);
Set<String> originalSet = new HashSet<>(originalList);
Set<String> unmodifiableSet = Collections.unmodifiableSet(originalSet);
812. Почему Map не наследуется от Collection?
Map в Java не наследуется от Collection, потому что она не является коллекцией в смысле хранения и управления группой объектов. Map является отображением, которое связывает каждый ключ со своим значением, поэтому обычные операции над коллекциями, такие как добавление, удаление и поиск, не работают для Map в том же самом контексте. Вместо этого Map имеет свои уникальные методы, такие как put() и get(), которые позволяют добавлять и получать значения, связанные с определенными ключами. Таким образом, Map является своего рода контейнером, но не реализует интерфейс Collection и не является его подклассом.
813. В чем разница между Iterator и Enumeration?
Iterator и Enumeration - это два интерфейса в Java для перебора элементов в коллекциях.
Основное отличие между Iterator и Enumeration заключается в возможности удаления элемента во время перебора коллекции. Итератор позволяет удалить элемент, который был возвращен последним вызовом next(). Enumeration не позволяет удалять элементы, а также не имеет метода forEachRemaining(), который позволяет выполнить операцию для каждого оставшегося элемента коллекции.
Другое отличие между Iterator и Enumeration заключается в том, что Iterator предоставляет более безопасное и эффективное итерирование по элементам коллекции, чем Enumeration, и может быть использован совместно со многими коллекциями (ArrayList, LinkedList, HashSet и т. д.), в то время как Enumeration ограничен на некоторых коллекциях (Hashtable и Vector).
- Пример использования Iterator в Java:
List<String> myCollection = new ArrayList<>();
// добавление элементов в коллекцию
Iterator<String> it = myCollection.iterator();
while (it.hasNext()) {
String element = it.next();
// обработка элемента
}
- Пример использования Enumeration в Java:
Vector<String> myVector = new Vector<>();
// добавление элементов в вектор
Enumeration<String> en = myVector.elements();
while (en.hasMoreElements()) {
String element = en.nextElement();
// обработка элемента
}
814. Как реализован цикл foreach?
В Java цикл foreach также называется циклом "for-each". Этот цикл используется для перебора элементов массивов или коллекций без явного указания индекса. Вот пример использования цикла for-each для перебора элементов массива:
int[] nums = {1, 2, 3, 4, 5};
for (int num : nums) {
System.out.println(num);
}
Этот код выведет на консоль числа от 1 до 5.
Этот же цикл можно использовать для перебора элементов коллекций, например ArrayList:
ArrayList<String> names = new ArrayList<>();
names.add("Alice");
names.add("Bob");
names.add("Charlie");
for (String name : names) {
System.out.println(name);
}
Этот код выведет на консоль имена Alice, Bob и Charlie.
Цикл for-each не подходит для тех случаев, когда необходим доступ к индексу элемента или когда нужно изменять элементы коллекции внутри цикла. В этих случаях лучше использовать обычный цикл for.
Вот некоторые примеры использования цикла foreach в Java для массива и коллекции:
Пример для массива:
int[] arr = {1, 2, 3, 4, 5};
for (int num : arr) {
System.out.println(num);
}
Пример для коллекции:
List<String> list = new ArrayList<>();
list.add("foo");
list.add("bar");
for (String str : list) {
System.out.println(str);
}
Здесь переменная num принимает значение каждого элемента массива arr по порядку, а переменная str принимает значение каждого элемента коллекции list по порядку. Вы можете использовать эти переменные для выполнения каких-либо операций с каждым элементом.
815. Почему нет метода iterator.add() чтобы добавить элементы в коллекцию?
В интерфейсе java.util.Iterator нет метода add(), так как это лишь итератор для прохода по элементам коллекции, и его задача заканчивается на чтении элементов. Если вам нужно добавить элементы в коллекцию, используйте соответствующие методы коллекции, такие как add() для списков List или HashSet, или put() для карт Map. Пример использования метода add():
List<String> list = new ArrayList<>();
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String element = it.next();
if (someCondition) {
list.add(newElement); // Ошибка ConcurrentModificationException, вызванная перебором и модификацией внутри оного
}
}
list.add(newElement); вызовет ошибку ConcurrentModificationException, так как мы не можем изменять коллекцию во время итерации по ней.
Если вы хотите добавить элементы в коллекцию, в то время как вы перебираете её элементы, используйте ListIterator, который содержит метод add() для этой цели. Вы можете получить ListIterator, вызвав метод listIterator() на списке:
List<String> list = new ArrayList<>();
ListIterator<String> it = list.listIterator();
while (it.hasNext()) {
String element = it.next();
if (someCondition) {
it.add(newElement); // Добавление элемента в список, вызов не вызовет ConcurrentModificationException
}
}
816. Почему в классе iterator нет метода для получения следующего элемента без передвижения курсора?
В Java интерфейс Iterator не предоставляет метода для получения следующего элемента без передвижения курсора. Это сделано намеренно, чтобы гарантировать, что каждый элемент коллекции обрабатывается ровно один раз. Если бы был такой метод, он мог бы привести к непредсказуемости в обходе коллекции и возможным ошибкам. Вместо этого, для проверки следующего элемента используется метод hasNext(), а для получения следующего элемента используется next(), который одновременно передвигает курсор на следующий элемент в коллекции и возвращает его значение.
817. В чем разница между Iterator и ListIterator?
Iterator и ListIterator являются интерфейсами в Java Collections Framework, которые обеспечивают способ перебора коллекции объектов. Однако ListIterator является подтипом Iterator и предоставляет дополнительные функции, которых нет у Iterator.
Вот некоторые ключевые различия между Iterator и ListIterator:
- Iterator можно использовать для обхода любой коллекции, тогда как ListIterator можно использовать только с реализациями List, такими как ArrayList, LinkedList и т. д.
- Iterator можно использовать для обхода элементов только в прямом направлении, а ListIterator может перемещать элементы как в прямом, так и в обратном направлении.
- ListIterator предоставляет дополнительные методы, такие как previous(), hasPrevious(), add(), set() и remove(), которых нет в Iterator.
Таким образом, если вам нужно пройти по списку как в прямом, так и в обратном направлении, или если вам нужно добавить, удалить или изменить элементы во время итерации по списку, вы должны использовать ListIterator. В противном случае используйте итератор.
Вот пример использования Iterator и ListIterator:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class IteratorExample {
public static void main(String[] args) {
List<String> names = new ArrayList<>();
names.add("John");
names.add("Mary");
names.add("Bob");
names.add("Sarah");
// Example of using an Iterator
Iterator<String> iterator = names.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
// Example of using a ListIterator
ListIterator<String> listIterator = names.listIterator(names.size());
while (listIterator.hasPrevious()) {
System.out.println(listIterator.previous());
}
}
}
В этом примере мы сначала создаем список имен, а затем используем итератор для обхода элементов в списке в прямом направлении. Затем мы используем ListIterator для обхода элементов списка в обратном направлении.
818. Какие есть способы перебора всех элементов List?
В Java есть несколько способов перебора всех элементов списка (List):
Цикл for:
List<String> list = Arrays.asList("one", "two", "three");
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
Цикл for each:
List<String> list = Arrays.asList("one", "two", "three");
for(String str : list) {
System.out.println(str);
}
Итератор:
List<String> list = Arrays.asList("one", "two", "three");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
Использование метода forEach():
List<String> list = new ArrayList<>();
list.add("один");
list.add("два");
list.add("три");
list.forEach((element) -> {
System.out.println(element);
});
Каждый из этих способов имеет свои преимущества и недостатки, в зависимости от ситуации. Например, цикл for обычно быстрее работает, чем итератор, но итератор можно использовать для удаления элементов списка во время итерации. выбор способа перебора зависит от конкретной задачи.
819. В чем разница между fail-safe и fail-fast свойствами?
В Java fail-fast и fail-safe свойства относятся к итераторам коллекций.
Fail-fast свойство позволяет выявить ошибки в многопоточных приложениях, где несколько потоков могут изменять одну и ту же коллекцию одновременно. При возникновении такой ситуации итератор бросает исключение ConcurrentModificationException. Fail-fast итераторы работают быстрее, тем самым уменьшая затраты на синхронизацию.
Fail-safe свойство заключается в том, что итератор создает копию коллекции и работает с ней. Таким образом, он гарантирует, что возвращаемые им элементы верны на момент создания итератора. Это свойство не бросает исключений при изменении коллекции другим потоком, так как она остается в неизменном состоянии. Однако это может привести к неактуальным данным, если коллекция продолжает изменяться в других потоках.
В общем случае, fail-fast итераторы предпочтительнее, так как они позволяют выявлять ошибки в работе с коллекциями раньше. Однако, если ваша программа не требует таких проверок или работает с потоками без изменения коллекции, fail-safe итератор может быть более подходящим выбором.
820. Что делать, чтобы не возникло исключение ConcurrentModificationException?
Чтобы избежать исключения ConcurrentModificationException в Java, необходимо использовать правильный подход при итерировании коллекций. Исключение возникает, когда коллекция изменяется во время итерации. Для этого есть несколько вариантов решения:
- Использовать итератор вместо цикла for-each. Итератор позволяет удалять элементы коллекции без возникновения исключения:
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
if (item.equals("somevalue")) {
iterator.remove();
}
}
- Использовать копию коллекции для итерации, если изменения необходимы только в оригинальной коллекции:
List<String> copyList = new ArrayList<>(originalList);
for (String item : copyList) {
if (item.equals("somevalue")) {
originalList.remove(item);
}
}
- Использовать конкурентные коллекции, такие как ConcurrentLinkedQueue или ConcurrentHashMap, которые позволяют изменять коллекцию без блокировки ее состояния:
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
queue.add("value1");
queue.add("value2");
for (String item : queue) {
if (item.equals("value1")) {
queue.remove(item);
}
}
Кроме того, можно синхронизировать доступ к коллекции, чтобы избежать ее изменения во время итерации. Но этот способ может привести к проблемам с производительностью, поэтому лучше использовать решения, представленные выше.
821. Что такое стек и очередь, расскажите в чем их отличия?
Стек и очередь - это два базовых структурных элемента данных в программировании, которые являются взаимопротивоположными. Они имеют разные свойства и применяются в разных ситуациях. Основная разница между стеком и очередью заключается в порядке, в котором элементы добавляются и извлекаются.
Стек - это коллекция элементов данных, которые сохраняются в порядке "последний вошел - первый вышел" (LIFO). Это означает, что последний элемент, добавленный в стек, будет первым, который будет удален из стека. Операции, доступные для стека, обычно ограничены добавлением нового элемента и удалением наиболее недавно добавленного элемента. Стек широко используется для решения задачи обхода деревьев, генерации парсеров, решения задач в обработке синтаксических конструкций.
Очередь - это коллекция элементов данных, которые сохраняются в соответствии с принципом "первый вошел, первый вышел" (FIFO). Это означает, что первый элемент, добавленный в очередь, будет первым, который будет удален из очереди. Операции, доступные для очереди, обычно ограничены добавлением новых элементов и удалением элементов из начала очереди. Очередь используется в различных задачах, включая управление процессами в операционных системах и реализацию алгоритмов BFS (обход в ширину) в Графах.
822. В чем разница между интерфейсами Comparable и Comparator?
В Java интерфейсы Comparable и Comparator позволяют определить порядок сортировки объектов. Однако, эти интерфейсы используются в разных ситуациях и имеют разные подходы.
Comparable - интерфейс, который реализуется классом, который нужно сравнивать. Этот интерфейс имеет один метод compareTo(), который принимает другой объект того же типа и возвращает целое число. Это число указывает, нужно ли считать текущий объект больше, меньше или равным переданному объекту. Пример: если нужно отсортировать массив строк в алфавитном порядке, то можно реализовать Comparable в классе String, так что строки будут сравниваться по значению символов.
Comparator - интерфейс, который реализуется для сравнения двух объектов другого класса. Этот интерфейс имеет один метод compare(), который принимает два объекта и возвращает целое число. Это число указывает, нужно ли считать первый объект больше, меньше или равным второму объекту. Пример: если нужно отсортировать список пользователей по возрасту, можно реализовать Comparator в классе User, чтобы объекты сравнивались по возрастному значению.
В целом, интерфейс Comparable используется для определения естественного порядка элементов класса (например, числа можно сравнить по значению), а интерфейс Comparator используется для сравнения элементов разных классов или для определения альтернативного способа сравнения внутри класса (например, строки можно сравнить по длине).
823. Почему коллекции не наследуют интерфейсы Cloneable и Serializable?
В Java коллекции не наследуют интерфейсы Cloneable и Serializable, потому что это может привести к проблемам с безопасностью и управлением памятью. Эти интерфейсы используются для создания копий объектов и сериализации их в байтовый поток соответственно. Когда коллекция реализует эти интерфейсы, она становится уязвимой к непреднамеренным копированиям и сериализации, что может привести к ошибкам и неожиданным поведениям в программе. Это может быть особенно проблематично при работе с распределенными системами и сериализации данных. Вместо этого коллекции в Java предпочитают создавать свои собственные методы копирования и сериализации, ориентированные на конкретные нужды этих коллекций.
Cloneable - это маркерный интерфейс, который используется для указания того, что объект может быть клонирован. Если вы хотите клонировать объект коллекции в Java, вы должны вызвать метод clone(), который определен в классе Object. Метод этот имеет защищенный доступ, и может быть переопределен только в классе, который поддерживает клонирование.
Что касается интерфейса Serializable, то он используется для маркировки классов, которые могут быть сохранены в потоке данных. Классы, реализующие этот интерфейс, могут быть сериализованы, т.е. преобразованы в поток байтов, которые могут быть сохранены на диске или переданы по сети.
Таким образом, хотя Java-коллекции не наследуют явно интерфейсы Cloneable и Serializable, они все же могут быть клонированы и сериализованы благодаря тому, что предоставляют соответствующие методы.
824. Что такое «коллекция»?
В Java коллекция (collection) представляет собой объект, который хранит набор других объектов, называемых элементами коллекции. Коллекции используются для удобного и эффективного хранения, обработки и манипулирования группами объектов.
Java предоставляет несколько интерфейсов коллекций, таких как List, Set, Queue и Map, которые определяют различные типы коллекций с разными свойствами и методами. Например, List представляет собой упорядоченную коллекцию элементов, а Set - неупорядоченную коллекцию, в которой каждый элемент уникален.
Кроме того, Java также предоставляет классы-реализации для каждого из этих интерфейсов, такие как ArrayList, HashSet и TreeMap, которые предоставляют конкретную реализацию соответствующего интерфейса коллекций.
825. Назовите основные интерфейсы JCF и их реализации.
Основные интерфейсы Java Collections Framework (JCF) и их реализации включают:
Интерфейс List- представляет упорядоченный список, который может содержать дубликаты элементов. Его основные реализации: ArrayList, LinkedList, Vector.Интерфейс Set- представляет неупорядоченный набор уникальных элементов. Его основные реализации: HashSet, LinkedHashSet, TreeSet.Интерфейс Queue- представляет очередь, обеспечивающую доступ к элементам в порядке FIFO (First In First Out). Его основные реализации: PriorityQueue, LinkedList.Интерфейс Deque- представляет двустороннюю очередь, которая позволяет добавлять и удалять элементы как с начала, так и с конца очереди. Его основные реализации: ArrayDeque, LinkedList.Интерфейс Map- представляет отображение ключей на значения. Его основные реализации: HashMap, LinkedHashMap, TreeMap.
Кроме того, JCF также включает несколько вспомогательных интерфейсов, таких как Iterable, Collection, Iterator и другие, которые используются для работы с коллекциями.
826. Расположите в виде иерархии следующие интерфейсы: List, Set, Map, SortedSet, SortedMap, Collection, Iterable, Iterator, NavigableSet, NavigableMap.
-
Iterable
-
Collection
-
- List
-
- Set
-
-
- SortedSet
-
-
- Queue
-
-
- Deque
-
-
-
-
- NavigableSet
-
-
-
- Map
-
-
- SortedMap
-
-
-
- NavigableMap
-
-
Iterator
Здесь каждый интерфейс расположен ниже более общего, а также указаны специализированные версии сортированных коллекций и навигационных множеств и карт. Интерфейс Iterable и его реализация позволяют перебирать элементы коллекции при помощи итераторов (Iterator).
827. Почему Map — это не Collection, в то время как List и Set являются Collection?
Map - это абстрактный тип данных, который представляет собой отображение ключей на значения. В отличие от коллекций, которые хранят только объекты и позволяют получать к ним доступ по индексам или итерироваться по ним, Map хранит пары "ключ-значение", где каждый ключ связан с соответствующим ему значением.
Таким образом, Map не является коллекцией, потому что не хранит просто набор элементов, а структуру данных, которая предназначена для быстрого поиска элемента по ключу. В то время как коллекции управляются интерфейсами Collection и Iterable, Map управляется интерфейсами Map и SortedMap (если требуется сортировка).
List и Set, напротив, являются коллекциями, потому что они хранят набор элементов, которые могут быть получены по индексам (в случае List) или без индексов, но с гарантией уникальности (в случае Set). Они также могут быть перебраны в цикле при помощи интерфейса Iterable и его реализаций.
Таким образом, различие между Map и коллекциями заключается в том, что Map хранит пары "ключ-значение", а коллекции хранят просто набор элементов.
828. В чем разница между классами java.util.Collection и java.util.Collections?
Класс java.util.Collection является интерфейсом, который определяет общие методы для всех коллекций. Это означает, что все классы, которые реализуют этот интерфейс (например, List, Set и Queue), должны реализовать его методы.
Класс java.util.Collections, с другой стороны, предоставляет утилитарные методы для работы с коллекциями. Это статический класс, который содержит методы для сортировки, перемешивания, копирования, заполнения и других манипуляций с элементами коллекций.
Следовательно, разница между классами Collection и Collections заключается в том, что первый определяет общие методы, которые должны реализовываться всеми коллекциями, а второй предоставляет набор утилитарных методов для работы с коллекциями.
Например, чтобы отсортировать List, нужно вызвать метод sort() из класса Collections, который принимает список в качестве параметра. В то же время, метод add() из интерфейса Collection можно вызывать на любом объекте, который реализует этот интерфейс (например, на ArrayList или HashSet).
829. Что такое «fail-fast поведение»?
Fail-fast поведение - это механизм, используемый в Java для обнаружения изменений в коллекции, которые были выполнены "неправильно", и генерации исключений ConcurrentModificationException.
Fail-fast поведение возникает, когда коллекция реализует итератор, который используется для перебора элементов коллекции. Если в процессе итерирования коллекции какой-то другой код изменяет структуру коллекции (например, добавляет или удаляет элементы), то итератор обнаруживает эти изменения и бросает исключение ConcurrentModificationException.
Такое поведение необходимо, чтобы предотвратить несогласованность данных в коллекции и избежать ошибок при ее использовании. Вместо того, чтобы позволять неправильным изменениям приводить к неопределенным результатам, fail-fast механизм быстро обнаруживает такие изменения и генерирует исключение, чтобы предупредить программиста о проблеме.
Важно отметить, что fail-fast поведение является свойством конкретной реализации коллекции, а не интерфейса Collection. Некоторые реализации коллекций, например, ConcurrentHashMap или CopyOnWriteArrayList, не поддерживают fail-fast поведение и могут быть изменены во время итерации без генерации исключений.
830. Какая разница между fail-fast и fail-safe?
Fail-fast и fail-safe - это два подхода к обработке изменений в коллекциях, которые происходят во время итерации.
Fail-fast механизм предполагает, что если коллекция была изменена во время итерации, то итератор должен сигнализировать об этом немедленно, через генерацию исключения ConcurrentModificationException. Это поведение дает возможность быстро обнаруживать ошибки и предотвращать несогласованность данных в коллекции.
С другой стороны, fail-safe механизм предполагает, что итератор не будет генерировать исключения при изменении коллекции во время итерации. Вместо этого он работает с "копией" коллекции, создавая ее в начале итерации, и используя ее для перебора элементов. Таким образом, любые изменения, выполненные в "оригинальной" коллекции во время итерации, не будут отражаться в "копии", поэтому итерация не будет прерываться и не будет генерироваться исключение.
В Java, большинство коллекций являются fail-fast, но есть несколько коллекций, таких как ConcurrentHashMap и CopyOnWriteArrayList, которые являются fail-safe.
Таким образом, основная разница между fail-fast и fail-safe заключается в том, что первый обнаруживает изменения в коллекции и генерирует исключение, а второй работает с копией коллекции и не генерирует исключений при изменении оригинальной коллекции.
831. Приведите примеры итераторов реализующих поведение fail-safe
Некоторые примеры итераторов, реализующих поведение fail-safe, включают:
Итератор CopyOnWriteArrayList - это итератор для класса CopyOnWriteArrayList, который создает копию списка на момент создания итератора. В результате он не видит изменений, которые были выполнены после создания итератора.
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
Iterator<String> it = list.iterator();
list.add("first");
it.next(); // вернет "first"
list.add("second");
it.next(); // все еще вернет "first"
Итератор ConcurrentHashMap - это итератор для класса ConcurrentHashMap, который работает с консистентным состоянием карты во время итерации. Таким образом, он не будет видеть изменений, которые были выполнены после создания итератора.
ConcurrentHashMap<String,String> map = new ConcurrentHashMap<>();
map.put("key1", "value1");
Iterator<String> it = map.keySet().iterator();
map.put("key2", "value2");
while(it.hasNext()) {
System.out.println(it.next()); // выведет только "key1"
}
Общая идея fail-safe итераторов заключается в том, что они создают копию коллекции на момент создания итератора или используют другие механизмы для обеспечения безопасности итерирования в случае изменения коллекции. Это позволяет избежать генерации исключения ConcurrentModificationException и обеспечивает безопасную итерацию коллекции во время изменений.
832. Чем различаются Enumeration и Iterator.
Enumeration и Iterator представляют два различных способа перебора элементов в коллекциях.
Enumeration - это интерфейс, который был добавлен в Java в более ранних версиях (до JDK 1.2) для перебора элементов в коллекциях. Он определяет методы, позволяющие перебирать только элементы списка и не позволяет изменять коллекцию в процессе перебора. Enumeration также не содержит метода удаления элемента из коллекции.
Iterator, с другой стороны, является новым интерфейсом, появившимся в JDK 1.2, и он предоставляет более функциональные возможности для работы с коллекциями. Iterator также позволяет удалить элемент из коллекции во время итерации, что делает его более гибким для использования.
Основные различия между Enumeration и Iterator заключаются в следующем:
- Итератор (Iterator) поддерживает операцию удаления элемента из коллекции во время итерации, тогда как Enumeration этого не поддерживает.
- Итератор (Iterator) более безопасен, чем Enumeration, потому что он проверяет наличие доступных элементов перед вызовом метода next(), а Enumeration не делает этого и может выбросить NoSuchElementException при вызове метода next().
- Кроме того, методы Enumeration были объявлены устаревшими в Java 1.0 и были заменены методами Iterator.
Таким образом, основное различие между Enumeration и Iterator заключается в том, что Iterator более гибкий и функциональный, чем Enumeration, и позволяет безопасно использовать операцию удаления элементов из коллекции во время итерации.
833. Как между собой связаны Iterable и Iterator?
Iterable и Iterator - это два интерфейса, которые связаны друг с другом в Java.
Интерфейс Iterable определяет метод iterator(), который возвращает объект типа Iterator. Таким образом, любой класс, который реализует интерфейс Iterable, должен предоставлять метод iterator(), который вернет объект типа Iterator.
Iterator, с другой стороны, определяет методы для перебора элементов коллекции. Он предоставляет три основных метода: hasNext() - проверяет наличие следующего элемента, next() - возвращает следующий элемент, и remove() - удаляет текущий элемент из коллекции.
Таким образом, когда мы вызываем метод iterator() на объекте, который реализует интерфейс Iterable, мы получаем объект типа Iterator, который можно использовать для перебора элементов этой коллекции.
Далее, при помощи методов hasNext() и next() из интерфейса Iterator мы можем получать следующий элемент коллекции и проверять, есть ли еще доступные элементы. Если мы хотим удалить элемент из коллекции во время итерации, мы можем использовать метод remove() из интерфейса Iterator.
Оба этих интерфейса объединяются вместе, чтобы обеспечить эффективную итерацию коллекций в Java. Итераторы используются для работы с элементами коллекций, а интерфейс Iterable дает нам возможность получить итератор для этой коллекции.
834. Как между собой связаны Iterable, Iterator и «for-each»?
В Java, Iterable, Iterator и "for-each" работают вместе, чтобы обеспечить эффективную итерацию коллекций.
Интерфейс Iterable определяет метод iterator(), который возвращает объект типа Iterator. Этот метод используется для получения итератора для перебора элементов коллекции.
Iterator, в свою очередь, предоставляет три основных метода: hasNext(), next() и remove(). hasNext() используется для проверки наличия следующего элемента в коллекции, next() - для получения следующего элемента, а remove() - для удаления текущего элемента из коллекции.
С помощью цикла "for-each" мы можем легко перебирать элементы коллекции, не используя явно итератор. Цикл "for-each" самостоятельно вызывает метод iterator() из интерфейса Iterable для получения итератора и затем использует методы hasNext() и next() из интерфейса Iterator для перебора элементов коллекции. Пример:
List<String> list = new ArrayList<String>();
list.add("one");
list.add("two");
list.add("three");
// Используем цикл for-each для вывода всех элементов списка
for(String element : list) {
System.out.println(element);
}
Таким образом, Iterable, Iterator и "for-each" работают вместе, чтобы предоставить простой и эффективный способ перебора элементов коллекции в Java. Они позволяют работать с коллекциями любого типа, который реализует интерфейс Iterable, и обеспечивают безопасную итерацию коллекций во время изменений.`
835. Сравните Iterator и ListIterator.
Iterator и ListIterator - это два интерфейса Java, которые предоставляют различные методы для перебора элементов в коллекциях.
Iterator - это интерфейс для перебора элементов в коллекции. Он определяет три основных метода: hasNext(), next() и remove(). hasNext() используется для проверки наличия следующего элемента в коллекции, next() используется для получения следующего элемента, а remove() может быть использован для удаления текущего элемента из коллекции.
ListIterator, с другой стороны, является расширением интерфейса Iterator для списков (List). Он также определяет те же три основных метода, что и Iterator, но добавляет еще несколько дополнительных методов для более эффективного перебора элементов списка. Например, ListIterator позволяет проходить по списку в обратном направлении и вставлять элементы в список во время итерации.
Основные различия между Iterator и ListIterator:
- ListIterator работает только со списками (List), тогда как Iterator может использоваться для перебора элементов любых коллекций.
- ListIterator поддерживает операцию перебора списка в обратном направлении, в то время как Iterator не поддерживает эту операцию.
- ListIterator предоставляет метод add(), который позволяет вставлять новый элемент в список во время итерации, тогда как Iterator только позволяет удалять элементы из списка.
- ListIterator предоставляет дополнительный метод previous(), который возвращает предыдущий элемент списка.
Таким образом, основное различие между Iterator и ListIterator заключается в том, что ListIterator является расширением Iterator для списков (List) и добавляет несколько дополнительных методов для более эффективного перебора элементов списка. Если вы работаете со списками, ListIterator может быть более подходящим выбором, чем обычный Iterator.
836. Что произойдет при вызове Iterator.next() без предварительного вызова Iterator.hasNext()?
Если вызвать метод next() на объекте Iterator без предварительного вызова hasNext(), то может быть выброшено исключение NoSuchElementException.
Метод hasNext() возвращает булевое значение, которое указывает, есть ли следующий элемент в коллекции. Если этот метод вернет false, то вызов метода next() приведет к выбросу исключения NoSuchElementException, потому что следующего элемента не существует.
Поэтому перед вызовом метода next() всегда необходимо проверить наличие следующего элемента в коллекции, используя метод hasNext(). Это гарантирует, что итератор не будет вызывать метод next() для несуществующего элемента в коллекции, что приведет к выбросу исключения.
Пример:
List<String> list = Arrays.asList("one", "two", "three");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
System.out.println(element);
}
В этом примере мы сначала вызываем метод hasNext() для проверки наличия следующего элемента, а затем вызываем метод next() для получения следующего элемента. Это гарантирует, что метод next() не будет вызываться для несуществующего элемента в коллекции.
837. Сколько элементов будет пропущено, если Iterator.next() будет вызван после 10-ти вызовов Iterator.hasNext()?
Если метод next() вызывается после 10 вызовов метода hasNext(), то будет возвращен элемент, следующий за 10-м элементом в коллекции.
При каждом вызове метода hasNext(), итератор проверяет наличие следующего элемента в коллекции. Если следующий элемент существует, метод hasNext() возвращает true. Если следующий элемент не существует, то метод hasNext() возвращает false.
Когда метод next() вызывается, итератор перемещает свою позицию на следующий элемент в коллекции и возвращает его.
Таким образом, если мы вызвали метод hasNext() 10 раз и он вернул true для каждого вызова, то к моменту вызова метода next() итератор переместится на следующий элемент (11-й элемент) в коллекции, и этот элемент будет возвращен методом next().
Пример:
List<String> list = Arrays.asList("one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten", "eleven");
Iterator<String> iterator = list.iterator();
int count = 0;
while(iterator.hasNext() && count < 10) {
iterator.next();
count++;
}
String nextElement = iterator.next(); // возвратит "eleven"
В этом примере 10 раз вызывается метод hasNext(), а затем метод next() вызывается еще один раз. В результате метод next() вернет элемент "eleven", который является следующим элементом после 10-го элемента в коллекции.
838. Как поведёт себя коллекция, если вызвать iterator.remove()?
Вызов метода remove() на объекте Iterator удаляет текущий элемент коллекции, который был возвращен последним вызовом метода next(). Если метод next() еще не был вызван, либо если метод remove() уже был вызван для текущего элемента, то будет выброшено исключение IllegalStateException.
После удаления элемента итератор перемещается к следующему элементу. Если в коллекции больше нет элементов, то метод hasNext() вернет false.
Когда элемент удаляется из коллекции при помощи метода remove(), коллекция изменяется непосредственно. Однако, если вы пытаетесь удалить элемент напрямую из коллекции, используя методы коллекции, то могут возникнуть проблемы синхронизации.
Пример:
List<String> list = new ArrayList<>(Arrays.asList("one", "two", "three"));
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
if(element.equals("two")) {
iterator.remove(); // удаление элемента "two"
}
}
System.out.println(list); // [one, three]
В этом примере мы создаем список, перебираем его элементы при помощи итератора и удаляем элемент "two". Когда элемент удаляется, он удаляется непосредственно из списка, а оставшиеся элементы сдвигаются на его место.
В результате, если мы выведем содержимое списка после итерации, то увидим список [one, three].
839. Как поведёт себя уже инстанциированный итератор для collection, если вызвать collection.remove()?
Вызов метода remove() на коллекции, когда итератор еще активен, может привести к выбросу исключения ConcurrentModificationException. Это происходит потому, что изменение коллекции во время итерации приводит к несогласованности между состоянием итератора и коллекции. Если метод remove() вызван на коллекции в то время, когда итератор уже активирован, это может привести к изменению коллекции, которую перебирает итератор, что в свою очередь приведет к появлению ошибки.
Если вы хотите удалить элемент из коллекции, в то время как она перебирается при помощи итератора, лучше использовать метод remove() из самого итератора. Такая операция будет корректно синхронизирована и не породит исключение.
Пример:
List<String> list = new ArrayList<>(Arrays.asList("one", "two", "three"));
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String element = iterator.next();
if(element.equals("two")) {
iterator.remove(); // безопасное удаление элемента "two"
}
}
System.out.println(list); // [one, three]
В этом примере мы создаем список, перебираем его элементы при помощи итератора и безопасно удаляем элемент "two" при помощи метода remove() из итератора. В результате, если мы выведем содержимое списка после итерации, то увидим список [one, three].
840. Как избежать ConcurrentModificationException во время перебора коллекции?
ConcurrentModificationException возникает в том случае, когда коллекция изменяется во время итерации. Чтобы избежать этой ошибки, можно использовать следующие методы:
Использовать итератор для удаления элементов из коллекции: при переборе коллекции используйте итератор и вызывайте метод remove() у итератора вместо метода remove() у коллекции. Таким образом, вы избегаете изменения коллекции во время её перебора, что приводит к возникновению исключения.
Создать копию коллекции перед перебором: создайте копию коллекции и перебирайте ее вместо оригинальной коллекции. Это позволяет избежать изменения оригинальной коллекции во время её перебора.
Использовать синхронизацию: синхронизация предотвращает одновременный доступ к коллекции из разных потоков, что может привести к изменению коллекции во время её перебора.
Пример 1- использование итератора для удаления элементов из коллекции:
List<String> list = new ArrayList<>(Arrays.asList("one", "two", "three"));
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("two")) {
iterator.remove(); // безопасное удаление элемента "two"
}
}
Пример 2- создание копии коллекции перед перебором:
List<String> list = new ArrayList<>(Arrays.asList("one", "two", "three"));
List<String> copy = new ArrayList<>(list);
for (String element : copy) {
if (element.equals("two")) {
list.remove(element); // безопасное удаление элемента "two"
}
}
Пример 3- использование синхронизации:
List<String> list = Collections.synchronizedList(new ArrayList<>());
synchronized (list) {
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (element.equals("two")) {
iterator.remove(); // безопасное удаление элемента "two"
}
}
}
В общем, при переборе коллекций необходимо убедиться, что коллекция не изменяется во время её перебора, и использовать способы избежать этой ошибки.
841. Какая коллекция реализует дисциплину обслуживания FIFO?
Дисциплина обслуживания FIFO (First-In-First-Out) означает, что первый элемент, добавленный в коллекцию, будет первым, который будет удален из коллекции. Эта дисциплина обслуживания реализуется в очередях.
Коллекция java.util.Queue представляет собой интерфейс для работы с очередью и реализует дисциплину обслуживания FIFO. Она имеет несколько реализаций, таких как:
java.util.LinkedList: двунаправленный связный список, который реализует интерфейсы List и Queue.java.util.ArrayDeque: двусторонняя очередь на основе массива, которая также реализует интерфейсы List и Queue.java.util.concurrent.LinkedBlockingQueue: неблокирующая очередь на основе связного списка.java.util.concurrent.ArrayBlockingQueue: блокирующая очередь на основе массива, которая имеет фиксированный размер. Пример использования интерфейса Queue:
Queue<String> queue = new LinkedList<>();
queue.offer("first");
queue.offer("second");
queue.offer("third");
String firstElement = queue.poll(); // "first"
String secondElement = queue.poll(); // "second"
String thirdElement = queue.poll(); // "third"
В этом примере мы создаем объект типа LinkedList, который реализует интерфейс Queue. Затем мы добавляем три элемента в очередь при помощи метода offer(). Метод poll() удаляет и возвращает первый элемент в очереди. В результате, если мы выведем значения переменных firstElement, secondElement и thirdElement, то увидим значения "first", "second" и "third", соответственно.
842. Какая коллекция реализует дисциплину обслуживания FILO?
Дисциплина обслуживания FILO (First-In-Last-Out), также известная как LIFO (Last-In-First-Out), означает, что последний элемент, добавленный в коллекцию, будет первым, который будет удален из коллекции. Эта дисциплина обслуживания реализуется в стеках.
Коллекция java.util.Deque представляет собой интерфейс для работы со стеком и реализует дисциплину обслуживания FILO. Она имеет несколько реализаций, таких как:
java.util.LinkedList: двунаправленный связный список, который реализует интерфейсы List и Deque.java.util.ArrayDeque: двусторонняя очередь на основе массива, которая также реализует интерфейсы List и Deque.
Пример использования интерфейса Deque:
Deque<String> stack = new ArrayDeque<>();
stack.push("first");
stack.push("second");
stack.push("third");
String thirdElement = stack.pop(); // "third"
String secondElement = stack.pop(); // "second"
String firstElement = stack.pop(); // "first"
В этом примере мы создаем объект типа ArrayDeque, который реализует интерфейс Deque. Затем мы добавляем три элемента в стек при помощи метода push(). Метод pop() удаляет и возвращает верхний элемент в стеке. В результате, если мы выведем значения переменных firstElement, secondElement и thirdElement, то увидим значения "first", "second" и "third", соответственно.
843. Чем отличается ArrayList от Vector?
ArrayList и Vector - это два класса, которые реализуют список на основе массива. Оба класса имеют сходства, но также есть различия.
Вот некоторые из принципиальных отличий между ArrayList и Vector:
Синхронизация: Vector является потокобезопасным классом, в то время как ArrayList не синхронизирован по умолчанию. Если требуется безопасность потоков при работе со списком, Vector можно использовать без дополнительных мер предосторожности, а ArrayList требует дополнительной синхронизации.Производительность: из-за синхронизации Vector может быть менее производительным, чем ArrayList. В случаях, когда безопасность потоков не является проблемой, ArrayList может быть более эффективным выбором.Размер: Vector увеличивает размер своего внутреннего массива автоматически, если он переполнен, на 100% от текущего размера, в то время как ArrayList увеличивает размер на 50% от текущего размера. Это означает, что векторы могут использовать больше памяти, чем необходимо, в то время как списки могут более часто изменять размер своего внутреннего массива.Итераторы: Vector содержит устаревший метод elements(), который возвращает устаревший Enumeration. В то время как ArrayList использует современный итератор (Iterator) для перебора элементов.
Рекомендации к использованию: Vector рекомендуется использовать, если требуется безопасность потоков или если необходима автоматическая настройка размера массива. В остальных случаях рекомендуется использовать ArrayList.
Пример создания ArrayList и Vector:
List<String> arrayList = new ArrayList<>();
Vector<String> vector = new Vector<>();
В обоих примерах мы создаем пустые списки строковых значений. Если вы хотите использовать список, который должен быть потокобезопасным, используйте Vector. В остальных случаях ArrayList лучше подходит из-за своей производительности.
844. Зачем добавили ArrayList, если уже был Vector?
ArrayList и Vector, как было сказано, оба реализуют список на основе массива. Однако ArrayList был добавлен в JDK 1.2 исходя из требования к более эффективной альтернативе Vector.
Основная причина появления ArrayList заключалась в том, что Vector по умолчанию был потокобезопасным, но это влияло на производительность, так как синхронизация может замедлять работу приложения. В то время как ArrayList не является потокобезопасным по умолчанию, но его можно безопасно использовать в непотокобезопасных ситуациях, что позволяет повысить производительность.
Ещё одной причиной появления ArrayList была возможность уменьшения занимаемой памяти. При копировании вектора для увеличения его размера создавался новый массив, который был на 100% больше предыдущего. Это означало, что вектор мог использовать больше памяти, чем необходимо. В то время как ArrayList увеличивает размер своего внутреннего массива на 50% от текущего размера, что может быть более эффективным способом управления памятью.
Несмотря на эти различия, Vector по-прежнему может быть полезен в некоторых ситуациях, особенно если требуется потокобезопасность или автоматическая настройка размера массива.
845. Чем отличается ArrayList от LinkedList? В каких случаях лучше использовать первый, а в каких второй?
ArrayList и LinkedList - это две разные реализации списка в Java. Оба класса реализуют интерфейс List, но они имеют ряд отличий, которые могут повлиять на производительность и эффективность.
Основные отличия между ArrayList и LinkedList:
Внутреннее представление данных: ArrayList основан на массиве, а LinkedList на связном списке.Доступ к элементам: ArrayList обеспечивает быстрый доступ к элементам по индексу благодаря тому, что он основан на массиве. В то время как LinkedList не обеспечивает быстрого доступа к элементам по индексу, но обеспечивает быструю вставку и удаление элементов из середины списка.Память: ArrayList использует более компактное представление данных, чем LinkedList. Массивы занимают меньше памяти, чем узлы связного списка, поэтому ArrayList может быть менее затратным по памяти.Производительность: операции добавления или удаления элементов в середине списка (LinkedList) могут быть более быстрыми, чем в случае с ArrayList, но операции доступа к элементам по индексу (ArrayList) будут более быстрыми.
Когда использовать ArrayList:
-
Если вам нужен быстрый доступ к элементам по индексу.
-
Если вы часто производите операции чтения из списка, но редко выполняете операции добавления и удаления элементов.
-
Если у вас есть ограниченный объем памяти.
-
Когда использовать LinkedList: -
Если вам нужно часто добавлять или удалять элементы из середины списка.
-
Если у вас нет необходимости часто обращаться к элементам списка по индексу.
-
Если вы не знаете заранее точное количество элементов, которые должны быть в списке.
Пример создания ArrayList и LinkedList:
List<String> arrayList = new ArrayList<>();
List<String> linkedList = new LinkedList<>();
В обоих примерах мы создаем пустые списки строковых значений. Если вы знаете размер списка и вам нужен быстрый доступ к элементам по индексу, ArrayList может быть лучшим выбором. В остальных случаях LinkedList может быть более эффективным.
846. Что работает быстрее ArrayList или LinkedList?
Производительность ArrayList и LinkedList зависит от разных факторов. ArrayList быстрее, если нужен быстрый доступ к элементам по индексу, а LinkedList быстрее вставляет или удаляет элементы в середине списка. Если необходима производительность при выполнении специфических операций, то нужно выбирать соответствующую коллекцию.
Операции доступа к случайному элементу списка (get()) выполняются быстрее в ArrayList, чем в LinkedList. Значения хранятся в массиве в ArrayList, что позволяет быстро найти элемент по индексу. В то время как в LinkedList приходится перебирать все элементы, начиная с головы списка или с конца списка, чтобы найти требуемый элемент. Поэтому, если вы знаете индекс элемента, который вам нужен, лучше использовать ArrayList.
С другой стороны, операции вставки и удаления элементов (add() и remove()) в середине списка работают быстрее в LinkedList, чем в ArrayList. Вставка или удаление элемента в середине списка требует изменения ссылок на предыдущий и следующий элементы. В ArrayList при вставке нового элемента требуется переместить все последующие элементы вправо на один индекс. При удалении элемента также требуется перемещать все последующие элементы влево на один индекс. Поэтому, если вы часто вставляете или удаляете элементы в середине списка, лучше использовать LinkedList.
Также стоит учитывать, что использование ArrayList может быть менее затратным по памяти, так как массивы занимают меньше памяти, чем узлы связного списка, используемые для хранения данных в LinkedList.
В целом, выбор между ArrayList и LinkedList зависит от того, какие операции будут чаще выполняться в вашей программе. Если вы знаете, что будет много операций доступа к элементам по индексу, то лучше выбрать ArrayList. Если же вы будете часто добавлять и удалять элементы из середины списка, то лучше выбрать LinkedList.
847. Какое худшее время работы метода contains() для элемента, который есть в LinkedList?
Худшее время работы метода contains() для элемента, который есть в LinkedList, равно O(n), где n - это размер списка. Это происходит из-за того, что при поиске элемента в списке приходится перебирать каждый элемент списка, начиная с головы или с конца, чтобы найти требуемый элемент.
Таким образом, если список содержит много элементов, то поиск элемента с помощью contains() может занять значительное время. Это может быть проблемой при работе с большими списками или когда нужно осуществлять множество поисковых запросов.
Если часто требуется проверять наличие элемента в списке, то может быть лучше использовать другую структуру данных, например, HashSet или TreeSet. В этих структурах поиск элемента выполняется за время O(1) или O(log n) соответственно, что намного быстрее, чем в случае с LinkedList. Однако, если необходимо сохранять порядок элементов и/или допускаются повторяющиеся значения, то LinkedList может оставаться лучшим выбором.
848. Какое худшее время работы метода contains() для элемента, который есть в ArrayList?
Худшее время работы метода contains() для элемента, который есть в ArrayList, равно O(n), где n - это размер списка. Это происходит из-за того, что при поиске элемента в списке приходится перебирать каждый элемент списка, чтобы найти требуемый элемент.
Таким образом, если список содержит много элементов, то поиск элемента с помощью contains() может занять значительное время. Однако, так как ArrayList основан на массиве, то при поиске элемента можно использовать индексацию, что позволяет сделать поиск быстрее. Если элемент находится в ближайших к началу элементах, то время поиска будет меньше, чем если элемент находится ближе к концу списка.
Кроме того, в ArrayList можно использовать метод indexOf(), который возвращает индекс первого вхождения указанного элемента в список. Этот метод работает аналогично contains(), но возвращает индекс найденного элемента или -1, если элемент не найден. Метод indexOf() использует индексацию массива и может работать быстрее, чем contains().
Если часто требуется проверять наличие элемента в списке, то может быть лучше использовать другую структуру данных, например, HashSet или TreeSet. В этих структурах поиск элемента выполняется за время O(1) или O(log n), что намного быстрее, чем в случае с ArrayList. Однако, если необходимо сохранять порядок элементов и/или допускаются повторяющиеся значения, то ArrayList может оставаться лучшим выбором.
849. Какое худшее время работы метода add() для LinkedList?
Худшее время работы метода add() для LinkedList составляет O(n), где n - это размер списка. При добавлении элемента в конец списка, LinkedList должен пройти через все узлы от головы до хвоста, чтобы найти последний узел и добавить новый элемент после него.
Если нужно добавить элемент в середину списка или в начало списка, то время выполнения add() также может быть O(n), так как LinkedList не поддерживает прямой доступ к элементу по индексу. В этом случае придется перебрать все элементы от головы списка, пока не будет найден нужный индекс, и затем добавить новый элемент в этот индекс.
Таким образом, если требуется добавление элементов только в конец списка, то использование LinkedList может быть эффективным. Но если часто происходит добавление элементов в середину или начало списка, то ArrayList может оказаться более подходящей структурой данных, так как он поддерживает прямой доступ к элементам по индексу, что обеспечивает более быструю вставку в середину или начало списка.
Кроме того, если требуется добавление элементов в списки больших размеров, общее время на добавление элементов в список может быть значительным, особенно если списки содержат множество элементов. В таких случаях имеет смысл использование специальных структур данных, таких как ArrayDeque, которые обеспечивают быстрое добавление и удаление элементов в начале и конце списка, но не поддерживают произвольный доступ к элементам по индексу.
850. Какое худшее время работы метода add() для ArrayList?
Худшее время работы метода add() для ArrayList - это O(n), где n - это размер списка. Это происходит из-за того, что массивы в Java имеют фиксированный размер, и при добавлении нового элемента внутренний массив может переполниться. В этом случае ArrayList создает новый массив большего размера, копирует все существующие элементы в новый массив и только затем добавляет новый элемент в конец.
Этот процесс называется "расширением емкости" (capacity expansion) и может занять значительное время, особенно если список содержит много элементов. Если такая операция выполняется часто, то время выполнения метода add() может быть довольно высоким.
Чтобы избежать частых расширений емкости, можно указать начальный размер списка при его создании с помощью конструктора ArrayList(int initialCapacity). Начальный размер должен быть достаточно большим, чтобы избежать частых расширений емкости, но не слишком большим, чтобы не использовать избыточную память.
Кроме того, если требуется добавление элементов только в конец списка, то использование LinkedList может быть более эффективным, поскольку он не имеет проблем с расширением емкости и может быстро добавлять элементы в конец списка.
Таким образом, если требуется частое добавление элементов в середину списка или изменение размера списка, то ArrayList может быть подходящим выбором. Если же требуется только добавление элементов в конец списка, то использование LinkedList может быть более эффективным.
851. Необходимо добавить 1 млн. элементов, какую структуру вы используете?
Если необходимо добавить 1 млн. элементов, то в зависимости от требований к производительности и способа использования данных можно рассмотреть различные структуры данных.
Если нужно добавлять элементы только в конец списка и делать быстрый доступ к элементам по индексу, то лучше использовать ArrayList. При заданном начальном размере он может быть очень эффективным при добавлении большого количества элементов.
Если же нужно удалять/вставлять элементы из середины списка или если порядок элементов имеет значение, тогда LinkedList может быть более подходящей структурой данных.
Если необходимо быстро проверять наличие элементов в списке без дубликатов, то можно использовать HashSet или TreeSet, которые обеспечивают операции добавления и поиска элементов за время O(1) или O(log n) соответственно.
Также можно рассмотреть использование специализированных структур данных, таких как ArrayDeque, если требуется добавление и удаление элементов в начале и конце списка.
Важно также учитывать требования к памяти и возможность использования её. Так, например, ArrayList может занимать меньше памяти, чем LinkedList, но может потребоваться больше памяти при расширении емкости в процессе добавления элементов. Поэтому, выбор структуры данных зависит от конкретных требований и условий задачи.
852. Как происходит удаление элементов из ArrayList? Как меняется в этом случае размер ArrayList?
Удаление элементов из ArrayList происходит за время O(n), где n - это размер списка.
При удалении элемента из середины списка, все элементы после него смещаются на одну позицию влево для заполнения освободившейся ячейки. Это может быть затратно по времени, так как требуется копирование большого количества элементов.
При удалении элемента из конца списка удаление происходит быстрее, так как нет необходимости копировать элементы. Однако, размер ArrayList не уменьшается автоматически. Размер списка остается тем же, что может привести к неэффективному использованию памяти.
Для изменения размера списка можно использовать метод trimToSize(). Он устанавливает емкость списка равной его текущему размеру, что позволяет освободить память, занятую неиспользуемыми ячейками.
Кроме того, при удалении элементов из ArrayList могут возникнуть проблемы с расширением емкости (capacity expansion). Если список имеет фиксированный размер и при удалении элементов становится менее чем наполовину заполнен, то следует рассмотреть сокращение емкости массива с помощью метода trimToSize(), чтобы избежать избыточного использования памяти.
В целом, при удалении элементов из ArrayList следует учитывать его размер и положение удаляемого элемента в списке, а также необходимость сокращения емкости массива для более эффективного использования памяти.
853. Предложите эффективный алгоритм удаления нескольких рядом стоящих элементов из середины списка, реализуемого ArrayList.
Для удаления нескольких рядом стоящих элементов из середины ArrayList можно использовать следующий алгоритм:
- Определить индекс первого удаляемого элемента и количество удаляемых элементов.
- Скопировать все элементы, начиная с индекса последнего удаляемого элемента + 1, в ячейки, начиная с индекса первого удаляемого элемента.
- Установить значение null для каждой освободившейся ячейки в конце списка.
- Уменьшить размер списка на количество удаленных элементов. Примерный код реализации может выглядеть так:
public static void removeRange(ArrayList<?> list, int fromIndex, int toIndex) {
int numMoved = list.size() - toIndex;
System.arraycopy(list, toIndex, list, fromIndex, numMoved);
int newSize = list.size() - (toIndex - fromIndex);
while (list.size() != newSize) {
list.remove(list.size() - 1);
}
}
В этом коде используется метод System.arraycopy(), который быстро копирует часть массива в другое место. После копирования освобождаем ненужные ячейки, удаляем их и уменьшаем размер списка соответственно.
Кроме того, при удалении большого количества элементов из середины списка, стоит учитывать, что при каждом удалении элемента происходит сдвиг всех элементов вправо. Это может быть затратным по времени при большом размере списка и большом числе удаляемых элементов, поэтому в таких случаях может быть более эффективно создание нового ArrayList, копирование нужных элементов и замена старого списка на новый.
854. Сколько необходимо дополнительной памяти при вызове ArrayList.add()?
При вызове метода add() у ArrayList может происходить расширение емкости (capacity expansion) внутреннего массива, если текущий размер массива не хватает для добавления нового элемента. В этом случае создается новый массив большего размера и все существующие элементы копируются в него.
Как правило, емкость нового массива увеличивается в 1,5-2 раза от текущей емкости. Таким образом, при каждом расширении емкости ArrayList выделяется дополнительная память на размер текущего массива.
Также ArrayList может занимать некоторое количество дополнительной памяти для своих внутренних нужд. Например, он может хранить размер списка или емкость массива, а также ссылки на объекты-элементы списка.
В целом, количество дополнительной памяти при вызове метода add() зависит от многих факторов, таких как текущий размер списка, текущая емкость массива и объем памяти, требуемой для хранения каждого элемента. Однако, если рассматривать только случай расширения емкости при вызове add(), то количество дополнительной памяти будет примерно равно размеру текущего массива.
855. Сколько выделяется дополнительно памяти при вызове LinkedList.add()?
При вызове метода add() у LinkedList выделяется фиксированное количество дополнительной памяти для создания нового узла, который содержит добавляемый элемент. Размер этого узла по умолчанию составляет 24 байта (8 байтов для ссылки на предыдущий узел, 8 байтов для ссылки на следующий узел и 8 байтов для хранения значения элемента списка).
Кроме того, при каждом вызове метода add() может происходить рост общего объема занимаемой памяти, так как каждый новый узел занимает некоторое количество дополнительной памяти.
Также LinkedList может занимать некоторое количество дополнительной памяти для своих внутренних нужд. Например, он может хранить ссылки на первый и последний узлы списка, а также размер списка.
В целом, количество дополнительной памяти, выделяемой при вызове метода add() у LinkedList, зависит от многих факторов, таких как текущий размер списка, объем памяти, требуемый для хранения каждого элемента и рост общего объема занимаемой памяти. Однако, если рассматривать только случай добавления одного элемента, то количество дополнительной памяти будет примерно равно 24 байтам.
856. Оцените количество памяти на хранение одного примитива типа byte в LinkedList?
Для каждого элемента типа byte в LinkedList будет выделен один узел, который содержит ссылки на предыдущий и следующий узлы, а также само значение byte. Таким образом, затраты памяти для хранения одного значения типа byte в LinkedList зависят от размера объекта узла и используемой виртуальной машиной Java (JVM) архитектуры.
Как правило, размер объекта узла в LinkedList составляет 24 байта на 64-битных JVM и 16 байтов на 32-битных. Это может быть незначительно больше или меньше в зависимости от оптимизаций, производимых конкретной реализацией класса LinkedList и параметров запуска JVM.
Таким образом, приблизительные затраты памяти на хранение одного значения типа byte в LinkedList будут составлять около 24 байт на 64-битных JVM и около 16 байтов на 32-битных. Однако, стоит учитывать, что эти значения могут изменяться в зависимости от конкретной реализации JVM и параметров запуска.
857. Оцените количество памяти на хранение одного примитива типа byte в ArrayList?
Для каждого элемента типа byte в ArrayList будет выделена одна ячейка массива, которая хранит само значение byte. Таким образом, затраты памяти для хранения одного значения типа byte в ArrayList зависят от размера самой ячейки массива и используемой виртуальной машиной Java (JVM) архитектуры.
Размер ячейки массива для примитивного типа byte составляет 1 байт. Однако, следует учитывать, что списки в Java дополнительно занимают некоторый объём памяти на управление списком, такие как: размер списка и емкость массива.
Также следует учитывать, что ArrayList имеет дополнительные сущности, такие как обертки-объекты типа Byte, которые могут быть созданы при необходимости автоупаковки примитивных значений в объекты, например, если используется метод add() с аргументом типа byte.
Таким образом, приблизительные затраты памяти на хранение одного значения типа byte в ArrayList будут составлять около 1 байта на элемент, к которому добавляется чуть больше памяти для управления списком, и ещё дополнительно может заниматься память на обертки-объекты типа Byte при использовании автоупаковки.
858. Для ArrayList или для LinkedList операция добавления элемента в середину (list.add(list.size()/2, newElement)) медленнее?
Для ArrayList операция добавления элемента в середину методом list.add(list.size()/2, newElement) медленнее, чем для LinkedList. Это связано с тем, что при добавлении элемента в середину массива (ArrayList) требуется перемещение всех элементов, расположенных после вставляемого элемента, на одну позицию вправо, чтобы освободить место для нового элемента. При большом размере списка это может привести к значительным затратам по времени.
В то же время, при добавлении элемента в середину списка (LinkedList), требуется лишь создать новый узел и изменить ссылки на предыдущий и следующий узлы для вставляемого узла и его соседних узлов. Эта операция имеет постоянное время O(1). Однако, при обходе списка для доступа к элементам может возникнуть некоторая задержка из-за необходимости проходить по указателям на следующие узлы.
Итак, если требуется частое добавление элементов в середину списка, то LinkedList может быть более подходящим выбором благодаря быстрой операции вставки. Если же список часто используется для доступа к элементам по индексу, например, при использовании списков в качестве стека, то ArrayList может быть более эффективным выбором.
859. В реализации класса ArrayList есть следующие поля: Object[] elementData, int size. Объясните, зачем хранить отдельно size, если всегда можно взять elementData.length?
Хранение отдельного поля size в классе ArrayList имеет несколько причин.
Во-первых, размер массива elementData, хранящего элементы списка, может быть больше, чем количество фактически добавленных элементов. Например, при создании нового экземпляра ArrayList ему может быть выделена начальная емкость в памяти, которая больше, чем 0. В таком случае значение size будет меньше, чем elementData.length.
Во-вторых, операция удаления элементов из ArrayList приводит к тому, что size становится меньше, чем elementData.length. При этом, объем занимаемой памяти остается неизменным, пока емкость массива elementData не будет уменьшена явно (например, с помощью метода trimToSize()).
Еще одной причиной хранения отдельного поля size является то, что при использовании автоупаковки примитивных типов Java в объекты-обертки (например, Integer, Boolean, и т.д.), elementData может содержать некоторое количество null значений, что может привести к различиям между elementData.length и реальным количеством элементов в списке.
Таким образом, хранение отдельного поля size в классе ArrayList позволяет эффективно управлять фактическим количеством элементов в списке и уменьшать объем занимаемой памяти при удалении элементов.
860. Сравните интерфейсы Queue и Deque.
Интерфейсы Queue и Deque являются частями Java Collections Framework и используются для представления коллекций элементов, где каждый элемент добавляется в конец коллекции и удаляется из начала.
Queue (очередь) представляет собой структуру данных, работающую по принципу FIFO (First-In-First-Out), т.е. первый элемент, добавленный в очередь, будет удален первым. Очередь поддерживает операции добавления элемента в конец add() или offer(), удаления элемента из начала remove() или poll(), а также получение, но не удаление, элемента из начала element() или peek().
Deque (двусторонняя очередь) представляет собой двухстороннюю очередь, которая может использоваться как стек или очередь. Другими словами, вы можете добавлять и удалять элементы как с начала, так и с конца очереди. Эта структура данных поддерживает все операции, которые поддерживает Queue, а также операции добавления/удаления элементов в/из начала и конца очереди: addFirst(), addLast(), removeFirst(), removeLast(), getFirst() и getLast().
Таким образом, основным отличием между Queue и Deque является то, что Deque предоставляет более широкий набор операций, позволяющих добавлять и удалять элементы как в начале, так и в конце очереди. В то же время, Queue ориентирована на работу только со структурой данных, работающей по принципу FIFO, тогда как Deque может использоваться для реализации как стека, так и очереди.
861. Кто кого расширяет: Queue расширяет Deque, или Deque расширяет Queue?
В Java интерфейс Deque расширяет интерфейс Queue, а не наоборот. Таким образом, все методы, определенные в интерфейсе Queue, также доступны и в Deque.
Это связано с тем, что Deque является более широкой структурой данных, которая может использоваться как стек или очередь, в то время как Queue ориентирована только на работу со структурой данных, работающей по принципу FIFO (First-In-First-Out).
Интерфейс Queue содержит базовый функционал для работы с очередью: добавление элемента, удаление элемента, получение, но не удаление, элемента из начала очереди. Интерфейс Deque содержит этот же базовый функционал, а также дополнительные методы для работы с двусторонней очередью: добавление в начало и конец списка, удаление из начала и конца списка, а также получение, но не удаление, элемента из начала и конца списка.
Таким образом, если вы хотите использовать какую-то специфическую функциональность, доступную только в Deque, то можно использовать этот интерфейс. Если же вам нужно только базовое управление очередью, то можно использовать интерфейс Queue.
862. Почему LinkedList реализует и List, и Deque?
Класс LinkedList в Java Collections Framework (JCF) реализует два интерфейса: List и Deque.
Реализация интерфейса List означает, что LinkedList является списком, то есть упорядоченной коллекцией элементов с возможностью дублирования. Элементы списка могут быть доступны по индексу.
Реализация интерфейса Deque означает, что LinkedList также представляет собой двустороннюю очередь, то есть упорядоченную коллекцию элементов, которая позволяет добавлять и удалять элементы как в начале, так и в конце очереди.
Таким образом, причина того, что LinkedList реализует оба интерфейса, заключается в том, что он подходит как для использования в качестве списка, так и для использования в качестве двусторонней очереди. Благодаря этому, LinkedList может быть использован в широком диапазоне приложений, где требуется работа со списками или очередями.
Кроме того, LinkedList имеет ряд других преимуществ, таких как быстрая вставка и удаление элементов в начале или конце списка (количество операций O(1)), а также возможность хранить null элементы. Однако, следует учитывать, что доступ к произвольному элементу в списке может быть медленным (количество операций O(n) в худшем случае).
863. LinkedList — это односвязный, двусвязный или четырехсвязный список?
LinkedList в Java представляет собой двусвязный список (doubly linked list). Это означает, что каждый элемент списка содержит ссылки на следующий и предыдущий элементы.
Каждый узел LinkedList содержит три поля:
item - это значение, хранящееся в текущем узле;
next - это ссылка на следующий узел списка;
prev - это ссылка на предыдущий узел списка.
Благодаря двусвязной структуре данных, LinkedList позволяет быстро добавлять или удалять элементы как в начале, так и в конце списка, а также произвольные операции вставки и удаления элементов. Однако, для доступа к элементам по индексу требуется пройти по всему списку до нужного элемента, что может быть более медленным, чем в массивах или ArrayList.
864. Как перебрать элементы LinkedList в обратном порядке, не используя медленный get(index)?
LinkedList предоставляет возможность перебирать элементы в обратном порядке, используя метод descendingIterator(), который возвращает итератор для обхода списка в обратном порядке.
Пример использования:
LinkedList<String> list = new LinkedList<>();
// добавляем элементы в список
list.add("один");
list.add("два");
list.add("три");
// создаем итератор для обхода списка в обратном порядке
ListIterator<String> iterator = list.descendingIterator();
// перебираем элементы списка в обратном порядке
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
Результат выполнения данного кода будет:
три
два
один
Обратите внимание, что при использовании метода descendingIterator() элементы списка перебираются в обратном порядке без необходимости прохода по всем элементам с помощью медленного get(index).
865. Что позволяет сделать PriorityQueue?
PriorityQueue в Java представляет собой очередь с приоритетами, которая используется для хранения элементов в порядке убывания или возрастания приоритета.
Очередь с приоритетами позволяет добавлять и удалять элементы, при этом каждый элемент имеет свой приоритет (заданный в виде числа или объекта Comparable) и элементы извлекаются из очереди в порядке увеличения или уменьшения приоритета. Таким образом, на вершине очереди всегда будет элемент с максимальным или минимальным приоритетом.
Пример использования:
PriorityQueue<Integer> queue = new PriorityQueue<>();
// добавляем элементы в очередь
queue.add(5);
queue.add(1);
queue.add(3);
queue.add(2);
queue.add(4);
// извлекаем элементы из очереди
while (!queue.isEmpty()) {
System.out.println(queue.poll());
}
Результат выполнения данного кода будет:
1
2
3
4
5
PriorityQueue может быть использована в различных задачах, например, для решения задач в области расписания, оптимизации, а также для реализации алгоритмов поиска кратчайшего пути или минимального остовного дерева в графах.
866. Stack считается «устаревшим». Чем его рекомендуют заменять? Почему?
Stack в Java действительно считается устаревшим классом, поскольку он наследуется от класса Vector, который также считается устаревшим. Вместо использования Stack рекомендуется использовать класс Deque, который реализует интерфейсы Queue, Deque, а также Stack.
Класс Deque является двусторонней очередью и позволяет добавлять и удалять элементы как в начале, так и в конце очереди. Благодаря этому, Deque может быть использован как для работы со структурой данных, работающей по принципу FIFO (First-In-First-Out), так и для реализации стека.
Пример использования Deque в качестве стека:
Deque<String> stack = new ArrayDeque<>();
// добавляем элементы в стек
stack.push("один");
stack.push("два");
stack.push("три");
// извлекаем элементы из стека
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
Результат выполнения данного кода будет:
три
два
один
Использование Deque в качестве стека имеет ряд преимуществ по сравнению с классом Stack. В частности, метод Deque.push() добавляет элемент в начало списка, что делает его быстрее, чем метод Stack.push(), который добавляет элемент в конец списка. Кроме того, Deque является более гибкой структурой данных и может использоваться для решения различных задач, включая реализацию очередей и двусторонних списков.
867. Зачем нужен HashMap, если есть Hashtable?
HashMap и Hashtable являются реализациями интерфейса Map в Java и предназначены для хранения пар ключ-значение. Оба класса имеют схожий функционал, но есть несколько отличий.
Главное отличие между HashMap и Hashtable заключается в том, что HashMap не синхронизирован, а Hashtable синхронизирован. Синхронизация означает, что все методы Hashtable защищены от одновременного доступа нескольких потоков и гарантируется безопасность при работе нескольких потоков с одним экземпляром класса. Однако, это может приводить к уменьшению производительности при работе с одним потоком, так как каждый метод будет синхронизирован.
С другой стороны, HashMap не синхронизирован, что позволяет ему обеспечивать более высокую скорость работы в однопоточных приложениях. Кроме того, HashMap допускает использование null в качестве ключа и значения, тогда как Hashtable этого не позволяет.
Таким образом, если не требуется безопасность при работе нескольких потоков с одним экземпляром класса, то рекомендуется использовать HashMap, поскольку он обеспечивает более высокую производительность в однопоточных приложениях. Если же требуется безопасность при работе нескольких потоков с одним экземпляром класса, то можно использовать Hashtable или ConcurrentHashMap.
868. В чем разница между HashMap и IdentityHashMap? Для чего нужна IdentityHashMap?
HashMap и IdentityHashMap в Java представляют собой реализации интерфейса Map, но имеют различное поведение при определении эквивалентности ключей.
В HashMap эквивалентность ключей определяется методами equals() и hashCode(). Два объекта, которые равны по методу equals(), будут считаться одинаковыми ключами.
В IdentityHashMap эквивалентность ключей определяется с помощью оператора ==. Два объекта будут считаться одинаковыми ключами только в том случае, если они ссылаются на один и тот же объект.
Таким образом, в IdentityHashMap два ключа могут быть равными по значению, но не равными по ссылке, тогда как в HashMap два ключа могут быть равными по ссылке, но не равными по значению.
IdentityHashMap может быть полезен в тех случаях, когда нужно хранить объекты, которые могут быть равны друг другу по значению, но имеют разные ссылки на память (например, объекты-экземпляры класса String). В таких случаях использование HashMap может привести к созданию лишних объектов в памяти, в то время как IdentityHashMap позволяет избежать этого.
Однако, следует учитывать, что IdentityHashMap работает медленнее, чем HashMap, из-за особенностей определения эквивалентности ключей. Также, IdentityHashMap не подходит для использования в случаях, когда требуется использование метода equals() и hashCode(), например, для использования объектов с произвольными ключами или для реализации хеш-таблицы.
869. В чем разница между HashMap и WeakHashMap? Для чего используется WeakHashMap?
HashMap и WeakHashMap являются реализациями интерфейса Map, но имеют различное поведение при работе с объектами, которые не используются.
В HashMap каждый ключ и значение хранятся в обычных ссылках. Это означает, что если объект-ключ или объект-значение находится в HashMap и не используется, то он продолжит занимать память до тех пор, пока не будет удален из HashMap.
В WeakHashMap все ключи хранятся в слабых (weak) ссылках. Это означает, что если объект-ключ не используется в других частях программы и находится только в WeakHashMap, то он может быть удален сборщиком мусора.
Таким образом, WeakHashMap может использоваться для управления памятью и предотвращения утечек памяти. Например, если объект-ключ больше не используется в программе, то он будет автоматически удален из WeakHashMap сборщиком мусора, освободив память.
Однако, следует учитывать, что использование WeakHashMap может привести к потере данных, если объект-ключ был удален из WeakHashMap сборщиком мусора, а значение, связанное с этим ключом, еще используется в программе. Поэтому WeakHashMap следует использовать только в тех случаях, когда это не приведет к потере данных.
В целом, WeakHashMap может быть полезен в ряде задач, например, при кэшировании данных, когда ключи удаляются из кэша автоматически, если они не используются в других частях программы.
870. В WeakHashMap используются WeakReferences. А почему бы не создать SoftHashMap на SoftReferences?
SoftHashMap на SoftReferences может быть использовано для решения тех же задач, что и WeakHashMap, но с более мягкой стратегией удаления элементов из кэша.
Основное отличие между SoftReference и WeakReference заключается в том, что SoftReference имеет более мягкую стратегию удаления объектов, чем WeakReference. То есть, если объект-ключ хранится только в SoftHashMap, то он может быть удален сборщиком мусора только в случае, если не хватает памяти, в то время как объект-ключ, хранимый только в WeakHashMap, может быть удален при первом проходе сборщика мусора.
Таким образом, использование SoftHashMap может быть полезным в тех случаях, когда требуется сохранить объекты в памяти настолько, насколько это возможно, но объекты должны быть удалены, если места в памяти не хватает. В этом случае SoftHashMap позволяет уменьшить количество операций сборки мусора в программе и предотвратить утечки памяти.
Однако, следует учитывать, что использование SoftHashMap также может привести к потере данных, если объект-ключ был удален из SoftHashMap сборщиком мусора, а значение, связанное с этим ключом, еще используется в программе. Поэтому SoftHashMap следует использовать только в тех случаях, когда это не приведет к потере данных, и учитывать особенности работы SoftReference в своей программе.
871. В WeakHashMap используются WeakReferences. А почему бы не создать PhantomHashMap на PhantomReferences?
В Java PhantomReference используется в основном для отслеживания того, когда объект был удален сборщиком мусора. В отличие от WeakReference и SoftReference, PhantomReference не позволяет получить ссылку на объект, поэтому он не может использоваться напрямую для реализации Map.
Таким образом, создание PhantomHashMap на PhantomReference не является возможным. Однако, можно использовать PhantomReference в сочетании с другими классами, например, ReferenceQueue, HashMap и Thread, для решения некоторых задач.
Например, можно использовать PhantomReference и ReferenceQueue для отслеживания удаления объектов из HashMap. Для этого можно создать объекты-ключи в HashMap и связать каждый ключ с PhantomReference и ReferenceQueue. Когда объект-ключ будет удален из HashMap сборщиком мусора, его PhantomReference будет помещен в ReferenceQueue. Затем можно использовать отдельный поток для периодической проверки наличия элементов в ReferenceQueue и удаления соответствующих записей из HashMap.
Однако, следует учитывать, что такой подход требует дополнительных затрат времени и ресурсов, поскольку нужно создавать дополнительные объекты для каждого элемента в HashMap. Кроме того, это может быть сложно для реализации и не всегда эффективно с точки зрения производительности. Поэтому перед использованием такого подхода следует тщательно оценить его преимущества и недостатки в контексте конкретной задачи.
872. LinkedHashMap - что в нем от LinkedList, а что от HashMap?
LinkedHashMap в Java объединяет функционал HashMap и LinkedList. Как и HashMap, LinkedHashMap использует хеш-таблицу для хранения пар ключ-значение, но дополнительно сохраняет порядок добавления элементов с помощью двунаправленного списка. Таким образом, каждый элемент в LinkedHashMap содержит ссылки на предыдущий и следующий элементы в списке, что позволяет эффективно поддерживать порядок элементов.
Кроме того, в LinkedHashMap есть два режима доступа к элементам: первый - доступ в порядке добавления элементов (порядок доступа), и второй - доступ в порядке доступности элементов (порядок доступности). При использовании режима порядка доступа, элементы будут возвращаться в порядке, в котором они были добавлены в LinkedHashMap. При использовании режима порядка доступности элементы будут возвращаться в порядке их использования, где последний доступный элемент будет располагаться в конце списка.
Таким образом, LinkedHashMap сочетает в себе быстрое время доступа к элементам с использованием хеш-таблицы и возможность поддерживать порядок элементов, что может быть полезным для некоторых задач, например, при работе с кэшами или логами.
Однако, следует учитывать, что использование LinkedHashMap может привести к дополнительным затратам памяти, поскольку каждый элемент содержит ссылки на предыдущий и следующий элементы в списке. Кроме того, при работе с большими объемами данных могут возникнуть проблемы со скоростью доступа к элементам из-за необходимости перестраивать хеш-таблицу при изменении ее размера.
873. В чем проявляется «сортированность» SortedMap, кроме того, что toString() выводит все элементы по порядку?
SortedMap в Java представляет собой отсортированную по ключам Map. Ключи элементов хранятся в упорядоченном виде, что обеспечивает эффективный доступ к элементам по ключу и поддержку операций, связанных со сравнением ключей, например, поиск элементов в промежутке между двумя ключами.
Кроме того, SortedMap предоставляет ряд методов для работы с отсортированным порядком элементов. Например, методы firstKey(), lastKey(), headMap(), tailMap() и subMap() позволяют получить подмножества элементов, начиная от первого или последнего элемента, либо в заданном диапазоне ключей.
SortedMap также определяет порядок итерации элементов через методы entrySet(), keySet() и values(). Элементы перебираются в порядке возрастания ключей, что гарантирует, что элементы будут возвращаться в том же порядке, в котором они были добавлены.
Таким образом, SortedMap предоставляет не только возможность получения элементов в отсортированном порядке, но и более эффективный доступ к элементам по ключу и набор полезных методов для работы с отсортированным порядком элементов.
874. Как устроен HashMap?
HashMap - это реализация интерфейса Map в Java, которая использует хеш-таблицу для хранения пар ключ-значение. Каждый элемент хранится в ячейке массива, индекс которой вычисляется как хеш-код ключа.
При добавлении элемента в HashMap сначала вычисляется хеш-код ключа с помощью метода hashCode(). Затем этот хеш-код преобразуется так, чтобы он был в пределах размера массива, который задан при создании HashMap. Обычно это делается путем применения операции побитового "и" (&) к хеш-коду и маске, размер которой равен степени двойки и на единицу меньше, чем размер массива. Затем элемент добавляется в ячейку массива по соответствующему индексу.
Если несколько элементов имеют одинаковые хеш-коды, то они будут храниться в одной ячейке массива в виде связного списка или дерева в зависимости от количества элементов в ячейке и определенных пороговых значений (например, если количество элементов в ячейке превышает определенное значение, то связный список будет преобразован в дерево).
При поиске элемента в HashMap сначала вычисляется его хеш-код и определяется ячейка массива, в которой он должен быть сохранен. Затем производится поиск элемента в связном списке или дереве в соответствующей ячейке.
Для обеспечения эффективного использования памяти и времени доступа к элементам, размер массива HashMap увеличивается автоматически при достижении определенного порога заполнения. При этом все элементы перехешируются и будут размещены в новых ячейках массива. Этот процесс называется "рехешированием".
Также HashMap поддерживает null-ключ и null-значение, что может быть полезным в некоторых случаях.
Однако, следует учитывать, что хеш-коды могут конфликтовать, что может привести к неэффективной работе HashMap. Для минимизации количества конфликтов и оптимизации производительности HashMap следует тщательно выбирать хеш-функцию, особенно для пользовательских типов данных.
875. Согласно Кнуту и Кормену существует две основных реализации хэш-таблицы: на основе открытой адресации и на основе метода цепочек. Как реализована HashMap? Почему, по вашему мнению, была выбрана именно эта реализация? В чем плюсы и минусы каждого подхода?
HashMap в Java реализована на основе метода цепочек. При этом коллизии, то есть ситуации, когда два разных ключа имеют одинаковый хеш-код и должны быть сохранены в одной ячейке массива, решаются путем добавления элементов в связный список в соответствующей ячейке.
Выбор данной реализации обусловлен тем, что метод цепочек имеет несколько преимуществ перед открытой адресацией. Во-первых, он более устойчив к коллизиям, поскольку количество элементов в ячейке может быть произвольным. Во-вторых, метод цепочек позволяет хранить элементы в порядке их добавления, что может быть полезным для некоторых задач.
Однако, метод цепочек также имеет свои недостатки. В частности, при большом количестве коллизий связные списки в ячейках могут стать очень длинными, что приведет к ухудшению производительности HashMap. Кроме того, каждый элемент в связном списке требует дополнительной памяти для хранения ссылок на следующий элемент.
В отличие от метода цепочек, при использовании открытой адресации, все элементы хранятся непосредственно в ячейках массива. Если ячейка уже занята другим элементом, то производится поиск следующей свободной ячейки и туда записывается элемент. Этот процесс повторяется до тех пор, пока не будет найдена свободная ячейка.
Преимуществом открытой адресации является отсутствие выделения дополнительной памяти для хранения ссылок на связные списки. Однако, этот подход более чувствителен к коллизиям, поскольку если много ключей имеют одинаковый хеш-код, то может быть очень сложно найти свободную ячейку.
Таким образом, каждый подход имеет свои преимущества и недостатки, и выбор конкретной реализации должен зависеть от конкретной задачи и ее требований к производительности и использованию памяти.
876. Как работает HashMap при попытке сохранить в него два элемента по ключам с одинаковым hashCode(), но для которых equals() == false?
Если в HashMap попытаться сохранить два элемента с одинаковым хеш-кодом, но для которых метод equals() вернет false, то оба элемента будут сохранены в разных ячейках массива.
При добавлении элемента в HashMap он помещается в ячейку массива по соответствующему индексу, который вычисляется на основе хеш-кода ключа. Если ячейка уже занята другим элементом, то новый элемент будет добавлен в конец связного списка в этой ячейке.
При поиске элемента по ключу происходит следующее: сначала определяется ячейка массива, в которой может быть сохранен элемент с заданным ключом. Затем производится поиск элемента в связном списке этой ячейки. При этом для каждого элемента в списке вызывается метод equals(), чтобы проверить, соответствует ли он заданному ключу.
Таким образом, если два элемента имеют одинаковый хеш-код, но метод equals() для них возвращает false, то они будут сохранены в разных ячейках массива и не будут взаимозаменяемы при поиске по ключу. Каждый элемент будет находиться в своей ячейке и будет доступен только при использовании соответствующего ключа при поиске.
877. Какое начальное количество корзин в HashMap?
При создании объекта HashMap в Java не задается начальное количество корзин (buckets) - размер хеш-таблицы. Вместо этого, по умолчанию используется значение 16.
Однако, при создании HashMap можно указать желаемую начальную емкость с помощью конструктора, который принимает число - начальный размер хеш-таблицы. Например:
HashMap<String, Integer> map = new HashMap<>(32);
Если в HashMap будут сохранены большое количество элементов, то могут возникнуть проблемы с производительностью из-за частых рехеширований и коллизий. В таких случаях рекомендуется задавать начальную емкость достаточно большой, например, в два раза больше ожидаемого количества элементов.
Также следует учитывать, что размер HashMap автоматически увеличивается, когда заполнение достигает определенного порога, что может привести к временным затратам на перехеширование и увеличению использования памяти.
878. Какова оценка временной сложности операций над элементами из HashMap? Гарантирует ли HashMap указанную сложность выборки элемента?
Оценка временной сложности операций в HashMap зависит от реализации, размера таблицы и количества элементов.
В среднем, операция добавления, удаления и поиска элемента в HashMap имеют временную сложность O(1). Однако, в худшем случае, когда все элементы попадают в одну корзину, они будут связаны в связный список или дерево, и операция может занимать время O(n), где n - количество элементов в корзине. Таким образом, сложность операций в HashMap зависит от количества коллизий и хеш-функции.
Гарантируется ли HashMap указанную сложность выборки элемента? Нет, HashMap не гарантирует указанную сложность выборки элемента, поскольку это зависит от конкретной реализации и данных. В среднем, сложность выборки элемента также составляет O(1), но в худшем случае может достигать O(n).
Таким образом, при работе с HashMap следует учитывать возможные коллизии и выбирать хеш-функцию с учетом конкретных требований задачи. Также стоит помнить, что реальная производительность HashMap может зависеть от конкретной реализации и размера таблицы.
879. Возможна ли ситуация, когда HashMap выродится в список даже с ключами имеющими разные hashCode()?
Да, возможна ситуация, когда HashMap выродится в связный список (linked list) даже если ключи имеют разные хеш-коды. Это происходит, когда большое количество ключей попадает в одну и ту же корзину (bucket) - то есть ячейку массива, где указывается первый элемент списка.
В этой ситуации сложность всех операций на элементах такой "вырожденной" HashMap становится линейной O(n), где n - количество элементов в списке.
Такое поведение может возникать, когда хеш-функция не распределяет ключи равномерно по корзинам. Например, если все ключи имеют одинаковый хеш-код, то они будут сохранены в одной корзине и HashMap выродится в связный список.
Чтобы избежать таких ситуаций, следует выбирать хеш-функцию, которая распределяет элементы равномерно по корзинам. Также можно увеличить размер таблицы (HashMap автоматически увеличивает размер, когда заполнение достигает определенного порога), чтобы уменьшить количество коллизий и вероятность образования связных списков в корзинах.
880. В каком случае может быть потерян элемент в HashMap?
Потеря элемента в HashMap может произойти, если два разных ключа имеют одинаковый хеш-код и попадают в одну корзину (bucket), где элементы сохраняются в связный список или дерево. В этом случае при выборке элемента по ключу возможна ситуация, когда будет найден не тот элемент, который был добавлен ранее.
Это называется коллизией, и HashMap использует метод цепочек (chaining) для разрешения коллизий - то есть все элементы с одинаковым хеш-кодом сохраняются в одной корзине в виде связного списка или дерева. Однако, если хеш-функция плохо распределяет ключи, то может произойти ситуация, когда все элементы попадут в одну корзину и HashMap выродится в список (linked list).
Если размер связного списка или дерева становится очень большим, то выборка элемента по ключу может занимать много времени. Кроме того, при переполнении списка или дерева может произойти его усечение, в результате чего некоторые элементы будут потеряны.
Чтобы избежать потери элементов, следует выбирать хорошую хеш-функцию, которая равномерно распределяет элементы по корзинам, и увеличивать размер таблицы в HashMap при необходимости. Также можно использовать альтернативные реализации HashMap, которые используют другие способы разрешения коллизий, например, открытую адресацию (open addressing).
881. Почему нельзя использовать byte[] в качестве ключа в HashMap?
Byte-массивы (byte[]) могут использоваться в качестве ключей в HashMap, но при этом необходимо учитывать особенности работы с данными массивами.
В Java, для сравнения объектов используется метод equals(), который по умолчанию сравнивает ссылки на объекты. Если два byte-массива созданы отдельно друг от друга, то ссылки на них будут различными, даже если содержимое массивов одинаковое.
Поэтому, если использовать byte-массивы в качестве ключей в HashMap, то для корректной работы необходимо переопределить методы equals() и hashCode(), чтобы они сравнивали содержимое массивов, а не ссылки на них.
Еще одна проблема использования byte-массивов в качестве ключей заключается в том, что хеш-коды для массивов вычисляются на основе ссылок, а не содержимого. Поэтому, если использовать не переопределенный метод hashCode() для byte-массивов в HashMap, то возможна ситуация, когда разные массивы с одинаковым содержимым будут иметь разные хеш-коды, что приведет к ошибочной работе хеш-таблицы.
Таким образом, использование byte-массивов в качестве ключей в HashMap возможно, но требует дополнительной работы по переопределению методов equals() и hashCode(), чтобы корректно сравнивать содержимое массивов. Если это невозможно или нецелесообразно, то следует использовать другие типы данных в качестве ключей.
882. Какова роль equals() и hashCode() в HashMap?
Методы equals() и hashCode() играют важную роль в работе HashMap в Java. Они используются для сравнения ключей и определения индекса ячейки массива, где должен быть сохранен элемент.
Метод hashCode() возвращает хеш-код объекта, который используется в качестве индекса в массиве HashMap. Ключи с одинаковым хеш-кодом попадают в одну ячейку массива, где они могут быть сохранены в связный список (linked list) или дерево (tree), если количество элементов в ячейке превышает пороговое значение.
Метод equals() используется для сравнения ключей внутри ячейки. Если два ключа не равны друг другу (с точки зрения метода equals()), то они могут быть сохранены в одной ячейке массива в виде списка или дерева.
При поиске элемента по ключу в HashMap, происходит следующее:
- Вычисляется хеш-код ключа.
- На основе хеш-кода выбирается соответствующая ячейка массива.
- Если в ячейке найден только один элемент, то он сравнивается с заданным ключом с помощью метода equals().
- Если в ячейке находится больше одного элемента, то они сравниваются с заданным ключом с помощью метода equals().
Если хеш-код не переопределен в классе ключа, то по умолчанию используется хеш-код объекта, который вычисляется на основе его адреса в памяти. Поэтому для корректной работы HashMap необходимо как правильно реализовать методы hashCode() и equals() в классе ключа, чтобы они соответствовали требованиям хеш-таблицы.
883. Каково максимальное число значений hashCode()?
Максимальное число значений hashCode() в Java ограничено размером типа данных int, который составляет 32 бита. Поэтому количество возможных значений хеш-кода равно 2^32, то есть около 4,3 миллиарда.
При вычислении хеш-кода объекта, значение типа int получается с помощью алгоритма, который преобразует произвольный набор байтов в число типа int. В результате этого преобразования может получиться любое число от 0 до 2^32 - 1.
Использование большего количества битов для хеш-кода может увеличить количество возможных значений и уменьшить вероятность коллизий. Однако, использование более длинных хеш-кодов также увеличивает занимаемую память и время вычисления хеш-кода.
В любом случае, при выборе хеш-функции следует учитывать требования к производительности и качеству распределения элементов по корзинам. Хорошая хеш-функция должна равномерно распределять элементы по корзинам, чтобы минимизировать количество коллизий и обеспечить быстрый доступ к элементам.
884. Какое худшее время работы метода get(key) для ключа, которого нет в HashMap?
В случае, если ключа нет в HashMap, метод get(key) должен пройти по всем ячейкам массива и спискам или деревьям, которые хранятся в каждой ячейке, чтобы понять, что элемент не найден.
Таким образом, в худшем случае время работы метода get(key) для ключа, которого нет в HashMap, будет O(n), где n - количество элементов в хеш-таблице. Это происходит, когда все ключи имеют одинаковый хеш-код и хранятся в одной корзине, образуя связный список или дерево. В этом случае при поиске ключа, которого нет в таблице, потребуется пройти по всем элементам в связном списке или дереве, что приведет к времени работы O(n).
Однако, в реальной жизни такая ситуация маловероятна, так как использование хороших хеш-функций и увеличение размера таблицы (HashMap автоматически увеличивает размер, когда заполнение достигает определенного порога) помогают минимизировать количество коллизий. В большинстве случаев метод get(key) работает за время O(1).
885. Какое худшее время работы метода get(key) для ключа, который есть в HashMap?
В худшем случае, время работы метода get(key) для ключа, который есть в HashMap, также может быть O(n), где n - количество элементов в связном списке или дереве, которое сохраняется в ячейке массива.
Это происходит, когда все ключи имеют одинаковый хеш-код и хранятся в одной корзине в виде связного списка или дерева. В этом случае, при поиске ключа, которого нет в таблице, потребуется пройти по всем элементам в связном списке или дереве, что приведет к времени работы O(n).
Однако, если хеш-функция правильно распределяет элементы по корзинам, то вероятность того, что несколько элементов будут сохранены в одной корзине, минимальна. При использовании хороших хеш-функций и увеличении размера таблицы (HashMap автоматически увеличивает размер, когда заполнение достигает определенного порога) можно минимизировать количество коллизий и обеспечить временную сложность метода get(key) за O(1), то есть постоянное время, независимо от количества элементов в таблице.
В целом, для большинства случаев можно считать, что время работы метода get(key) в HashMap в худшем случае равно O(n), где n - количество элементов в связном списке или дереве. Однако, при использовании хороших хеш-функций и достаточно большого размера таблицы (или наличия механизма автоматического изменения размера), вероятность худшего случая снижается до минимума, а время работы метода get(key) становится постоянным O(1).
886. Сколько переходов происходит в момент вызова HashMap.get(key) по ключу, который есть в таблице?
В общем случае, при вызове метода HashMap.get(key) по ключу, который есть в таблице, происходят два перехода:
- Вычисляется хеш-код ключа с помощью метода hashCode().
- Сравнивается ключ со всеми ключами, которые сохранены в корзине, соответствующей вычисленному хеш-коду.
Если ключ не является первым элементом в списке или дереве, то будет произведен еще один переход для перехода от одного элемента к другому в списке или дереве до тех пор, пока не найдется нужный ключ.
В идеальном случае, когда все ключи имеют разные хеш-коды, каждый элемент будет находиться в своей корзине, и поиск ключа займет только два перехода. Однако, если несколько ключей имеют одинаковый хеш-код, они будут храниться в одной корзине в виде списка или дерева, что приведет к увеличению количества переходов.
Таким образом, количество переходов в методе HashMap.get(key) по ключу, который есть в таблице, зависит от того, насколько хорошо распределены ключи по корзинам. В целом, если использовать хорошие хеш-функции и достаточно большой размер таблицы, то количество переходов будет минимальным и метод HashMap.get(key) будет работать с постоянной временной сложностью O(1).
887. Сколько создается новых объектов, когда вы добавляете новый элемент в HashMap?
При добавлении нового элемента в HashMap создается несколько объектов.
- Создается объект Entry (или TreeNode, если используется дерево), который содержит ключ, значение и ссылку на следующий элемент в списке или родительский элемент в дереве.
- Вычисляется хеш-код ключа с помощью метода hashCode().
- Вычисляется индекс ячейки массива, где должен быть сохранен элемент, посредством выполнения операции побитового И над хеш-кодом элемента и маской, получаемой из длины массива - 1.
- Если в выбранной ячейке массива уже есть элементы, то создается новый объект Entry (или TreeNode), который будет ссылаться на предыдущие элементы.
Таким образом, при добавлении нового элемента в HashMap может быть создано несколько объектов класса Entry или TreeNode, в зависимости от того, какая структура данных используется для хранения элементов в корзине. Если в корзине уже есть элементы, то количество созданных объектов может увеличиться.
В целом, количество создаваемых объектов при добавлении нового элемента в HashMap зависит от того, сколько элементов уже хранится в таблице и распределены ли они равномерно по корзинам. Если таблица достаточно большая и хорошо заполнена, то количество создаваемых объектов будет минимальным.
888. Как и когда происходит увеличение количества корзин в HashMap?
HashMap автоматически увеличивает количество корзин (buckets), когда количество элементов достигает определенного порога. Порог определяется коэффициентом загрузки (load factor), который по умолчанию равен 0.75.
Коэффициент загрузки означает, какой процент заполнения таблицы является максимальным допустимым значением. Когда количество элементов в таблице достигает этого значения, HashMap создает новую таблицу с большим количеством корзин и перехеширует все элементы из старой таблицы в новую.
Процесс перехеширования может занять некоторое время, поэтому это делается только тогда, когда это необходимо для поддержания хорошей производительности. Увеличение числа корзин позволяет распределить больше элементов по таблице, что снижает вероятность возникновения коллизий и ускоряет работу методов.
Увеличение количества корзин в HashMap также увеличивает занимаемую память, поэтому следует выбирать размер таблицы в зависимости от количества элементов, которые должны быть сохранены в ней. Если таблица слишком большая, она будет занимать слишком много памяти, а если слишком маленькая, это может привести к частым коллизиям и ухудшению производительности.
В целом, HashMap автоматически увеличивает количество корзин, когда это необходимо для поддержания хорошей производительности, и следует учитывать размер таблицы при выборе этой структуры данных.
889. Объясните смысл параметров в конструкторе HashMap(int initialCapacity, float loadFactor).
Конструктор HashMap(int initialCapacity, float loadFactor) позволяет создать объект HashMap с начальной емкостью (initial capacity) и коэффициентом загрузки (load factor), которые определяют размер таблицы и когда будет происходить увеличение количества корзин.
Параметр initialCapacity задает начальный размер таблицы - количество корзин, которое будет выделено при создании объекта. Это может быть полезно, если заранее известно, сколько элементов планируется хранить в таблице, и можно выбрать такой размер, чтобы минимизировать количество коллизий. Если параметр не указан, то размер таблицы будет выбран по умолчанию (обычно 16).
Параметр loadFactor задает максимальный процент заполнения таблицы, при достижении которого происходит увеличение количества корзин. Данный параметр должен быть числом от 0 до 1. Если параметр установлен на 0.75, значит таблица будет увеличена, когда в ней будет сохранено 75% от максимального количества элементов. Чем меньше значение параметра loadFactor, тем больше памяти будет использоваться, но меньше вероятность возникновения коллизий и уменьшение времени работы методов. Важно помнить, что изменение параметра loadFactor влияет на производительность и память, поэтому его следует выбирать с учетом конкретных требований приложения.
Таким образом, параметры initialCapacity и loadFactor используются для контроля размера таблицы и ее эффективного использования. Наличие возможности задать начальный размер и коэффициент загрузки HashMap позволяет приспособить эту структуру данных к конкретным условиям работы программы и повысить ее производительность.
890. Будет ли работать HashMap, если все добавляемые ключи будут иметь одинаковый hashCode()?
HashMap будет работать, если все добавляемые ключи имеют один и тот же hashCode(), но это может привести к ухудшению производительности и появлению большого количества коллизий.
Когда несколько ключей имеют одинаковый hashCode(), они будут сохраняться в одной корзине в виде связного списка или дерева, что приводит к усложнению логики поиска элементов и ухудшению производительности методов.
При использовании HashMap рекомендуется использовать хорошие хеш-функции, которые распределяют ключи равномерно по таблице, чтобы минимизировать количество коллизий и обеспечить максимальную производительность.
Если заранее известно, что все ключи будут иметь одинаковый hashCode(), то можно использовать другие структуры данных, которые не зависят от хеш-кодов, например, связный список или массив. Однако, если возможна смена хеш-функции или добавления новых ключей, то следует использовать специальные хеш-таблицы или хеш-функции, которые позволяют работать с ключами, имеющими одинаковый hashCode().
891. Как перебрать все ключи Map?
Для перебора всех ключей в Map можно использовать метод keySet(), который возвращает множество ключей, сохраненных в Map. Затем можно использовать цикл for-each для перебора всех ключей:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
for (Integer key : map.keySet()) {
// обработка каждого ключа
System.out.println(key);
}
В этом примере map.keySet() возвращает множество ключей типа Integer, которые сохранены в map. Далее цикл for-each перебирает все ключи и выполняет обработку каждого ключа.
Также можно использовать метод forEach(), который позволяет выполнить действие для каждой записи в Map:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
map.forEach((key, value) -> {
// обработка каждого ключа и значения
System.out.println(key + ": " + value);
});
В этом примере map.forEach() выполняет переданное лямбда-выражение для каждой записи в Map, где первый параметр - это ключ, а второй - значение.
Обратите внимание, что при переборе ключей с помощью метода keySet() порядок обхода ключей не гарантируется. Если нужно гарантировать определенный порядок обхода ключей, например, в порядке добавления элементов, можно использовать другие структуры данных, такие как LinkedHashMap.
892. Как перебрать все значения Map?
Для перебора всех значений в Map можно использовать метод values(), который возвращает коллекцию значений, сохраненных в Map. Затем можно использовать цикл for-each для перебора всех значений:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
for (String value : map.values()) {
// обработка каждого значения
System.out.println(value);
}
В этом примере map.values() возвращает коллекцию значений типа String, которые сохранены в map. Далее цикл for-each перебирает все значения и выполняет обработку каждого значения.
Также можно использовать метод forEach(), который позволяет выполнить действие для каждой записи в Map:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
map.forEach((key, value) -> {
// обработка каждого ключа и значения
System.out.println(key + ": " + value);
});
В этом примере map.forEach() выполняет переданное лямбда-выражение для каждой записи в Map, где первый параметр - это ключ, а второй - значение.
Обратите внимание, что при переборе значений с помощью метода values() порядок обхода значений не гарантируется. Если нужно гарантировать определенный порядок обхода значений, например, в порядке добавления элементов, можно использовать другие структуры данных, такие как LinkedHashMap.
893. Как перебрать все пары «ключ-значение» в Map?
Для перебора всех пар «ключ-значение» в Map можно использовать метод entrySet(), который возвращает множество записей, каждая из которых представляет собой пару "ключ-значение". Затем можно использовать цикл for-each для перебора всех записей:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
for (Map.Entry<Integer, String> entry : map.entrySet()) {
// обработка каждой записи (ключ + значение)
System.out.println(entry.getKey() + ": " + entry.getValue());
}
В этом примере map.entrySet() возвращает множество записей типа Map.Entry<Integer, String>, каждая из которых представляет собой пару "ключ-значение", сохраненную в map. Далее цикл for-each перебирает все записи и выполняет обработку каждой записи.
Также можно использовать метод forEach(), который позволяет выполнить действие для каждой записи в Map:
Map<Integer, String> map = new HashMap<>();
// добавление элементов в map
map.forEach((key, value) -> {
// обработка каждой записи (ключ + значение)
System.out.println(key + ": " + value);
});
В этом примере map.forEach() выполняет переданное лямбда-выражение для каждой записи в Map, где первый параметр - это ключ, а второй - значение.
Обратите внимание, что при переборе записей с помощью метода entrySet() порядок обхода записей не гарантируется. Если нужно гарантировать определенный порядок обхода записей, например, в порядке добавления элементов, можно использовать другие структуры данных, такие как LinkedHashMap.
894. В чем отличия TreeSet и HashSet?
TreeSet и HashSet - это две разные реализации интерфейса Set, которые предназначены для хранения уникальных элементов в коллекции. Но есть несколько отличий между ними:
Упорядоченность: TreeSet хранит элементы в отсортированном порядке, а HashSet не гарантирует какой-либо определенный порядок элементов.Реализация: TreeSet использует древовидную структуру данных (обычно красно-черное дерево), что обеспечивает быстрый доступ к элементам и поддержку сортировки элементов. В то время как HashSet использует хеш-таблицу для быстрого поиска элементов, но не обеспечивает какую-либо сортировку.Производительность: TreeSet имеет логарифмическую производительность для основных операций (добавление, удаление, поиск), то есть O(log n), тогда как производительность HashSet является константной (O(1)) за исключением случаев коллизии хеш-функции, когда производительность может быть линейной (O(n)).Дубликаты: TreeSet не позволяет хранить дубликаты элементов, а HashSet удаляет дубликаты элементов, которые попытаются быть добавлены в коллекцию.
В целом, если нам нужно хранить элементы в отсортированном порядке или быстро выполнять операции над множеством (Set), то следует использовать TreeSet. Если же требуется быстрый доступ к элементам и отсутствие дубликатов, то следует использовать HashSet.
895. Что будет, если добавлять элементы в TreeSet по возрастанию?
Если добавлять элементы в TreeSet по возрастанию, то они будут располагаться внутри коллекции в отсортированном порядке. Так как TreeSet использует древовидную структуру данных (обычно красно-черное дерево), то каждый вновь добавляемый элемент будет помещен в вершину дерева и сравнен со своими предшественниками и потомками.
В результате каждый элемент будет расположен в коллекции так, чтобы сохранить упорядоченность по возрастанию. При этом процесс добавления элементов может занять больше времени, чем простое добавление элементов в HashSet, но поиск или удаление элементов будет происходить гораздо быстрее, благодаря особенностям реализации древовидной структуры.
Обратите внимание, что при добавлении элементов в TreeSet необходимо использовать типы данных, которые могут быть сравнимы с помощью оператора compareTo(). Если тип данных не поддерживает интерфейс Comparable, то необходимо создать объект TreeSet с компаратором, который позволяет определить порядок элементов в коллекции.
896. Чем LinkedHashSet отличается от HashSet?
LinkedHashSet и HashSet - это две реализации интерфейса Set, которые предназначены для хранения уникальных элементов в коллекции. Но есть несколько отличий между ними:
Упорядоченность: LinkedHashSet поддерживает порядок вставки элементов, тогда как HashSet не гарантирует какой-либо порядок элементов.Реализация: LinkedHashSet наследует свойства HashSet и использует хеш-таблицу для быстрого поиска элементов, но также поддерживает двусвязный список, который сохраняет порядок вставки элементов. В то время как HashSet использует только хеш-таблицу.Производительность: производительность LinkedHashSet является немного медленнее, чем производительность HashSet за счет дополнительной работы по обновлению связного списка при изменении коллекции.Дубликаты: LinkedHashSet не позволяет хранить дубликаты элементов, а HashSet удаляет дубликаты элементов, которые попытаются быть добавлены в коллекцию.
В целом, если нужно сохранять порядок вставки элементов в коллекцию и она содержит небольшое количество элементов (до 10 тысяч), то следует использовать LinkedHashSet. Если же требуется быстрый доступ к элементам и отсутствие дубликатов, то следует использовать HashSet.
897. Для Enum есть специальный класс java.util.EnumSet. Зачем? Чем авторов не устраивал HashSet или TreeSet?
EnumSet - это специализированная реализация интерфейса Set для работы с перечислениями (enum) в Java. Она была разработана для оптимизации производительности и использования памяти при работе с перечислениями.
Основные отличия EnumSet от других реализаций Set, таких как HashSet или TreeSet, заключаются в следующем:
Предназначение: EnumSet предназначен для работы именно с перечислениями, что сильно упрощает код и улучшает его читаемость. Кроме того, EnumSet гарантирует, что элементы набора всегда будут являться экземплярами конкретного перечисления, которое задается при создании набора.Быстродействие: EnumSet быстрее HashSet и TreeSet при работе с перечислениями благодаря особой внутренней реализации. EnumSet использует битовые множества (bit sets), что обеспечивает эффективное использование памяти и быстрый доступ к элементам.Размерность: EnumSet может быть использован только для ограниченного количества значений перечисления (обычно не более 64). Но для большинства типов перечислений этого достаточно.Неизменяемость: EnumSet не является неизменяемой коллекцией, но он поддерживает операции добавления и удаления элементов только в рамках одного перечисления. Таким образом, изменение набора элементов происходит безопасно и не приводит к ошибкам или исключениям.
В целом, EnumSet - это оптимальный выбор для работы с перечислениями в Java в тех случаях, когда нужно быстро работать с ограниченным количеством элементов перечисления и требуется максимальное быстродействие и эффективное использование памяти. Если же нужно работать с большим количеством элементов или элементами других типов, то следует использовать стандартные реализации Set, такие как HashSet или TreeSet.
898. Какие существуют способы перебирать элементы списка?
В Java существует несколько способов перебирать элементы списка (например, ArrayList, LinkedList и т.д.). Рассмотрим некоторые из них:
Цикл for-each:
List<String> list = new ArrayList<>();
// добавление элементов в список
for (String item : list) {
// обработка каждого элемента
System.out.println(item);
}
Использование итератора:
List<String> list = new ArrayList<>();
// добавление элементов в список
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
// обработка каждого элемента
System.out.println(item);
}
Цикл for со счетчиком:
List<String> list = new ArrayList<>();
// добавление элементов в список
for (int i = 0; i < list.size(); i++) {
String item = list.get(i);
// обработка каждого элемента
System.out.println(item);
}
Лямбда-выражение forEach() (доступно начиная с Java 8):
List<String> list = new ArrayList<>();
// добавление элементов в список
list.forEach(item -> {
// обработка каждого элемента
System.out.println(item);
});
Stream API (доступно начиная с Java 8):
List<String> list = new ArrayList<>();
// добавление элементов в список
list.stream().forEach(item -> {
// обработка каждого элемента
System.out.println(item);
});
Какой способ выбрать зависит от задачи и личных предпочтений. Однако, если необходимо изменять список в процессе перебора его элементов, то лучше использовать итератор, так как он позволяет безопасно добавлять и удалять элементы из списка.
899. Каким образом можно получить синхронизированные объекты стандартных коллекций?
В Java для получения синхронизированных объектов стандартных коллекций (например, ArrayList, LinkedList, HashMap и т.д.) можно использовать методы класса Collections. Эти методы позволяют создавать обертки вокруг стандартных коллекций, которые гарантируют потокобезопасность при работе с коллекциями.
Рассмотрим несколько примеров:
Обертка вокруг ArrayList:
List<String> list = new ArrayList<>();
// добавление элементов в список
List<String> synchronizedList = Collections.synchronizedList(list);
В данном примере метод Collections.synchronizedList() создает обертку вокруг списка list, который будет синхронизирован при доступе к его методам. При этом любое изменение списка должно быть выполнено в блоке синхронизации.
Обертка вокруг HashMap:
Map<String, Integer> map = new HashMap<>();
// добавление элементов в карту
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(map);
Метод Collections.synchronizedMap() создает обертку вокруг карты map, которая также будет синхронизирована при доступе к ее методам.
Обертка вокруг HashSet:
Set<String> set = new HashSet<>();
// добавление элементов в множество
Set<String> synchronizedSet = Collections.synchronizedSet(set);
Метод Collections.synchronizedSet() создает обертку вокруг множества set, которая будет синхронизирована при доступе к его методам.
Обратите внимание, что при использовании синхронизированных коллекций необходимо использовать блок синхронизации при любых операциях, которые могут изменить состояние коллекции. Это важно для обеспечения потокобезопасности и предотвращения возможных ошибок или исключений.
900. Как получить коллекцию только для чтения?
В Java можно получить коллекцию только для чтения, чтобы предотвратить изменение ее содержимого. Вот несколько способов создания коллекции только для чтения:
Метод Collections.unmodifiableCollection():
List<String> list = new ArrayList<>();
list.add("элемент1");
list.add("элемент2");
Collection<String> readOnlyCollection = Collections.unmodifiableCollection(list);
Метод Collections.unmodifiableList() (для списков):
List<String> list = new ArrayList<>();
list.add("элемент1");
list.add("элемент2");
List<String> readOnlyList = Collections.unmodifiableList(list);
Метод Collections.unmodifiableSet() (для наборов):
Set<String> set = new HashSet<>();
set.add("элемент1");
set.add("элемент2");
Set<String> readOnlySet = Collections.unmodifiableSet(set);
Метод Collections.unmodifiableMap() (для карт):
Map<String, Integer> map = new HashMap<>();
map.put("ключ1", 1);
map.put("ключ2", 2);
Map<String, Integer> readOnlyMap = Collections.unmodifiableMap(map);
Созданные таким образом коллекции только для чтения будут выбрасывать исключение UnsupportedOperationException, если попытаться изменить их содержимое (например, добавить или удалить элементы).
Важно отметить, что коллекция только для чтения является неизменяемой в терминах структуры данных, но сама коллекция может содержать изменяемые элементы. Если элементы внутри коллекции могут быть изменены, то эти изменения будут отражаться в коллекции только для чтения. Если требуется полная иммутабельность, то необходимо использовать неизменяемые (immutable) коллекции, такие как ImmutableList, ImmutableSet и т.д. из библиотеки Google Guava или List.of(), Set.of() и т.д. из Java 9+.
901. Напишите однопоточную программу, которая заставляет коллекцию выбросить ConcurrentModificationException.
Конкурирующая модификация (ConcurrentModificationException) возникает, когда коллекция изменяется во время итерации без использования соответствующих механизмов синхронизации. Вот пример однопоточной программы, которая вызывает ConcurrentModificationException:
import java.util.ArrayList;
import java.util.List;
public class ConcurrentModificationExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
for (Integer number : numbers) {
numbers.remove(number); // Изменение коллекции во время итерации
}
}
}
В этом примере мы создаем список numbers и добавляем в него несколько элементов. Затем мы выполняем итерацию по списку с помощью цикла for-each и пытаемся удалить каждый элемент из списка внутри цикла. Это вызывает ConcurrentModificationException, потому что мы изменяем список во время итерации.
Чтобы избежать ConcurrentModificationException, следует использовать итератор и его методы для добавления или удаления элементов. Например:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ConcurrentModificationExample {
public static void main(String[] args) {
List<Integer> numbers = new ArrayList<>();
numbers.add(1);
numbers.add(2);
numbers.add(3);
Iterator<Integer> iterator = numbers.iterator();
while (iterator.hasNext()) {
Integer number = iterator.next();
iterator.remove(); // Используем метод remove() итератора для удаления элемента
}
}
}
В этом примере мы используем итератор для обхода списка numbers. Метод iterator.remove() позволяет безопасно удалять элементы из коллекции во время итерации, и это не вызывает ConcurrentModificationException.
Обратите внимание, что настоящая потребность в использовании ConcurrentModificationException возникает в многопоточных сценариях, когда несколько потоков одновременно модифицируют одну коллекцию. В однопоточных сценариях использование ConcurrentModificationException неразумно и может указывать на ошибку в логике программы.
902. Приведите пример, когда какая-либо коллекция выбрасывает UnsupportedOperationException.
Исключение UnsupportedOperationException выбрасывается, когда операция не поддерживается или не может быть выполнена на данной коллекции. Вот несколько примеров, когда может возникнуть UnsupportedOperationException:
Изменение коллекции только для чтения:
import java.util.Collections;
import java.util.List;
public class UnsupportedOperationExceptionExample {
public static void main(String[] args) {
List<String> readOnlyList = Collections.singletonList("элемент");
readOnlyList.add("новый элемент"); // Выбросится UnsupportedOperationException
}
}
В этом примере мы создаем список readOnlyList с помощью метода Collections.singletonList(), который возвращает коллекцию только для чтения. Попытка добавления нового элемента вызовет UnsupportedOperationException, поскольку изменение коллекции только для чтения запрещено.
Использование неизменяемой коллекции из Java 9+:
import java.util.List;
public class UnsupportedOperationExceptionExample {
public static void main(String[] args) {
List<String> immutableList = List.of("элемент");
immutableList.add("новый элемент"); // Выбросится UnsupportedOperationException
}
}
В этом примере мы используем метод List.of() из Java 9+, чтобы создать неизменяемый список immutableList. Попытка добавления нового элемента вызовет UnsupportedOperationException, так как неизменяемые коллекции не поддерживают изменение своего содержимого.
Использование неизменяемой коллекции из Google Guava:
import com.google.common.collect.ImmutableList;
import java.util.List;
public class UnsupportedOperationExceptionExample {
public static void main(String[] args) {
List<String> immutableList = ImmutableList.of("элемент");
immutableList.add("новый элемент"); // Выбросится UnsupportedOperationException
}
}
В этом примере мы используем метод ImmutableList.of() из библиотеки Google Guava для создания неизменяемого списка immutableList. Попытка добавления нового элемента вызовет UnsupportedOperationException.
Использование неподдерживаемой операции на специфичной реализации коллекции:
import java.util.LinkedList;
import java.util.List;
public class UnsupportedOperationExceptionExample {
public static void main(String[] args) {
List<String> linkedList = new LinkedList<>();
linkedList.add("элемент1");
linkedList.add("элемент2");
List<String> subList = linkedList.subList(0, 1);
subList.clear(); // Выбросится UnsupportedOperationException
}
}
В этом примере мы создаем связанный список linkedList и получаем его подсписок с помощью метода subList(). Попытка очистить подсписок вызовет UnsupportedOperationException, поскольку операция clear() неподдерживается для подсписков, возвращенных методом subList().
В каждом из этих примеров возникает UnsupportedOperationException при попытке изменить коллекцию или выполнить неподдерживаемую операцию на ней.
903. Реализуйте симметрическую разность двух коллекций используя методы Collection (addAll(...), removeAll(...), retainAll(...)).
Для реализации симметрической разности двух коллекций можно использовать методы addAll(), removeAll() и retainAll() из интерфейса Collection. Вот пример Java кода, демонстрирующий это:
import java.util.ArrayList;
import java.util.Collection;
public class SymmetricDifferenceExample {
public static <T> Collection<T> symmetricDifference(Collection<? extends T> collection1,
Collection<? extends T> collection2) {
Collection<T> difference = new ArrayList<>(collection1);
// Добавляем элементы из второй коллекции, которых нет в первой коллекции
difference.addAll(collection2);
// Удаляем элементы, которые есть и в первой, и во второй коллекциях
difference.removeAll(collection1);
difference.removeAll(collection2);
return difference;
}
public static void main(String[] args) {
Collection<Integer> collection1 = new ArrayList<>();
collection1.add(1);
collection1.add(2);
collection1.add(3);
Collection<Integer> collection2 = new ArrayList<>();
collection2.add(3);
collection2.add(4);
collection2.add(5);
Collection<Integer> symmetricDifference = symmetricDifference(collection1, collection2);
System.out.println("Симметрическая разность: " + symmetricDifference);
}
}
В этом примере у нас есть метод symmetricDifference(), который принимает две коллекции в качестве параметров и возвращает их симметрическую разность. Мы создаем новую коллекцию difference, копируя элементы из первой коллекции. Затем мы добавляем все элементы из второй коллекции, которых нет в первой коллекции, используя метод addAll(). Далее мы удаляем все элементы, которые есть как в первой, так и во второй коллекциях, с помощью метода removeAll(). В результате получаем коллекцию, содержащую только элементы, присутствующие только в одной из исходных коллекций.
В данном примере мы используем коллекции ArrayList для наглядности, но этот код будет работать с любыми реализациями интерфейса Collection.
904. Как, используя LinkedHashMap, сделать кэш c «invalidation policy»?
Для создания кэша с политикой "invalidation" (сброса) на основе LinkedHashMap вам потребуется создать пользовательский класс, расширяющий LinkedHashMap и переопределить метод removeEldestEntry().
Вот пример реализации такого класса:
import java.util.LinkedHashMap;
import java.util.Map;
public class InvalidationCache<K, V> extends LinkedHashMap<K, V> {
private final int maxSize;
public InvalidationCache(int maxSize) {
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
}
В этом примере мы создали класс InvalidationCache, который расширяет LinkedHashMap. Мы добавили конструктор, который принимает максимальный размер кэша. В методе removeEldestEntry() мы проверяем, превышает ли текущий размер кэша максимальный размер maxSize. Если это так, то старая запись будет удалена при добавлении новой записи.
Вы можете использовать InvalidationCache следующим образом:
public static void main(String[] args) {
InvalidationCache<String, Integer> cache = new InvalidationCache<>(3);
cache.put("key1", 1);
cache.put("key2", 2);
cache.put("key3", 3);
System.out.println(cache); // {key1=1, key2=2, key3=3}
cache.put("key4", 4);
System.out.println(cache); // {key2=2, key3=3, key4=4}
}
В этом примере мы создали экземпляр InvalidationCache с максимальным размером 3. Затем мы добавили четыре записи в кэш. При добавлении четвертой записи старая запись "key1" была удалена, так как размер кэша превысил максимальный размер.
Обратите внимание, что LinkedHashMap обеспечивает порядок элементов в соответствии с порядком их добавления.
905. Как одной строчкой скопировать элементы любой collection в массив?
Для копирования элементов из коллекции в массив можно использовать метод toArray() из интерфейса Collection. Вот пример однострочного кода:
Collection<String> collection = new ArrayList<>();
// Добавьте элементы в коллекцию
String[] array = collection.toArray(new String[0]);
В этом примере мы создали экземпляр коллекции ArrayList и добавили в неё элементы (замените ArrayList на любую другую коллекцию, если требуется). Затем мы используем метод toArray(), передавая ему новый массив типа String с размером 0. Метод toArray() создаст новый массив того же типа, что и коллекция, и скопирует элементы коллекции в этот массив.
Обратите внимание, что при передаче пустого массива (new String[0]) будет создан новый массив нужного типа и правильного размера, чтобы вместить все элементы коллекции. Если вы хотите использовать массив заданного размера, вы можете создать его заранее и передать его в метод toArray().
906. Как одним вызовом из List получить List со всеми элементами, кроме первых и последних 3-х?
Вы можете использовать метод subList() из класса java.util.List, чтобы получить подсписок с элементами, кроме первых и последних трёх. Вот пример однострочного кода:
List<String> originalList = new ArrayList<>();
// Добавьте элементы в исходный список
List<String> resultList = originalList.subList(3, originalList.size() - 3);
В этом примере мы создали исходный список originalList и добавили в него элементы (замените ArrayList на любую другую реализацию интерфейса List, если нужно). Затем мы используем метод subList(startIndex, endIndex) для получения подсписка. В данном случае, мы указываем индекс начала подсписка как 3 (исключая первые три элемента) и индекс конца подсписка как originalList.size() - 3 (исключая последние три элемента).
Обратите внимание, что метод subList() возвращает представление (view) подсписка, которое является частью исходного списка. Любые изменения в представлении подсписка будут отражаться на исходном списке и наоборот. Если вам нужен новый экземпляр списка с выбранными элементами, вы можете создать новый список и передать в него элементы из подсписка, используя конструктор или метод addAll().
907. Как одной строчкой преобразовать HashSet в ArrayList?
Вы можете преобразовать HashSet в ArrayList одной строчкой, используя конструктор класса ArrayList и передавая HashSet в качестве аргумента. Вот пример кода:
HashSet<String> hashSet = new HashSet<>();
// Добавьте элементы в HashSet
ArrayList<String> arrayList = new ArrayList<>(hashSet);
В этом примере мы создали экземпляр HashSet с именем hashSet и добавили в него элементы (замените HashSet на любую другую реализацию интерфейса Set, если нужно). Затем мы создали новый экземпляр ArrayList с именем arrayList и передали hashSet в качестве аргумента конструктору ArrayList. Конструктор ArrayList автоматически создаст новый список и заполнит его элементами из hashSet.
Обратите внимание, что порядок элементов в ArrayList может отличаться от исходного порядка в HashSet, так как ArrayList является упорядоченным списком, а HashSet не гарантирует определенный порядок элементов.
908. Как одной строчкой преобразовать ArrayList в HashSet?
Вы можете преобразовать ArrayList в HashSet одной строчкой, используя конструктор класса HashSet и передавая ArrayList в качестве аргумента. Вот пример кода:
ArrayList<String> arrayList = new ArrayList<>();
// Добавьте элементы в ArrayList
HashSet<String> hashSet = new HashSet<>(arrayList);
В этом примере мы создали экземпляр ArrayList с именем arrayList и добавили в него элементы (замените ArrayList на любую другую реализацию интерфейса List, если нужно). Затем мы создали новый экземпляр HashSet с именем hashSet и передали arrayList в качестве аргумента конструктору HashSet. Конструктор HashSet автоматически создаст новое множество и заполнит его элементами из arrayList.
Обратите внимание, что HashSet не гарантирует определенный порядок элементов, так как это множество без дубликатов. Если порядок элементов имеет значение, вам может потребоваться использовать другую реализацию интерфейса Set, которая сохраняет порядок элементов, например, LinkedHashSet.
909. Сделайте HashSet из ключей HashMap.
Чтобы создать HashSet из ключей HashMap, вы можете использовать конструктор класса HashSet и передать в него множество ключей, полученных с помощью метода keySet() из объекта HashMap. Вот пример кода:
HashMap<String, Integer> hashMap = new HashMap<>();
// Добавьте элементы в HashMap
HashSet<String> keySet = new HashSet<>(hashMap.keySet());
В этом примере мы создали экземпляр HashMap с именем hashMap и добавили в него элементы (замените HashMap на любую другую реализацию интерфейса Map, если нужно). Затем мы вызываем метод keySet(), который возвращает множество ключей HashMap. Мы передаем это множество в качестве аргумента конструктору HashSet, создавая новый экземпляр HashSet с именем keySet.
Теперь у вас есть HashSet, содержащий все ключи, которые были в HashMap. Обратите внимание, что порядок элементов в HashSet не гарантируется, так как HashSet представляет множество без дубликатов. Если порядок ключей имеет значение, вам может потребоваться использовать другую реализацию интерфейса Set, которая сохраняет порядок элементов, например, LinkedHashSet.
910. Сделайте HashMap из HashSet<Map.Entry<K, V>>.
Чтобы создать HashMap из HashSet<Map.Entry<K, V>>, вы можете использовать цикл для прохода по элементам HashSet и добавления каждой записи в новый HashMap. Вот пример кода:
HashSet<Map.Entry<K, V>> entrySet = new HashSet<>();
// Добавьте элементы в HashSet
HashMap<K, V> hashMap = new HashMap<>();
for (Map.Entry<K, V> entry : entrySet) {
hashMap.put(entry.getKey(), entry.getValue());
}
В этом примере мы создали экземпляр HashSet<Map.Entry<K, V>> с именем entrySet и добавили в него элементы (замените HashSet на любую другую реализацию интерфейса Set, если нужно). Затем мы создали новый экземпляр HashMap<K, V> с именем hashMap.
Мы используем цикл for-each для прохода по элементам entrySet. Для каждого элемента entry мы вызываем методы getKey() и getValue() для получения ключа и значения записи и используем метод put() для добавления этой записи в hashMap.
Теперь у вас есть HashMap, содержащая все записи, которые были в HashSet<Map.Entry<K, V>>.
5. Строки (перейти в раздел)
911. Какие “строковые” классы вы знаете?
На Java есть несколько классов, связанных со строками:
-
String, который является неизменяемым объектом для хранения строки. -
StringBuilder, который является изменяемым объектом для построения строки. -
StringBuffer, который также является изменяемым объектом для хранения и модификации строки, но является потокобезопасным и может использоваться в многопоточных приложениях. -
CharSequence, который является интерфейсом для работы с последовательностями символов, включая строки.
Эти классы могут использоваться для различных задач, связанных со строками в Java.
912. Какие основные свойства “строковых” классов (их особенности)?
Основные свойства "строковых" классов в Java (String, StringBuffer, StringBuilder):
-
Неизменяемость: Объекты класса String не могут быть изменены после создания. Каждый метод, который изменяет строку, фактически создает новый объект, а не изменяет существующий. В StringBuffer и StringBuilder объекты могут быть изменены после создания, и новые объекты не создаются при использовании различных методов. -
Потокобезопасность: StringBuffer является потокобезопасным классом, позволяющим многопоточные операции над строками. StringBuilder не является потокобезопасным классом, но имеет более высокую производительность. -
Производительность: StringBuffer и StringBuilder быстрее, чем String, при частых операциях конкатенации или изменении строк. -
Буферизация: StringBuffer и StringBuilder создаются с начальной емкостью буфера, чтобы предотвратить излишние выделения памяти при изменении или добавлении символов в строку. -
Операции со строками: В классах StringBuffer и StringBuilder есть множество методов для работы со строками, такие как вставка, удаление, замена, конкатенация, обращение символов и т.д. -
Методы сравнения: Объекты класса String имеют множество методов сравнения строк, например, методы equals() и compareTo(). Методы сравнения не поддерживаются в StringBuffer и StringBuilder, так как они не предназначены для выполнения операций сравнения, а в первую очередь для работы со строками.
913. Можно ли наследовать строковый тип, почему?
Да, в Java класс String может быть унаследован. Однако, класс String объявлен как final, поэтому он не может быть унаследован другими классами. Это означает, что нельзя создать подкласс от String и переопределить его методы, такие как equals() или toString().
Наследование заключается в том, чтобы создать новый класс, который расширяет или наследует функциональность уже существующего класса. Это позволяет создавать иерархию классов, где подклассы наследуют свойства и методы из класса-родителя.
В случае с классом String, можно использовать его в дочерних классах как обычную строку, но нельзя изменять его поведение.
Например,
public class MyString extends String {
// Код
}
будет вызывать ошибку компиляции, поскольку String объявлен как final.
Также можно создать новый класс и использовать объекты String в нем как обычный объект.
914. Дайте определение понятию конкатенация строк.
Конкатенация строк - это операция объединения двух или более строк в одну строку. В Java для конкатенации строк можно использовать оператор +. Например:
String str1 = "Hello";
String str2 = "World";
String result = str1 + " " + str2;
System.out.println(result); // output: "Hello World"
В данном примере мы объединяем значения переменных str1 и str2, а также вставляем между ними пробел. Результат конкатенации сохраняем в переменной result.
915. Как преобразовать строку в число?
Чтобы преобразовать строку в число в Java, вы можете использовать методы синтаксического анализа классов-оболочек для соответствующего числового типа. Вот некоторые примеры:
- Чтобы преобразовать строку в целое число:
String str = "123";
int num = Integer.parseInt(str);
- Чтобы преобразовать строку в double:
String str = "3.14";
double num = Double.parseDouble(str);
- Чтобы преобразовать строку в long:
String str = "9876543210";
long num = Long.parseLong(str);
Обратите внимание, что эти функции вызывают исключение NumberFormatException, если входная строка не является допустимым представлением числа. Кроме того, вы можете использовать метод valueOf классов-оболочек для преобразования строки в число:
String str = "456";
Integer num = Integer.valueOf(str);
Это возвращает объект Integer, а не примитивный int. Кроме того, метод valueOf может обрабатывать ввод null, а методы синтаксического анализа — нет.
916. Как сравнить значение двух строк?
Вы можете сравнить значения двух строк в Java, используя метод equals() или compareTo(). Метод equals() сравнивает значения двух объектов типа String на идентичность, тогда как метод compareTo() сравнивает значения двух объектов типа String лексикографически.
Вот примеры использования обоих методов:
String str1 = "hello";
String str2 = "world";
String str3 = "hello";
// использование метода equals()
if(str1.equals(str3)){
System.out.println("str1 и str3 равны");
} else {
System.out.println("str1 и str3 не равны");
}
// использование метода compareTo()
if(str1.compareTo(str2) < 0){
System.out.println("str1 меньше, чем str2");
} else if(str1.compareTo(str2) > 0){
System.out.println("str1 больше, чем str2");
} else {
System.out.println("str1 и str2 равны");
}
В этом примере str1 и str3 равны, потому что они содержат одинаковые значения. Второй блок if-else сравнивает str1 и str2 лексикографически и выдаст сообщение, что str1 меньше, чем str2.
917. Как перевернуть строку?
Для переворачивания строки на Java есть несколько способов:
Использование StringBuilder/StringBuffer
String originalString = "Hello World!";
StringBuilder stringBuilder = new StringBuilder(originalString);
String reversedString = stringBuilder.reverse().toString();
System.out.println(reversedString);
Рекурсивная функция
public static String reverseStringWithRecursion(String str) {
if (str.length() <= 1) {
return str;
}
return reverseStringWithRecursion(str.substring(1)) + str.charAt(0);
}
String originalString = "Hello World!";
String reversedString = reverseStringWithRecursion(originalString);
System.out.println(reversedString);
Использование метода reverse() класса StringTokenizer
String originalString = "Hello World!";
StringTokenizer tokenizer = new StringTokenizer(originalString, " ");
String reversedString = "";
while (tokenizer.hasMoreTokens()) {
StringBuilder stringBuilder = new StringBuilder(tokenizer.nextToken());
reversedString += stringBuilder.reverse().toString() + " ";
}
System.out.println(reversedString.trim());
Использовать цикл for или while, чтобы перебирать символы строки в обратном порядке и добавлять их в новую строку. Пример:
String originalString = "Привет, мир!";
String reversedString = "";
for (int i = originalString.length() - 1; i >= 0; i--) {
reversedString += originalString.charAt(i);
}
System.out.println(reversedString);
Это также выведет !рим ,тевирП на консоль. Однако, использование классов StringBuilder или StringBuffer более эффективно, когда вы работаете с большими строками или выполняете многократные операции реверсирования строки.
Это лишь несколько примеров того, как можно перевернуть строку на Java. Важно выбрать самый оптимальный способ в зависимости от конкретной задачи.
918. Как работает сравнение двух строк?
В Java есть два способа сравнения строк:
-
Оператор ==сравнивает ссылки объектов, а не значения. Таким образом, оператор == возвращает true только если обе переменные ссылаться на один и тот же объект. -
Метод equals()сравнивает значения объектов, а не ссылки. Метод equals() сравнивает символьную последовательность, содержащуюся в двух строках, игнорируя регистр.
Пример использования операторов сравнения и метода equals() в Java:
String str1 = "Hello";
String str2 = "Hello";
String str3 = new String("Hello");
// использование оператора сравнения
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // false
// использование метода equals()
System.out.println(str1.equals(str2)); // true
System.out.println(str1.equals(str3)); // true
статический метод compare()класса String, который используется для лексикографического сравнения двух строк. Этот метод возвращает значение 0, если строки равны; значение меньше нуля, если первая строка меньше второй, и значение больше нуля, если первая строка больше второй.
Пример:
String str1 = "apple";
String str2 = "orange";
int result = str1.compareTo(str2);
if (result < 0) {
System.out.println("str1 меньше, чем str2");
} else if (result > 0) {
System.out.println("str1 больше, чем str2");
} else {
System.out.println("str1 и str2 равны");
}
Этот пример выведет на экран "str1 меньше, чем str2", потому что строки сравниваются лексикографически и "apple" идет перед "orange" в алфавитном порядке.
919. Как обрезать пробелы в конце строки?
Для удаления пробелов в конце строки в Java можно использовать метод trim(). Он удаляет все начальные и конечные пробелы строки.
Пример использования:
String str = " example string ";
String trimmed = str.trim(); // "example string"
Метод trim() возвращает новую строку без пробелов в начале и в конце. Оригинальная строка остается неизменной.
Также можно использовать метод replaceAll() с регулярным выражением, чтобы удалить все символы пробела в конце строки:
String str = " example string ";
String trimmed = str.replaceAll("\\s+$", ""); // "example string"
В этом примере регулярное выражение \s+$ соответствует любым символам пробела, которые находятся в конце строки.
920. Как заменить символ в строке?
Чтобы заменить символ в строке в Java, вы можете использовать метод replace(). Вот пример фрагмента кода, который заменяет все вхождения символа «a» на «b» в заданной строке:
String str = "example string";
String newStr = str.replace('a', 'b');
System.out.println(newStr);
Это выведет «строку exbmple», которая является исходной строкой со всеми экземплярами «a», замененными на «b». Обратите внимание, что метод replace() возвращает новую строку, поэтому важно сохранить результат в новой переменной (в данном примере, newStr), если вы хотите сохранить измененную строку.
Если вы хотите заменить подстроку другой подстрокой, вы можете использовать метод replace() со строковыми аргументами вместо символьных аргументов. Вот пример, который заменяет все вхождения подстроки «привет» на «до свидания» в заданной строке:
String str = "hello world, hello everyone";
String newStr = str.replace("hello", "goodbye");
System.out.println(newStr);
Это выведет "goodbye world, goodbye everyone".
921. Как получить часть строки?
Для получения части строки в Java вы можете использовать метод substring(startIndex, endIndex) класса String. Метод извлекает из строки подстроку, начиная с индекса startIndex и заканчивая endIndex - 1. Если endIndex не указан, то возвращается подстрока, начиная с startIndex и до конца строки.
Вот пример использования метода substring():
String str = "Hello World!";
String substr1 = str.substring(0, 5); // извлекаем "Hello"
String substr2 = str.substring(6); // извлекаем "World!"
В этом примере, мы создали новую строку str, а затем использовали метод substring() для извлечения двух подстрок: с 0-го по 4-й символ и с 6-го символа до конца строки.
Обратите внимание, что строки в Java неизменяемы, поэтому метод substring() не изменяет исходную строку, а возвращает новую строку - подстроку исходной.
Также в Java есть еще методы извлечения части строки, такие как subSequence() и charAt().
- Если нужно получить один символ строки по его индексу, можно воспользоваться методом charAt():
char ch = str.charAt(0); // Получаем первый символ строки
- Вот пример использования метода subSequence() для извлечения части строки:
String str = "Hello World";
CharSequence sub = str.subSequence(0, 5); // извлечь первые 5 символов
System.out.println(sub); // печатает "Hello"
922. Дайте определение понятию “пул строк”.
В Java "пул строк" (string pool) - это механизм оптимизации памяти, при котором каждая уникальная строка, созданная в программе, сохраняется в пуле строк. Если другая строка с тем же значением создается позже, то она не создается, а ссылается на уже существующую строку в пуле. Таким образом, память оптимизируется и избегается создание большого количества одинаковых строк.
Например, вот как создается строка "hello":
String s = "hello";
Эта строка помещается в пул строк. При создании другой строки с тем же значением:
String t = "hello";
возвращается ссылка на уже созданный объект, поэтому t ссылается на тот же объект в пуле строк, что и s.
Когда строки создаются через литералы (например, "hello"), они автоматически помещаются в пул строк. Также можно явно поместить строку в пул с помощью метода intern(). Например:
String str1 = "hello"; // создание строки через литерал
String str2 = new String("hello"); // создание строки через объект
boolean isSameObject = str1 == str2; // false, так как два разных объекта
boolean isSameValue = str1.equals(str2); // true, так как содержимое строк одинаковое
String str3 = str2.intern(); // явное помещение в пул строк
boolean isSameObject2 = str1 == str3; // true, так как оба объекта ссылается на одну строку в пуле
Использование пула строк может существенно улучшить производительность программы и сократить потребление памяти при работе с большим количеством одинаковых строк. Однако, если необходимо работать со строками с большим объемом данных, следует быть осторожным с использованием пула строк, так как это может привести к утечке памяти.
923. Какой метод позволяет выделить подстроку в строке?
В Java для выделения подстроки в строке можно использовать метод substring() класса String. Этот метод принимает два аргумента - начальный и конечный индексы подстроки (включительно) и возвращает новую строку, содержащую только указанную подстроку. Например:
String str = "Hello, World!";
String substr = str.substring(7, 12);
System.out.println(substr); // выводит "World"
Если второй аргумент метода substring() не указан, то он будет вырезать все символы от указанного индекса до конца строки. Или, если второй аргумент превышает длину строки, то он будет вырезать все символы от указанного индекса до конца строки. Например:
String str = "Hello, World!";
String substr1 = str.substring(7); // вырежет "World!"
String substr2 = str.substring(7, 20); // вырежет "World!"
substr1 будет равен "World!", а substr2 будет равен "World".
924. Как разбить строку на подстроки по заданному разделителю?
В Java можно использовать метод split(), который разделяет строку на подстроки по определенному разделителю. Вот пример использования:
String str = "разделенные|строки|по|вертикальной черте";
String[] substrings = str.split("\\|");
В данном примере строка str разделяется на массив подстрок substrings с помощью разделителя "|". Обратите внимание на то, что строка разделителя нуждается в экранировании, поэтому используется двойной слэш .
Вы также можете использовать регулярные выражения вместо обычной строки в split() для более продвинутой обработки текста.
Например, представим, что у нас есть строка "раз,два,три" и мы хотим получить массив строк ["раз", "два", "три"]. Мы можем использовать следующий код:
String str = "раз,два,три";
String[] arr = str.split(",");
В этом примере мы передаем разделитель (",") в качестве аргумента метода split(). Метод разбивает исходную строку на элементы массива, используя разделитель, и возвращает полученный массив строк.
Если требуется использовать разделитель, который является регулярным выражением (например, точка или знак вопроса), то перед разделителем следует добавлять слеш (/). Например:
String str = "раз.два.три";
String[] arr = str.split("\\.");
Вот пример использования метода split() для разбивки строки на подстроки по новой строке:
String str = "Привет\nмир\nJava";
String[] substrings = str.split("\n");
for (String substring : substrings) {
System.out.println(substring);
}
Этот код выведет:
Привет
мир
Java
925. Какой метод вызывается для преобразования переменной в строку?
В Java метод toString() вызывается для преобразования объекта в строку. Если вы вызываете toString() на объекте, который не является строкой, то возвращаемое значение будет строковое представление объекта. Например:
Integer myInt = 42;
String str = myInt.toString();
В этом примере, toString() вызывается на объекте myInt, который является типом Integer. Эта операция возвращает строковое представление myInt, которое затем присваивается переменной str.
Также, для преобразования примитивного типа в строку вы можете использовать метод String.valueOf(). Например:
int myInt = 42;
String str = String.valueOf(myInt);
В этом примере, примитивное число myInt преобразуется в строку, используя метод String.valueOf().
926. Как узнать значение конкретного символа строки, зная его порядковый номер в строке?
Для того чтобы получить значение конкретного символа строки в Java, зная его порядковый номер, можно использовать метод charAt(). Нумерация символов начинается с нуля. Например, чтобы получить символ строки по ее индексу, можно сделать следующее:
String str = "Hello, world!";
char ch = str.charAt(7); // получаем символ с индексом 7 (букву "w")
System.out.println(ch); // выводим символ в консоль
В данном примере мы получаем символ строки, находящийся под индексом 7, и выводим его значение в консоль.
Также можно использовать оператор квадратных скобок [], чтобы получить символ строки по индексу. Например:
String str = "Hello, world!";
char ch = str[7]; // получаем символ строки с индексом 7 (букву "w")
System.out.println(ch); // выводим символ в консоль
Оба варианта эквивалентны и выполняют одну и ту же задачу.
927. Как найти необходимый символ в строке?
Чтобы найти определенный символ в строке в Java, вы можете использовать метод indexOf() класса String. Например:
String str = "Hello, world!";
char ch = 'o';
int index = str.indexOf(ch);
System.out.println(index);
Это вернет индекс первого появления символа «o» в строке. Если символ не найден, метод indexOf() возвращает -1.
Вы также можете использовать метод charAt() для получения символа по определенному индексу в строке. Например:
char myChar = str.charAt(index);
System.out.println(myChar);
928. Можно ли синхронизировать доступ к строке?
Да, в Java можно синхронизировать доступ к строке, используя ключевое слово synchronized. Если два или более потока пытаются изменить строку одновременно в разных частях кода, может произойти гонка данных (race condition), что приведет к непредсказуемому результату. Для избежания этой ситуации можно объявить метод, который изменяет строку, как synchronized. Например:
public class Example {
private String synchronizedString = "Hello, world!";
public synchronized void appendToString(String str) {
synchronizedString += str;
}
}
В этом примере метод appendToString был объявлен как synchronized, что обеспечивает синхронизированный доступ к строке synchronizedString.
929. Что делает метод intern()?
Метод intern() в Java используется для уменьшения использования памяти при работе со строками. Он возвращает ссылку на объект строки из пула, если такой объект уже существует в пуле, иначе добавляет его в пул и возвращает ссылку на него. Если вы работаете со строками, которые могут иметь одинаковые значения, вызов метода intern() для каждой из них может помочь уменьшить нагрузку на память и ускорить выполнение кода, т.к. меньше объектов будет создано и собрано сборщиком мусора.
Вот пример использования метода intern():
String str1 = "hello";
String str2 = new String("hello");
String str3 = str2.intern();
System.out.println(str1 == str2); // false
System.out.println(str1 == str3); // true
Здесь мы создаем 3 строки: первая создается с помощью литерала, вторая создается с явным вызовом конструктора, а третья получается путем вызова intern() на второй строке. Т.к. первая и третья строки имеют одинаковые значения, они ссылаются на один и тот же объект в пуле строк, в то время как вторая строка создает свой собственный объект.
930. Чем отличаются и что общего у классов String, StringBuffer и StringBuilder?
Классы String, StringBuffer и StringBuilder имеют следующие сходства и различия:
Сходства:
-
- Все три класса позволяют работать с символьными строками в Java.
-
- Все они могут хранить и изменять содержимое строк.
-
- Все три класса находятся в пакете java.lang, что означает, что вы можете использовать их без необходимости импорта.
-
- Все три класса представляют строку в Java, но имеют различное поведение и способы работы со строками.
-
- Все три класса являются неизменяемыми типами данных - это означает, что если вы создали объект String, то вы не можете изменить его содержимое. Например:
String s = "Hello";
s = s + " World"; // создается новый объект String, в переменной s остается ссылка на старый объект
-
- Все три класса могут использоваться для создания и изменения строк.
Различия:
-
- Объекты String являются неизменяемыми, что означает, что содержимое строки нельзя изменить после создания экземпляра. Вместо этого методы класса возвращают новые строковые объекты при изменении содержимого. Это может приводить к большому количеству ненужных объектов в памяти при частых изменениях содержимого.
-
- Объекты StringBuffer и StringBuilder позволяют изменять содержимое строки напрямую, т.е. объект в памяти изменяется непосредственно без создания нового объекта. Разница между ними заключается в том, что StringBuffer является потокобезопасным (thread-safe), т.е. может быть использован в многопоточных приложениях без необходимости использования дополнительных средств синхронизации, в то время как StringBuilder не является потокобезопасным.
-
- В общем случае, если вам требуется часто изменять содержимое строки и не работать в многопоточной среде, лучше использовать StringBuilder, а в случае многопоточности - StringBuffer. Если же содержимое строки не изменяется, используйте String.
-
- String - неизменяемый тип данных, а StringBuffer и StringBuilder - изменяемые. Это означает, что вы можете изменять содержимое объектов StringBuffer и StringBuilder, но не можете изменять объект String.
-
- StringBuffer и StringBuilder могут изменять строки без создания новых объектов, в отличие от String. Это более эффективно, когда вам нужно многократно изменять строку в цикле или при выполнении множественных операций со строками.
-
- StringBuilder быстрее, чем StringBuffer, но не является потокобезопасным.
Как правило, если вы работаете со строками, которые не изменяются, то используйте String. Если вам нужно многократно изменять строку в цикле или при выполнении множественных операций со строками, используйте StringBuffer или StringBuilder. Если вам не нужны функции многопоточности, лучше использовать StringBuilder, так как он быстрее, чем StringBuffer.
931. Как правильно сравнить значения строк двух различных объектов типа String и StringBuffer?
Для того, чтобы сравнить значения строк двух разных объектов типа String и StringBuffer, сначала необходимо привести тип StringBuffer к String. Это можно сделать с помощью метода toString(). Затем можно использовать метод equals() для сравнения значений строк. Например:
String str = "hello";
StringBuffer stringBuffer = new StringBuffer("hello");
if (str.equals(stringBuffer.toString())) {
System.out.println("Строки совпадают");
} else {
System.out.println("Строки не совпадают");
}
Этот код приведет к выводу "Строки совпадают", так как значения строк "hello" и "hello" равны. Обратите внимание, что использование оператора == для сравнения строк может привести к непредсказуемым результатам, так как это сравнивает ссылки на объекты, а не их значения.
- Почему строка неизменная и финализированная в Java? Строки в Java неизменяемы и финализированы (final) по своей природе, поэтому их содержимое не может быть изменено после создания объекта String. Это означает, что если вы попытаетесь изменить содержимое строки, например, путем изменения одного из ее символов, то будет создана новая строка с измененным содержимым, исходная строка останется неизменной.
Это сделано для обеспечения безопасности в многопоточных приложениях, поскольку изменяемые строки могут повредить данные других потоков.
Кроме того, финализация строк обеспечивает иммутабельность строк, то есть изменения строки создают новый объект, что имеет свойство безопасности в многопоточном окружении.
Но если вы все же планируете часто изменять строку в вашем приложении, то лучше использовать StringBuffer или StringBuilder, которые являются изменяемыми (mutable) и улучшают производительность по сравнению со строками, но они могут быть менее безопасными в многопоточных приложениях.
932. Почему массив символов предпочтительнее строки для хранения пароля?
В Java массив символов (char[]) часто используется для хранения пароля вместо строк (String), потому что массивы символов изменяемы и их значения можно перезаписать непосредственно в массиве, в то время как строки являются неизменяемыми (immutable), и любые изменения строки приводят к созданию новой строки в памяти.
Когда пароль хранится в виде строки, он может остаться в памяти намного дольше, чем это необходимо. Это происходит из-за того, что строки не могут быть удалены до тех пор, пока они не удалятся сборщиком мусора (garbage collector). Это делает строки уязвимыми для взлома пароля посредством перехвата содержимого памяти.
Еще один аспект безопасности, когда используют массивы символов, связан с тем, что их можно перезаписать случайным шумом в памяти после того, как они не нужны. Это делает сложнее для злоумышленников взламывать хранилища паролей, поскольку их истинные значения в памяти могут быть перезаписаны шумом.
Таким образом, использование массивов символов для хранения паролей является предпочтительным, потому что они изменяемы и их значения можно перезаписать непосредственно в памяти, а также их содержимое можно легко перезаписать случайным шумом в памяти.
933. Почему строка является популярным ключом в HashMap в Java?
Строки (String) являются популярным типом ключей в HashMap в Java, потому что они имеют хорошо определенный метод хеширования и могут быть использованы для уникальной идентификации объектов. В Java класс String является неизменяемым (immutable), то есть после создания строки ее значение нельзя изменить. Это позволяет использовать строки в качестве ключей безопасности, что они будут изменены после того, как были добавлены в HashMap.
Каждый объект в Java имеет метод hashCode(), который возвращает целочисленное значение, используемое для идентификации объекта в HashMap. Для строк метод hashCode() возвращает уникальное значение на основе содержимого строки, что делает строки хорошими кандидатами для ключей в HashMap.
Кроме того, класс String в Java переопределяет методы equals() и hashCode(), чтобы они сравнивали строки по их содержимому, а не по ссылке на объект. Это позволяет использовать строки, созданные с использованием разных ссылок, но содержащие одинаковое значение, в качестве ключей в HashMap.
В итоге, использование строк в качестве ключей в HashMap облегчает уникальную идентификацию объектов и упрощает работу с ассоциативными массивами в Java.
933. Напишите метод удаления данного символа из строки.
Для удаления заданного символа из строки в Java можно использовать метод replace() класса String. Например, если символ, который нужно удалить, - это буква 'a', то можно сделать следующим образом:
String originalString = "Some string with letter 'a' in it.";
String modifiedString = originalString.replace("a", "");
В данном примере, заменяем все вхождения символа 'a' на пустую строку, что фактически удаляет этот символ из строки. Результат будет записан в переменную modifiedString.
Вот пример метода удаления заданного символа из строки на Java:
public static String removeChar(String str, char ch) {
StringBuilder sb = new StringBuilder();
char[] charArray = str.toCharArray();
for (char c : charArray) {
if (c != ch) {
sb.append(c);
}
}
return sb.toString();
}
Этот метод принимает в качестве параметров строку и символ, который нужно удалить из строки. Метод создает StringBuilder и преобразует заданную строку в массив символов. Затем он проходит по каждому символу в массиве и добавляет его в StringBuilder, если он не равен символу, который нужно удалить. Наконец, метод возвращает измененную строку, вызывая метод toString() на StringBuilder.
Пример использования метода:
String originalStr = "Hello World";
char ch = 'o';
String newStr = removeChar(originalStr, ch);
System.out.println(newStr); // "Hell Wrld"
к оглавлению
6. Потоки ввода/вывода (перейти в раздел)
934. В чём заключается разница между IO и NIO?
В Java IO (input-output) операции чтения/записи происходят блокирующим образом. Это означает, что приложение будет заблокировано до тех пор, пока чтение/запись не завершатся. Это может привести к задержкам в выполнении приложения.
В Java NIO (new/non-blocking io) операции чтения/записи происходят неблокирующим образом . Это означает, что приложение не будет заблокировано во время чтения/записи. Вместо этого, приложение может продолжать работу в то время, пока чтение/запись не завершатся. Это может улучшить производительность приложения.
Кроме того, в Java NIO используются буферы для чтения/записи данных. Это может ускорить операции ввода-вывода, особенно при операциях с файлами.
В целом, Java NIO предоставляет более эффективное и мощное средство для управления операциями ввода-вывода в Java.
935. Какие особенности NIO вы знаете?
Java NIO (новый ввод-вывод) — это набор API-интерфейсов Java для выполнения операций ввода-вывода с упором на неблокирующий ввод-вывод. Вот некоторые из его особенностей:
Каналы и буферы. NIO API предоставляет интерфейс канала, который является средой для выполнения операций ввода-вывода.Буферыхранят данные, которые передаются по каналу. Неблокирующий ввод/вывод – каналы в NIO могут работать в неблокирующем режиме. Это позволяет программе выполнять другие задачи во время передачи данных.Селекторы— объект Selector позволяет одному потоку отслеживать несколько каналов на предмет готовности к вводу. Это особенно полезно при управлении большим количеством подключений.Порядок байтов. В отличие от традиционного ввода-вывода, в котором используется сетевой порядок байтов (обратный порядок байтов), NIO позволяет программисту указать порядок байтов, который будет использоваться для передачи данных по сети.Файловый ввод-вывод с отображением памяти— NIO предоставляет способ отображения файла в память, позволяя программе выполнять операции ввода-вывода непосредственно на файл с отображением памяти.
В целом, NIO обеспечивает более гибкий и масштабируемый способ выполнения операций ввода-вывода в Java, особенно для сетевых приложений.
936. Что такое «каналы»?
В Java "каналы" (англ. channels) являются частью пакета java.nio, который предоставляет альтернативный набор классов для более эффективной работы с вводом-выводом (I/O) данных, чем стандартные библиотеки Java.
Классы каналов позволяют выполнять как синхронное, так и асинхронное чтение и запись данных внутри NIO фреймворка. В отличие от стандартных библиотек Java, NIO каналы работают напрямую с буферами данных, что позволяет избежать копирования или перемещения данных, уменьшая задержку и увеличивая производительность.
Некоторые из основных классов каналов в Java включают:
-
FileChannel- используется для чтения и записи данных в файлы. -
SocketChannel- используется для чтения и записи данных через сетевые соединения TCP. -
DatagramChannel- используется для чтения и записи данных через сетевые соединения UDP. -
ServerSocketChannel- используется для создания серверов, которые слушают и принимают входящие соединения через сетевые соединения TCP.
Использование каналов в Java может быть сложным, но оно позволяет увеличить скорость ввода-вывода данных в приложении.
Для создания объекта канала в Java NIO, нужно использовать вызовы методов open() в соответствующем классе, например, FileChannel.open() для работы с файлами, DatagramChannel.open() для работы с объектами Datagram и т.д.
Пример создания канала для чтения данных из файла:
Path path = Paths.get("file.txt");
FileChannel fileChannel = FileChannel.open(path);
ByteBuffer buffer = ByteBuffer.allocate(1024);
fileChannel.read(buffer);
Для записи данных в канал используется метод write() в соответствующем классе канала.
Пример записи данных в файловый канал:
Path path = Paths.get("file.txt");
FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.WRITE);
ByteBuffer buffer = ByteBuffer.wrap("Hello, World!".getBytes());
fileChannel.write(buffer);
Также каналы могут использоваться для работы с сетевыми соединениями, например, через SocketChannel, ServerSocketChannel и DatagramChannel.
937. Назовите основные классы потоков ввода/вывода.
Основные классы потоков ввода/вывода в Java это InputStream, OutputStream, Reader и Writer. InputStream и OutputStream предназначены для чтения и записи байтов, а Reader и Writer - для чтения и записи символов. Каждый из этих классов имеет ряд наследников и различных реализаций, которые могут использоваться для работы с различными типами потоков данных, такими как файлы, сетевые соединения, массивы байтов и т.д.
938. В каких пакетах расположены классы потоков ввода/вывода?
В Java классы, связанные с потоками ввода/вывода, расположены в пакетах java.io и java.nio. Классы потоков ввода/вывода в Java расположены в пакете java.io. Этот пакет содержит классы, необходимые для ввода и вывода данных из потоков в различных форматах. Классы потоков ввода/вывода могут быть использованы для работы с файловой системой или с сетью, а также для работы с другими типами данных, например, массивами байтов и символьными данными.
Кроме того, начиная с Java 7, появился новый пакет java.nio.file, который содержит улучшенную поддержку работы с файловой системой и новые классы и интерфейсы для чтения и записи данных в файлы и другие источники. Классы из этого пакета используются вместе с классами из пакета java.io для выполнения работы с файлами и ввода-вывода в Java.
Некоторые классы из пакета java.io:
- InputStream
- OutputStream
- Reader
- Writer
- File
- FileInputStream
- FileOutputStream
- FileReader
- FileWriter
939. Какие подклассы класса InputStream вы знаете, для чего они предназначены?
В Java есть множество подклассов класса InputStream.
Некоторые из наиболее распространенных подклассов InputStream включают:
- InputStream - абстрактный класс, описывающий поток ввода;
- BufferedInputStream - буферизованный входной поток;
- ByteArrayInputStream позволяет использовать буфер в памяти (массив байтов) в качестве источника данных для входного потока;
- DataInputStream - входной поток для байтовых данных, включающий методы для чтения стандартных типов данных Java;
- FileInputStream - входной поток для чтения информации из файла;
- FilterInputStream - абстрактный класс, предоставляющий интерфейс для классов-надстроек, которые добавляют к существующим потокам полезные свойства;
- ObjectInputStream - входной поток для объектов;
- StringBufferInputStream превращает строку (String) во входной поток данных InputStream;
- PipedInputStream реализует понятие входного канала;
- PushbackInputStream - разновидность буферизации, обеспечивающая чтение байта с последующим его возвратом в поток, позволяет «заглянуть» во входной поток и увидеть, что оттуда поступит в следующий момент, не извлекая информации.
- SequenceInputStream используется для слияния двух или более потоков InputStream в единый.
Каждый из этих подклассов предназначен для чтения данных из определенных источников и имеет свои собственные методы и функциональность для работы с этими данными.
940. Для чего используется PushbackInputStream?
PushbackInputStream — это класс в Java IO API, который позволяет вам «отменить чтение» одного или нескольких байтов из входного потока. Это может быть полезно в ситуациях, когда вы прочитали больше данных, чем вам действительно нужно, и хотите «вернуть» лишние данные в поток, чтобы их можно было прочитать снова позже. Например, предположим, что вы читаете последовательность символов из потока и хотите оценить, соответствуют ли символы определенному шаблону. Если шаблон не совпадает, вы можете «не прочитать» символы и повторить попытку с другим шаблоном. Для этого вы можете использовать PushbackInputStream. Вот пример использования PushbackInputStream:
PushbackInputStream in = new PushbackInputStream(inputStream);
int b = in.read();
if (b != 'X') {
in.unread(b);
}
В этом примере мы создаем PushbackInputStream из существующего InputStream. Затем мы читаем один байт из потока, используя метод read(). Если байт не равен X, мы «не читаем» байт с помощью метода unread(). Это помещает байт обратно в поток, чтобы его можно было прочитать снова позже. Это всего лишь простой пример, но класс PushbackInputStream можно использовать во множестве более сложных сценариев, где вам нужно манипулировать содержимым входного потока.
941. Для чего используется SequenceInputStream?
SequenceInputStream в Java — это класс, который используется для объединения двух или более входных потоков в один входной поток. Он читает из первого входного потока до тех пор, пока не будет достигнут конец файла, а затем читает из второго входного потока и так далее, пока не будет достигнут конец последнего входного потока. Это может быть полезно в ситуациях, когда вам нужно считывать данные из нескольких источников, как если бы они были одним источником.
Например, у вас может быть программа, которой нужно считывать данные из нескольких файлов, но вы хотите обрабатывать их как один файл.
В этом случае вы можете создать объект SequenceInputStream, передавая входные потоки для каждого файла, а затем читать из SequenceInputStream, как если бы это был один файл. Вот пример того, как вы можете использовать SequenceInputStream для чтения из двух входных файлов:
InputStream input1 = new FileInputStream("file1.txt");
InputStream input2 = new FileInputStream("file2.txt");
SequenceInputStream sequence = new SequenceInputStream(input1, input2);
// Чтение из SequenceInputStream, как если бы это был один входной поток
int data = sequence.read();
while (data != -1) {
// сделать что-то с данными
data = sequence.read();
}
// Не забудьте закрыть потоки, когда закончите с ними
sequence.close();
input1.close();
input2.close();
942. Какой класс позволяет читать данные из входного байтового потока в формате примитивных типов данных?
Класс DataInputStream позволяет читать данные из входного байтового потока в формате примитивных типов данных, включая типы данных boolean, byte, char, short, int, long, float, и double.
Пример использования DataInputStream для чтения целочисленного значения из байтового потока:
import java.io.*;
public class ReadDemo {
public static void main(String[] args) {
byte[] buffer = { 0x12, 0x34, 0x56, 0x78 };
ByteArrayInputStream input = new ByteArrayInputStream(buffer);
DataInputStream dataInput = new DataInputStream(input);
try {
int value = dataInput.readInt();
System.out.println(value);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Этот код будет выводить число 305419896, которое является результатом чтения четырех байтов из байтового потока в формате int.
Пример использования:
InputStream inputStream = new FileInputStream("data.bin");
DataInputStream dataInputStream = new DataInputStream(inputStream);
int intValue = dataInputStream.readInt();
float floatValue = dataInputStream.readFloat();
String stringValue = dataInputStream.readUTF();
dataInputStream.close();
В этом примере мы читаем из файла data.bin целое число, число с плавающей точкой и строку в формате UTF-8.
943. Какие подклассы класса OutputStream вы знаете, для чего они предназначены?
Класс OutputStream в Java представляет абстрактный класс для всех выходных потоков байтов. Подклассы класса OutputStream определяют конкретные типы потоков вывода, которые могут использоваться для записи данных в различные цели, например, файлы или сетевые соединения.
Некоторые из наиболее распространенных подклассов класса OutputStream в Java включают в себя:
FileOutputStream- позволяет записывать данные в файлы.ByteArrayOutputStream- позволяет записывать данные в память в виде массива байтов.FilterOutputStream- представляет класс-оболочку, который добавляет определенную функциональность к уже существующему потоку вывода.ObjectOutputStream- используется для записи объектов Java в поток вывода.DataOutputStream- позволяет записывать примитивные типы данных Java (byte, short, int, long, float, double, boolean, char) в поток вывода.
Каждый из этих подклассов класса OutputStream предназначен для определенной цели и может использоваться в различных ситуациях в зависимости от требований приложения.
944. Какие подклассы класса Reader вы знаете, для чего они предназначены?
Класс java.io.Reader - это абстрактный класс для чтения символьных данных из потока. Его подклассы предназначены для чтения из различных источников, включая файлы, буферы, символьные массивы и т.д.
Некоторые из подклассов Reader в Java включают:
BufferedReader: для более эффективного чтения данных из потока, чем чтение по одному символу за раз.InputStreamReader: читает символы из InputStream и выполняет преобразование байтов в символы используя определенную кодировку.FileReader: для чтения символов из файла в кодировке по умолчанию.CharArrayReader: для чтения символов из входного символьного массива.StringReader: для чтения символов из входной строки.
Эти подклассы часто используются в различных приложениях Java для чтения символьных данных из различных источников.
945. Какие подклассы класса Writer вы знаете, для чего они предназначены?
Класс Writer и его подклассы предоставляют удобный способ записи символьных данных в потоки. Некоторые из подклассов Writer:
BufferedWriter: буферизует символьный вывод для повышения производительности.OutputStreamWriter: конвертирует вывод OutputStream в символы.PrintWriter: предоставляет удобные методы печати форматированного текста.StringWriter: записывает символы в строку, которую можно затем использовать для получения символьных данных в виде строки.
Пример использования BufferedReader для записи символьных данных в файл:
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output.txt"))) {
writer.write("Hello, world!");
} catch (IOException ex) {
System.err.println("Failed to write to file: " + ex.getMessage());
}
В этом примере создается экземпляр BufferedWriter, который оборачивает FileWriter и буферизует символьный вывод, и затем вызывает его метод write, чтобы записать строку "Hello, world!". Если происходит ошибка записи, программа выводит сообщение об ошибке в стандартный поток ошибок.
946. В чем отличие класса PrintWriter от PrintStream?
Класс PrintWriter и PrintStream - это классы ввода/вывода в Java, которые позволяют записывать текстовые данные в поток вывода (например, файл, консоль или сеть) с помощью методов, которые обрабатывают разные типы данных.
Главное отличие между PrintWriter и PrintStream заключается в том, как они обрабатывают исключения. В качестве части их обязательств по обработке исключений, PrintStream предоставляет методы checkError(), а PrintWriter возвращает исключение с помощью метода getError().
Кроме того, PrintStream использует кодировку, которая зависит от настроек операционной системы, в то время как PrintWriter всегда использует кодировку по умолчанию. Наконец, PrintWriter более эффективен, чем PrintStream на запись в файлы, так как использует меньше буферов памяти.
Если вам нужно выводить текстовые данные в поток вывода, то в большинстве случаев вы можете использовать любой из этих классов. Однако, если вам нужно более эффективный способ записи данных в файл, рекомендуется использовать PrintWriter.
947. Чем отличаются и что общего у InputStream, OutputStream, Reader, Writer?
InputStream, OutputStream, Reader, и Writer в Java являются частью пакетов Java io и Java nio, которые позволяют выполнять чтение и запись данных из/в файла или другого потока.
InputStream и OutputStream используются для чтения и записи двоичных данных (байтов) из/в поток. Reader и Writer используются для чтения и записи символьных данных (текста) из/в поток.
Все эти классы имеют общий предок, а именно класс java.io.InputStream. InputStream и Reader - это классы, которые являются частью java.io пакета, тогда как OutputStream и Writer - это часть пакета java.io, как один из вариантов NIO (новый ввод-вывод), доступный в Java 4 и более поздних версиях.
Если нужно читать и записывать текстовые данные, то рекомендуется использовать классы Reader и Writer. Если нужно работать с бинарными данными, то используйте InputStream и OutputStream.
Некоторые классы, такие как BufferedInputStream, BufferedOutputStream, BufferedReader, BufferedWriter и др., дополнительно добавляют функциональность, такую как буферизация, что упрощает работу с данными.
948. Какие классы позволяют преобразовать байтовые потоки в символьные и обратно?
В Java для преобразования байтовых потоков в символьные и обратно используются классы InputStreamReader и OutputStreamWriter.
Класс InputStreamReader позволяет считывать байты из InputStream и преобразовывать их в символы в соответствии с выбранной кодировкой.
Класс OutputStreamWriter позволяет записывать символы в OutputStream и преобразовывать их в байты в соответствии с выбранной кодировкой.
Примеры использования:
Чтение из InputStream и перевод в строку:
InputStream input = new FileInputStream("file.txt");
Reader reader = new InputStreamReader(input, "UTF-8");
StringBuilder result = new StringBuilder();
int ch;
while ((ch = reader.read()) != -1) {
result.append((char) ch);
}
reader.close();
input.close();
String str = result.toString();
Запись строки в OutputStream:
OutputStream output = new FileOutputStream("file.txt");
Writer writer = new OutputStreamWriter(output, "UTF-8");
String str = "Привет, мир!";
writer.write(str);
writer.close();
output.close();
Обратите внимание, что в приведенных примерах используется кодировка UTF-8. Вы можете выбрать любую другую поддерживаемую кодировку в зависимости от ваших потребностей.
949. Какие классы позволяют ускорить чтение/запись за счет использования буфера?
В Java для ускорения чтения и записи данных рекомендуется использовать буферизованные классы из пакета java.io. Вот некоторые классы, которые могут помочь в этом:
BufferedInputStream- буферизованный входной поток данных, который считывает данные из исходного потока в буфер и возвращает данные из буфера при каждом вызове метода read().BufferedOutputStream- буферизованный выходной поток данных, который записывает данные в буфер и отправляет данные из буфера в целевой поток при каждом вызове метода flush().BufferedReader- буферизованный символьный входной поток, который читает данные из исходного потока и возвращает данные из буфера при каждом вызове метода read().BufferedWriter- буферизованный символьный выходной поток, который записывает данные в буфер и отправляет данные из буфера в целевой поток при каждом вызове метода flush().
Все эти классы предоставляют более эффективный способ чтения и записи данных благодаря использованию буфера. При использовании этих классов количество обращений к исходному потоку/целевому потоку уменьшается, что может ускорить процесс.
950. Какой класс предназначен для работы с элементами файловой системы?
Для работы с элементами файловой системы в Java используется класс java.nio.file.Files из пакета nio. Примеры методов:
Files.exists(Path path)- проверяет существование файла или директории по указанному путиFiles.isDirectory(Path path)- проверяет, является ли файл, указанный по пути, директориейFiles.isRegularFile(Path path)- проверяет, является ли файл, указанный по пути, обычным (не директорией или специальным)Files.createDirectory(Path dir)- создает директорию по указанному пути- `Files.createFile(Path file) - создает обычный файл по указанному пути
Например:
import java.nio.file.*;
public class Example {
public static void main(String[] args) {
Path path = Paths.get("/path/to/file.txt");
if (Files.exists(path)) {
System.out.println("File exists.");
} else {
System.out.println("File does not exist.");
}
}
}
951.Какие методы класса File вы знаете?
Некоторые методы класса File в Java:
exists()- возвращает true, если файл или каталог существует.getName()- возвращает имя файла или каталога.isDirectory()- возвращает true, если это каталог.isFile()- возвращает true, если это файл.list()- возвращает список всех файлов и каталогов в данном каталоге.mkdir()- создает каталог с заданным именем.delete()- удаляет файл или пустой каталог.getPath()- возвращает путь к файлу или каталогу в виде строки.renameTo()- переименовывает файл или каталог.lastModified()- возвращает время последней модификации файла.length()- возвращает размер файла в байтах.getAbsolutePath()- возвращает абсолютный путь к файлу или каталогу.
Пример использования:
import java.io.File;
public class FileExample {
public static void main(String[] args) {
File file = new File("example.txt");
if (file.exists()) {
System.out.println("File exists");
System.out.println("File size: " + file.length() + " bytes");
} else {
System.out.println("File not found.");
}
}
}
Эта программа проверяет, существует ли файл example.txt и выводит его размер в байтах, если он существует.
952. Что вы знаете об интерфейсе FileFilter?
Интерфейс FileFilter в Java используется для фильтрации файлов в директории при использовании методов list() и listFiles() класса File. Он содержит единственный метод accept(), который принимает объект File и возвращает логическое значение, указывающее, должен ли объект File быть включен в результат фильтрации.
Вот пример использования интерфейса FileFilter:
import java.io.File;
import java.io.FileFilter;
public class MyFileFilter implements FileFilter {
@Override
public boolean accept(File file) {
// Реализация вашего фильтра
return file.getName().endsWith(".txt"); // Возвращает true, если файл имеет расширение .txt
}
}
public class Main {
public static void main(String[] args) {
File dir = new File("/path/to/directory");
File[] files = dir.listFiles(new MyFileFilter());
for (File file : files) {
System.out.println(file.getName());
}
}
}
Это позволяет вывести имена всех файлов в директории, которые имеют расширение .txt. Отфильтрованный массив files передается в качестве аргумента в метод listFiles().
953. Как выбрать все элементы определенного каталога по критерию (например, с определенным расширением)?
Для выбора всех элементов определенного каталога по критерию в Java можно использовать метод listFiles() класса java.io.File, который возвращает массив объектов File, представляющих файлы и каталоги в указанном каталоге. Затем можно перебирать этот массив и выбрать только те файлы, которые совпадают с нужным критерием, например, расширением. Вот пример кода, который выбирает все файлы в каталоге, удовлетворяющие критерию расширения ".txt":
import java.io.File;
public class FileFilterExample {
public static void main(String[] args) {
File dirPath = new File("/path/to/directory");
File[] files = dirPath.listFiles((dir, name) -> name.toLowerCase().endsWith(".txt"));
// process the selected files
for (File file : files) {
// do something with the file
}
}
}
В этом примере используется лямбда-выражение для фильтрации файлов по расширению. Вы можете настроить это выражение в соответствии с вашими нуждами.
954. Какие режимы доступа к файлу есть у RandomAccessFile?
У класса RandomAccessFile в Java есть несколько режимов доступа к файлу:
"r" (read-only)- только для чтения. Если файл не существует, выбрасывается исключение FileNotFoundException."rw" (read-write)- для чтения и записи. Если файл не существует, он создается."rws" (read-write-sync)- для чтения и записи, с синхронной записью изменений на диск. Если файл не существует, он создается."rwd" (read-write-data-sync)- для чтения и записи, с синхронной записью изменений данных на диск. Если файл не существует, он создается.
Например, для открытия файла в режиме "read-write" можно использовать следующий код:
RandomAccessFile file = new RandomAccessFile("file.txt", "rw");
Обратите внимание, что при открытии файла в режиме "rws" или "rwd" операции записи могут производиться медленнее из-за синхронизации со стороны системы ввода-вывода.
955. Какие классы поддерживают чтение и запись потоков в компрессированном формате?
На языке Java, чтение и запись в компрессированном формате поддерживается классами DeflaterOutputStream и InflaterInputStream, которые находятся в пакете java.util.zip.
DeflaterOutputStream - это класс для записи байтов в поток, при этом данные сжимаются при помощи алгоритма сжатия Deflate. Пример использования:
OutputStream outputStream = new DeflaterOutputStream(new FileOutputStream("compressed.gz"));
outputStream.write("Hello World".getBytes());
outputStream.close();
InflaterInputStream - это класс для чтения байтов из потока и автоматического разжатия с использованием алгоритма сжатия Deflate. Пример использования:
InputStream inputStream = new InflaterInputStream(new FileInputStream("compressed.gz"));
byte[] buffer = new byte[1024];
int length;
while ((length = inputStream.read(buffer)) > 0) {
System.out.print(new String(buffer, 0, length));
}
inputStream.close();
Обратите внимание, что в приведенных примерах в качестве сжатия используется алгоритм Deflate, но также существуют другие алгоритмы, такие как GZIP, которые также могут быть использованы для сжатия потоков данных.
956. Существует ли возможность перенаправить потоки стандартного ввода/вывода?
Да, в Java можно перенаправить потоки стандартного ввода/вывода. Для этого можно использовать классы System.in, System.out и System.err. Например, чтобы перенаправить стандартный поток ввода на файл, можно использовать класс FileInputStream:
System.setIn(new FileInputStream("input.txt"));
После этого все вызовы System.in.read() будут читать данные из файла "input.txt" вместо стандартного потока ввода.
Аналогично, чтобы перенаправить стандартный поток вывода в файл, можно использовать класс FileOutputStream:
System.setOut(new FileOutputStream("output.txt"));
После этого все вызовы System.out.println() будут записывать данные в файл "output.txt" вместо стандартного потока вывода.
При необходимости можно также перенаправить стандартный поток ошибок, используя метод System.setErr().
957. Какой символ является разделителем при указании пути в файловой системе?
В Java разделителем пути в файловой системе является символ / (slash).
Например, чтобы указать путь к файлу example.txt в папке mydir на диске C, можно использовать следующую строку:
String filePath = "C:/mydir/example.txt";
Однако на операционных системах Windows можно использовать и символ \ (backslash) в качестве разделителя пути. В этом случае нужно экранировать символ обратной косой черты, чтобы он был интерпретирован как символ-разделитель. Например:
String filePath = "C:\\mydir\\example.txt";
В любом случае, лучше всего использовать File.separator для обеспечения переносимости кода между разными операционными системами. Это позволяет автоматически определить корректный символ-разделитель пути в зависимости от операционной системы, на которой выполняется код. Например:
String filePath = "C:" + File.separator + "mydir" + File.separator + "example.txt";
958. Что такое «абсолютный путь» и «относительный путь»?
"Абсолютный путь" - это путь к файлу или директории, который начинается с корневого каталога файловой системы, идентифицирующий конкретный файл или директорию на компьютере без ссылки на текущую директорию. Например, в операционной системе Windows абсолютный путь может иметь вид "C:\Users\John\Documents\file.txt".
"Относительный путь" - это путь, который начинается с текущей директории и указывает на файл или директорию относительно нее. То есть, это путь относительно текущего каталога (или другой точки отсчета). Например, если текущая директория в Windows - "C:\Users\John", а нужный файл находится в подкаталоге "Documents", то относительный путь будет выглядеть как "Documents\file.txt".
В языке Java, класс File имеет методы, которые могут возвращать абсолютный и относительный пути, такие как getAbsolutePath() и getPath(). Чтобы получить абсолютный путь, можно использовать метод getAbsolutePath(), а для получения относительного - getPath(). Например:
File file = new File("Documents/file.txt");
String absolutePath = file.getAbsolutePath(); // абсолютный путь
String relativePath = file.getPath(); // относительный путь
959. Что такое «символьная ссылка»?
"Символьная ссылка" ("symbolic link") в Java - это ссылка, которая указывает на другой файл или каталог в файловой системе. В отличие от "жестких ссылок" ("hard links"), символьные ссылки могут указывать на файлы или каталоги на других разделах диска и даже на других машинах в сети. Символьные ссылки создаются с помощью метода java.nio.file.Files.createSymbolicLink() или с помощью команды ln -s в командной строке. Они широко используются в операционных системах Unix и Linux, но также поддерживаются в Windows, начиная с версии Windows Vista. Использование символьных ссылок в Java может быть полезно, например, для организации структуры файловой системы или для обработки файлов по определенной системе с помощью относительных путей. Обратите внимание, что символьные ссылки не поддерживаются в файловых системах FAT32 и NTFS до Windows Vista, а также не работают на macOS при использовании Time Machine.
960. Какие существуют виды потоков ввода/вывода?
В Java существуют два вида потоков ввода/вывода - байтовые потоки и символьные потоки.
Байтовые потоки ввода/вывода предназначены для операций ввода/вывода байтовых данных, таких как изображения, аудио и видеофайлы. Конкретные классы, связанные с байтовыми потоками ввода/вывода, включают FileInputStream и FileOutputStream.
Символьные потоки ввода/вывода, с другой стороны, предназначены для операций ввода и вывода символьных данных, таких как текстовые файлы. Они конвертируют символы в байты для сетевых операций или записи в файлы, и наоборот. Конкретные классы, связанные с символьными потоками ввода/вывода, включают FileReader и FileWriter.
InputStream- поток ввода байтов из источника данных.OutputStream- поток вывода байтов в приемник данных.Reader- поток символьного ввода данных.Writer- поток символьного вывода данных.
Зачастую, символьные потоки ввода/вывода используются в паре с классами BufferedReader и BufferedWriter для более эффективного чтения и записи данных.
961. Назовите основные предки потоков ввода/вывода.
Основными предками потоков ввода-вывода в Java являются классы InputStream, OutputStream, Reader и Writer. Классы InputStream и Reader предоставляют методы для чтения данных из потока, а классы OutputStream и Writer предоставляют методы для записи данных в поток. Классы InputStream и OutputStream работают с байтами, а классы Reader и Writer работают с символами. Эти классы и их наследники используются для работы с различными типами потоков, такими как файловые потоки, сокеты, буферизованные потоки на основе других потоков и т.д.
962. Что общего и чем отличаются следующие потоки: InputStream, OutputStream, Reader, Writer?
В Java, классы InputStream, OutputStream, Reader и Writer являются основными классами для работы с потоками данных.
-
InputStream- это абстрактный класс, представляющий входной поток байтов. Классы, наследующие InputStream, позволяют читать данные из различных источников, таких как файлы или сетевые соединения. -
OutputStream- это абстрактный класс, представляющий выходной поток байтов. Классы, наследующие OutputStream, позволяют записывать данные в различные места назначения, такие как файлы или сетевые соединения. -
Reader- это абстрактный класс, представляющий входной поток символов. Классы, наследующие Reader, позволяют читать текстовые данные из различных источников, таких как файлы или сетевые соединения. -
Writer- это абстрактный класс, представляющий выходной поток символов. Классы, наследующие Writer, позволяют записывать текстовые данные в различные места назначения, такие как файлы или сетевые соединения.
В общем, все эти классы предоставляют абстракцию для чтения и записи данных в Java. Они предоставляют различные методы для чтения и записи данных, а также методы для управления потоком данных, такие как закрытие потока.
Главное отличие между InputStream/OutputStream и Reader/Writer заключается в том, что первые являются потоками байтов, а вторые - потоками символов, то есть они работают с разными типами данных. Однако, Reader и Writer работают только с кодировками Unicode, тогда как InputStream и OutputStream работают с байтами
963. Что вы знаете о RandomAccessFile?
RandomAccessFile — это класс в пакете java.io, который позволяет вам читать и записывать данные в файл в режиме произвольного доступа. Это означает, что вы можете читать или писать в любую точку файла, а не ограничиваться чтением или записью последовательно с начала или конца файла.
Вы можете использовать класс RandomAccessFile для выполнения низкоуровневых операций ввода-вывода в файле, таких как чтение и запись байтов или символов, установка указателя файла в определенную позицию и получение текущей позиции указателя файла. Класс RandomAccessFile поддерживает как чтение, так и запись в файл.
Вот пример создания объекта RandomAccessFile и чтения из него:
import java.io.*;
public class RandomAccessFileExample {
public static void main(String[] args) {
try {
RandomAccessFile file = new RandomAccessFile("filename.txt", "r");
file.seek(10); // set the file pointer to position 10
byte[] buffer = new byte[1024];
int bytesRead = file.read(buffer, 0, buffer.length);
System.out.println(new String(buffer, 0, bytesRead));
file.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
В этом примере мы создаем объект RandomAccessFile с именем файла «filename.txt» и режимом «r» (только для чтения). Затем мы устанавливаем указатель файла в позицию 10 с помощью метода seek() и считываем до 1024 байтов из файла в буфер с помощью метода read(). Наконец, мы выводим содержимое буфера на консоль.
RandomAccessFile может быть полезным классом для определенных файловых операций ввода-вывода, когда вам нужно читать или записывать в определенные места в файле.
964. Какие есть режимы доступа к файлу?
В Java для работы с файлами можно использовать класс File и класс RandomAccessFile. Класс RandomAccessFile имеет следующие режимы доступа к файлу:
- "r" - открытие файла только для чтения;
- "rw" - открытие файла для чтения и записи;
- "rws" - открытие файла для чтения и записи, при этом каждое изменение записывается на диск синхронно;
- "rwd" - открытие файла для чтения и записи, при этом каждое изменение записывается на диск в более общем случае.
Здесь "r" означает чтение (read), "w" - запись (write), "s" - синхронизация (synchronize), "d" - запись на диск (disk).
Для работы с файлами класс File использует следующие флаги:
- "r" - открытие файла только для чтения;
- "w" - перезапись файла, если он существует;
- "a" - добавление данных в конец файла, если он существует
- "x" - создание нового файла и открытие его для записи
- "rw" - открытие файла для чтения и записи.
Например, для открытия файла только для чтения можно использовать такой код:
File file = new File("filename.txt");
RandomAccessFile raf = new RandomAccessFile(file, "r");
Для открытия файла для записи используйте режим "rw".
965. В каких пакетах лежат классы-потоки?
В Java классы-потоки находятся в пакете java.io. Некоторые из наиболее часто используемых классов потоков включают InputStream, OutputStream, Reader and Writer. Они используются для ввода и вывода данных из файлов, сетевых соединений и других источников/целей. Кроме того, в пакете java.util.concurrent содержатся классы, которые используют потоки для работы с многопоточностью.
966. Что вы знаете о классах-надстройках?
Классы-надстройки (wrapper classes) в Java представляют обёртки для примитивных типов данных, чтобы их можно было использовать в качестве объектов. Они необходимы, когда нужно передать примитивный тип данных в некоторый метод, который ожидает объект.
Например:
- Integer - для целочисленных значений типа int
- Double - для чисел с плавающей точкой типа double
- Boolean - для значений true и false типа boolean
- Character - для символов типа char
- Byte - для байтов типа byte
Классы-надстройки имеют множество полезных методов, позволяющих работать с примитивными значениями как с объектами. Например, Double имеет методы для округления чисел, конвертации в другие типы данных, сравнения, и т.д.
Значения классов-надстроек могут быть изменены, например:
Integer i = 5;
i++; // i теперь равно 6
Обратите внимание, что создание объектов классов-надстроек может иметь небольшой накладной расход по памяти и производительности. Используйте их только тогда, когда это действительно требуется, например, при работе с коллекциями объектов.
967. Какой класс-надстройка позволяет читать данные из входного байтового потока в формате примитивных типов данных?
Класс-надстройка DataInputStream позволяет читать данные из входного байтового потока в формате примитивных типов данных. Этот класс обеспечивает методы для чтения 8-, 16- и 32-битных значений типов byte, short, int, float и double из потока. Он также обеспечивает методы для чтения символов и строк из потока. Все методы DataInputStream являются синхронизированными для поддержания правильной последовательности чтения данных из потока. Главный недостаток этого класса заключается в том, что он не прочитает данные напрямую из файловой системы, но будет использовать переданный ему InputStream.
Объект DataInputStream может быть использован для чтения примитивных типов данных, таких как boolean, byte, char, short, int, long, float и double. Кроме того, его можно использовать для чтения строк, массивов байтов и других объектов, записанных в поток методами класса DataOutputStream. Например:
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream("data.dat");
DataInputStream dis = new DataInputStream(fis);
int i = dis.readInt();
float f = dis.readFloat();
double d = dis.readDouble();
System.out.println("i = " + i);
System.out.println("f = " + f);
System.out.println("d = " + d);
}
}
968. Какой класс-надстройка позволяет ускорить чтение/запись за счет использования буфера?
Класс BufferedInputStream и BufferedOutputStream являются надстройками над InputStream и OutputStream. Они добавляют внутренний буфер, который может ускорить процесс чтения/записи данных. Буферизация обычно полезна, если вы читаете или записываете данные блоками, а не по одному байту.
Вот пример использования BufferedInputStream в Java для чтения файла с диска:
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("file.txt"))) {
byte[] buffer = new byte[1024];
int bytesRead = 0;
while ((bytesRead = bis.read(buffer)) != -1) {
// обработка bytesRead байтов данных из буфера
}
} catch (IOException ex) {
// обработка исключения
}
В этом примере BufferedInputStream читает данные из файла file.txt с диска, используя буфер размером 1024 байта. Когда буфер заполнен, данные копируются в массив buffer и обрабатываются в блоке while.
Для записи данных в файл нужно использовать BufferedOutputStream. Вот пример:
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("output.txt"))) {
byte[] data = "Hello, World!".getBytes();
bos.write(data);
} catch (IOException ex) {
// обработка исключения
}
Этот пример записывает строку "Hello, World!" в файл output.txt используяBufferedOutputStream.
969. Какие классы позволяют преобразовать байтовые потоки в символьные и обратно?
В Java для преобразования байтовых потоков в символьные и обратно, можно использовать классы InputStreamReader и OutputStreamWriter, которые предоставляют мосты между символьными и байтовыми потоками.
InputStreamReader позволяет читать символы из байтового потока, используя определенную кодировку. Пример использования:
InputStream inputStream = new FileInputStream("file.txt");
InputStreamReader reader = new InputStreamReader(inputStream, "UTF-8");
В этом примере мы создаем InputStream для файла "file.txt" и передаем его как аргумент в конструктор InputStreamReader вместе с кодировкой UTF-8.
OutputStreamWriter, с другой стороны, используется для записи символов в выходной байтовый поток. Пример использования:
OutputStream outputStream = new FileOutputStream("file.txt");
OutputStreamWriter writer = new OutputStreamWriter(outputStream, "UTF-8");
В этом примере мы создаем OutputStream для файла "file.txt" и передаем его как аргумент в конструктор OutputStreamWriter вместе с кодировкой UTF-8.
Эти классы являются обертками над потоками чтения и записи, и позволяют представлять данные в разных форматах, используя различные кодировки, такие как UTF-8, ISO-8859-1 и другие.
970. Какой класс предназначен для работы с элементами файловой системы (ЭФС)?
В Java класс, предназначенный для работы с элементами файловой системы (эфс), называется java.nio.file.Files. Он предоставляет статические методы для манипуляции с файлами, такие как создание, копирование, перемещение, удаление, а также получение информации о файлах, такой как размер, время доступа и т.д. Например, чтобы получить размер файла, вы можете использовать метод Files.size(Path path), где path - это объект типа Path, представляющий путь к файлу. Пример:
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
Path path = Paths.get("path/to/file.txt");
try {
long size = Files.size(path);
System.out.println("File size: " + size + " bytes");
} catch (IOException e) {
System.err.println("Failed to get file size: " + e.getMessage());
}
}
}
Замените "path/to/file.txt" на путь к файлу, с которым вы хотите работать в вашей файловой системе.
Например, чтобы создать новый файл, можно использовать следующий код:
File file = new File("path/to/file.txt");
try {
boolean success = file.createNewFile();
if (success) {
System.out.println("File created successfully.");
} else {
System.out.println("File already exists.");
}
} catch (IOException e) {
System.out.println("An error occurred: " + e.getMessage());
}
Чтобы переместить или переименовать файл, можно использовать методы renameTo() или moveTo(). Чтение содержимого файла можно выполнить с помощью FileReader, а запись с помощью FileWriter.
971. Какой символ является разделителем при указании пути к ЭФС?
В Java символ, который является разделителем пути к файлам и директориям на ЭФС (файловой системе), зависит от операционной системы. Например, для Windows используется обратный слеш , а для большинства UNIX-подобных систем используется прямой слеш /. Чтобы обеспечить переносимость между разными операционными системами, в Java есть константа File.separator, которая представляет соответствующий разделитель для текущей операционной системы. Вы можете использовать эту константу вместо жестко закодированного разделителя в своих программах Java. Например:
String path = "C:" + File.separator + "mydir" + File.separator + "myfile.txt";
Здесь File.separator будет заменен на правильный символ разделителя в зависимости от операционной системы, на которой запущена программа Java.
972. Как выбрать все ЭФС определенного каталога по критерию (например, с определенным расширением)?
Для выбора всех файлов с определенным расширением из каталога в Java можно воспользоваться методом listFiles() класса java.io.File. Сначала нужно создать объект File для нужного каталога, а затем вызвать на нем метод listFiles() и передать ему фильтр, который будет выбирать только файлы с нужным расширением. Вот пример кода:
import java.io.File;
public class Main {
public static void main(String[] args) {
File directory = new File("/path/to/directory");
File[] files = directory.listFiles((dir, name) -> name.endsWith(".txt"));
for (File file : files) {
System.out.println(file.getName());
}
}
}
В этом примере выбираются все файлы с расширением .txt. Если нужно выбрать файлы с другим расширением, то нужно изменить соответствующую часть условия в лямбда-выражении, передаваемом в качестве второго аргумента методу listFiles().
973. Что вы знаете об интерфейсе FilenameFilter?
Для фильтрации содержимого директории в Java используется интерфейс FilenameFilter. Он содержит один метод boolean accept(File dir, String name), который принимает два аргумента: объект типа File, представляющий родительскую директорию, и строку с именем файла. Метод accept() должен возвращать true, если файл должен быть включен в результаты списка, и false, если файл должен быть исключен.
Например, следующий код демонстрирует, как использовать интерфейс FilenameFilter для вывода только файлов с расширением ".txt" из директории:
import java.io.*;
public class FilterFiles {
public static void main(String[] args) {
// указываем путь к директории
File dir = new File("/path/to/directory");
// создаем экземпляр класса, реализующего интерфейс FilenameFilter
FilenameFilter txtFilter = new FilenameFilter() {
public boolean accept(File dir, String name) {
return name.toLowerCase().endsWith(".txt");
}
};
// получаем список файлов, отфильтрованных по расширению
File[] filesList = dir.listFiles(txtFilter);
// выводим список файлов
for (File file : filesList) {
if (file.isFile()) {
System.out.println(file.getName());
}
}
}
}
Этот код создает объект типа FilenameFilter с помощью анонимного класса и метода accept() для фильтрации файлов с расширением .txt. Затем создается массив File[] с отфильтрованными файлами и выводятся их имена.
974. Что такое сериализация?
Сериализация в Java - это механизм, который позволяет сохранять состояние объекта в виде последовательности байтов. Процесс сериализации используется для передачи объекта по сети или для сохранения его в файл (например, в базу данных).
В Java для реализации сериализации объектов используется интерфейс Serializable. Этот интерфейс не содержит методов, его реализация всего лишь указывает компилятору, что объект может быть сериализован. После того, как объект сериализуется, его можно сохранить в файл или передать по сети в виде последовательности байтов. При необходимости объект можно восстановить из этой последовательности байтов (этот процесс называется десериализацией).
975. Какие классы позволяют архивировать объекты?
Для архивирования объектов в Java можно использовать классы ObjectOutputStream и ObjectInputStream. Эти классы позволяют записывать и считывать объекты из потока данных. После записи объекта в поток, можно использовать классы ZipOutputStream или GZIPOutputStream, чтобы упаковать этот поток в архив с расширением ".zip" или ".gz". Чтобы прочитать архив, необходимо использовать классы ZipInputStream или GZIPInputStream, которые прочитают содержимое архива, а затем можно использовать ObjectInputStream, чтобы прочитать объекты из потока данных.
Пример использования:
// Записываем объект в поток и упаковываем в gzip
MyObject obj = new MyObject();
try (FileOutputStream fos = new FileOutputStream("data.gz");
GZIPOutputStream gzos = new GZIPOutputStream(fos);
ObjectOutputStream out = new ObjectOutputStream(gzos)) {
out.writeObject(obj);
}
// Распаковываем содержимое gzip и считываем объект из потока
try (FileInputStream fis = new FileInputStream("data.gz");
GZIPInputStream gzis = new GZIPInputStream(fis);
ObjectInputStream in = new ObjectInputStream(gzis)) {
MyObject obj = (MyObject) in.readObject();
}
В данном примере создается объект класса MyObject, который записывается в поток данных, упаковывается в gzip-архив, записывается в файл, а затем считывается обратно из файла и извлекается объект класса MyObject.
Обратите внимание, что класс MyObject должен быть сериализуемым, то есть должен реализовывать интерфейс Serializable, чтобы его можно было записать и считать из потока объектов
7. Сериализация (перейти в раздел)
976. Что такое «сериализация»?
Сериализация - это процесс преобразования объекта в последовательность байтов, которую можно сохранить в файле или передать по сети, а затем восстановить объект из этой последовательности байтов. В Java это может быть выполнено с помощью интерфейса Serializable.
Пример сериализации объекта в Java:
import java.io.*;
public class SerializeDemo {
public static void main(String[] args) {
Employee e = new Employee();
e.name = "John Doe";
e.address = "123 Main St";
e.SSN = 123456789;
e.number = 101;
try {
FileOutputStream fileOut =
new FileOutputStream("/tmp/employee.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(e);
out.close();
fileOut.close();
System.out.printf("Serialized data is saved in /tmp/employee.ser");
} catch (IOException i) {
i.printStackTrace();
}
}
}
Здесь объект класса Employee сериализуется в файл /tmp/employee.ser. Этот файл может быть впоследствии использован для восстановления объекта.
Пример десериализации объекта в Java:
import java.io.*;
public class DeserializeDemo {
public static void main(String[] args) {
Employee e = null;
try {
FileInputStream fileIn = new FileInputStream("/tmp/employee.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
e = (Employee) in.readObject();
in.close();
fileIn.close();
} catch (IOException i) {
i.printStackTrace();
return;
} catch (ClassNotFoundException c) {
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
System.out.println("Deserialized Employee...");
System.out.println("Name: " + e.name);
System.out.println("Address: " + e.address);
System.out.println("SSN: " + e.SSN);
System.out.println("Number: " + e.number);
}
}
Здесь файл /tmp/employee.ser содержит сериализованный объект класса Employee, который восстанавливается в переменную e, после чего можно получить доступ.
977. Какие условия “благополучной” сериализации объекта?
Для "благополучной" сериализации Java объекта должны выполняться следующие условия:
- Класс объекта должен быть сериализируемым (то есть должен реализовывать интерфейс Serializable).
- Все поля объекта должны быть сериализируемыми (то есть должны быть помечены ключевым словом transient, если они не могут быть сериализованы).
- Все недоступные поля внешних классов (если объект вложен в другой класс) должны быть помечены ключевым словом transient.
- Если класс содержит ссылки на другие объекты, эти объекты также должны помечаться как Serializable.
- Если в одном потоке создается несколько объектов, которые должны быть сериализованы одинаковым образом, то для каждого объекта должен использоваться тот же ObjectOutputStream.
- Если класс содержит методы writeObject и readObject, то эти методы должны быть реализованы правильным образом.
Если все условия выполнены, то сериализация объекта должна проходить без ошибок.
978. Опишите процесс сериализации/десериализации с использованием Serializable.
В Java сериализация` - это процесс преобразования объекта в поток байтов для его сохранения или передачи другому месту, независимо от платформы. Интерфейс Serializable используется для обозначения класса, который может быть сериализован. Сериализация может быть использована для сохранения состояния объекта между запусками программы, для передачи состояния объекта другому приложению, и т.д.
Процесс сериализации в Java прост и автоматически обрабатывается стандартной библиотекой Java. Вот как это делается:
-
Создайте класс, который вы хотите сериализовать и сделайте его реализующим интерфейс Serializable.
-
Используйте ObjectOutputStream для записи объекта в поток байтов. Например:
MyClass object = new MyClass();
FileOutputStream fileOut = new FileOutputStream("file.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(object);
out.close();
fileOut.close();
- Для десериализации объекта из потока байтов используйте ObjectInputStream. Например:
FileInputStream fileIn = new FileInputStream("file.ser");
ObjectInputStream in = new ObjectInputStream(fileIn);
MyClass object = (MyClass) in.readObject();
in.close();
fileIn.close();
Объекты, которые сериализуются должны реализовать пустой конструктор, так как они должны быть воссозданы при десериализации.
Важно отметить, что сериализация не предназначена для безопасности и не должна использоваться для передачи чувствительных данных, таких как пароли или номера кредитных карт.
979. Как изменить стандартное поведение сериализации/десериализации?
Чтобы изменить стандартное поведение сериализации/десериализации в Java, необходимо реализовать интерфейс Serializable и переопределить методы writeObject и readObject. Эти методы позволяют контролировать процесс сериализации/десериализации и включать/исключать специфические поля объекта.
Если вам нужно более тонкое управление над процессом сериализации/десериализации, например, сохранить объект в формате JSON, вы можете использовать библиотеки сериализации, такие как Jackson или Gson.
Например, вот как можно использовать библиотеку Jackson для сериализации/десериализации объекта в формат JSON:
import com.fasterxml.jackson.databind.ObjectMapper;
// создать объект ObjectMapper
ObjectMapper mapper = new ObjectMapper();
// сериализовать объект в JSON
MyObject obj = new MyObject();
String json = mapper.writeValueAsString(obj);
// десериализовать JSON строку в объект
MyObject deserializedObj = mapper.readValue(json, MyObject.class);
Здесь MyObject - это класс, который вы хотите сериализовать в JSON. Вы также можете настроить свойства ObjectMapper, чтобы управлять процессом сериализации/десериализации более тонко.
980. Как исключить поля из сериализации?
В Java для того, чтобы исключить поля из сериализации, можно использовать ключевое слово transient. Если вы отмечаете поле transient, то при сериализации объекта это поле будет пропущено, а при десериализации ему будет присвоено значение по умолчанию для его типа.
Пример:
import java.io.Serializable;
public class MyClass implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private transient String password;
//...
}
В этом примере поле password отмечено ключевым словом transient, так что оно будет пропущено при сериализации объекта MyClass.
Для других способов исключения полей из сериализации можно использовать аннотации @JsonIgnore и @JsonProperty из библиотеки Jackson или @Expose и @SerializedName из библиотеки Gson. Но вам необходимо их добавить как зависимости в ваш проект.
При использовании Jackson:
import com.fasterxml.jackson.annotation.JsonIgnore;
import com.fasterxml.jackson.databind.ObjectMapper;
public class MyClass {
private String name;
@JsonIgnore
private String password;
//...
}
При использовании Gson:
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import com.google.gson.annotations.Expose;
import com.google.gson.annotations.SerializedName;
public class MyClass {
private String name;
@Expose(serialize = false)
@SerializedName("password")
private String password;
//...
}
Сериализация поля помеченного как transient будет пропущена. Кроме того, можно использовать аннотации @Transient или @JsonIgnore для исключения поля из сериализации.
public class MyClass implements Serializable {
private String field1;
private transient String field2;
@Transient
private String field3;
@JsonIgnore
private String field4;
// getters and setters
}
В данном примере field2 будет исключен из сериализации, а также field3 и field4 с помощью аннотаций. Обратите внимание, что для использования аннотации @JsonIgnore вам нужно добавить зависимость на библиотеку Jackson. Общая идея заключается в том, чтобы пометить поля, которые не должны быть сериализованы, как transient или использовать аннотации, которые сообщат маршаллеру или библиотеке сериализации, какие поля исключить.
981. Что обозначает ключевое слово transient?
Ключевое слово transient в Java используется для указания, что поле класса не должно быть сериализовано при сохранении состояния объекта. Также помеченное как transient поле не будет восстановлено при десериализации объекта и его состояние будет инициализировано значением по умолчанию для данного типа. Например, если поле имеет тип int, то после десериализации оно будет равно 0.
Пример использования:
import java.io.Serializable;
public class Example implements Serializable {
private String name;
private transient int age;
public Example(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
В данном примере поле age помечено как transient и не будет сериализовано при сохранении состояния объекта.
982. Какое влияние оказывают на сериализуемость модификаторы полей static и final.
Модификаторы static и final в Java оказывают влияние на сериализуемость объектов при использовании механизма сериализации.
Поля, отмеченные модификатором transient, не сериализуются. Кроме того, поля, отмеченные модификатором static, не участвуют в процессе сериализации, то есть значения этих полей не будут сохранены в сериализованном объекте, независимо от того, были ли они инициализированы или нет.
Поля, отмеченные модификатором final, являются неизменяемыми и могут быть сериализованы и десериализованы. Если поле final не является static, его значение будет сериализовано и восстановлено при десериализации объекта.
Для того чтобы класс был сериализуемым, он должен реализовать интерфейс Serializable или Externalizable. Кроме того, все поля класса должны быть сериализуемыми, то есть должны быть Serializable или Externalizable, иначе будет возбуждено исключение NotSerializableException.
983. Как не допустить сериализацию?
Для того чтобы не сериализовать определенные поля в Java, их необходимо отметить аннотацией @Transient. Это помечает поле как временное и при сериализации его значение будет игнорироваться. Кроме того, можно определить поля как static или transient, которые также не будут сериализоваться автоматически. Вот пример использования аннотации @Transient:
public class MyClass implements Serializable {
private String myField;
@Transient
private String myTransientField;
// ... other fields, constructors, getters and setters
}
В этом примере поле myTransientField не будет сериализоваться при сохранении экземпляра MyClass.
Обратите внимание, что для того чтобы класс был сериализуемым, он должен реализовать интерфейс Serializable.
984. Как создать собственный протокол сериализации?
Чтобы создать собственный протокол сериализации в Java, вы можете реализовать интерфейс Serializable или Externalizable в своем классе. Интерфейс Serializable обеспечивает реализацию сериализации по умолчанию, а интерфейс Externalizable позволяет настраивать сериализацию и десериализацию. Вот обзор того, как реализовать каждый интерфейс:
-
Сериализуемый: -
- Реализуйте интерфейс Serializable в своем классе.
-
- Отметьте любые поля, которые вы не хотите сериализовать, с помощью ключевого слова transient.
-
- Переопределите методы writeObject() и readObject(), если вы хотите настроить сериализацию или десериализацию.
-
Внешний: -
- Реализуйте интерфейс Externalizable в своем классе.
-
- Предоставьте общедоступный конструктор без аргументов для вашего класса.
-
- Реализуйте методы writeExternal() и readExternal() для настройки сериализации и десериализации.
Для создания собственного протокола сериализации достаточно реализовать интерфейс Externalizable, который содержит два метода:
public void writeExternal(ObjectOutput out) throws IOException;
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException;
985. Какая роль поля serialVersionUID в сериализации?
Поле serialVersionUID в Java играет ключевую роль в сериализации объектов. serialVersionUID- это статическое поле, которое нужно добавлять в классы для их сериализации. Когда объекты сериализуются, они получают свой уникальный serialVersionUID, который используется при десериализации для проверки, что версии классов совпадают и объект можно корректно восстановить. Если serialVersionUID не указан явно, то в качестве идентификатора используется хеш-код класса, что может привести к ошибкам при десериализации, если класс изменился.
Итак, если вы планируете сериализовать объекты в Java, важно явно задавать serialVersionUID для классов, которые вы сериализуете. Это поможет убедиться, что при разных запусках приложения объекты всегда будут десериализовываться корректно и предотвратит возможные ошибки.
986. Когда стоит изменять значение поля serialVersionUID?
987. В чем проблема сериализации Singleton?
Для решения этой проблемы можно использовать один из следующих подходов:
Использовать Enum Singleton, который уже предопределен и обеспечивает единственный экземпляр в любых условиях, в том числе и после десериализации.Объявить в классе Singleton методы readResolve() и writeReplace(), чтобы переопределить процедуры сериализации и десериализации. Это позволит возвращать существующий экземпляр Singleton при десериализации.Организовать Singleton с помощью вложенного класса и статической инициализации. Этот подход обеспечивает ленивую инициализацию и инстанцирование объекта Singleton.
Проблема сериализации Singleton заключается в том, что при десериализации объекта Singleton может быть создан новый экземпляр класса, что противоречит принципам Singleton (то есть гарантированного существования только одного экземпляра класса). Эту проблему можно решить, переопределив методы readResolve() и writeReplace(). Пример:
public class Singleton implements Serializable {
private static final long serialVersionUID = 1L;
private Singleton() {
}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
protected Object readResolve() throws ObjectStreamException {
return getInstance();
}
private Object writeReplace() throws ObjectStreamException {
return getInstance();
}
}
Этот подход гарантирует, что десериализованный объект будет таким же, как и объект, который был сериализован.
988. Какие существуют способы контроля за значениями десериализованного объекта?
При десериализации объекта в Java можно использовать разные способы контроля за значениями. Наиболее распространенными способами являются использование модификатора transient и методов readObject() и readResolve().
-
Модификатор transient: если поле класса помечено модификатором transient, то оно не будет сериализоваться. Это позволяет контролировать, какие поля будут загружены при десериализации объекта. -
Метод readObject(): при десериализации объекта вызывается метод readObject(), который позволяет контролировать значения загруженных полей. Этот метод должен быть определен в классе, который реализует интерфейс Serializable. -
Метод readResolve(): после десериализации объекта вызывается метод readResolve(), который позволяет заменить десериализованный объект на другой объект. Этот метод также должен быть определен в классе, который реализует интерфейс Serializable.
Пример использования метода readObject():
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
if (value < 0) {
throw new InvalidObjectException("Negative value");
}
}
В данном примере при десериализации объекта будет проверяться, что значение поля value не является отрицательным.
Пример использования метода readResolve():
private Object readResolve() throws ObjectStreamException {
if (this == INSTANCE) {
return INSTANCE;
} else {
return new Singleton();
}
}
В данном примере при десериализации объекта будет проверяться, что объект является синглтоном и, если это не так, будет создан новый объект класса Singleton.
к оглавлению
8. Потоки выполнения/многопоточность (перейти в раздел)
989. Дайте определение понятию “процесс”. Дайте определение понятию “поток”.
В Java термин "процесс" обычно относится к отдельной программе, выполняющейся в операционной системе и имеющей свой уникальный идентификатор. Каждый процесс имеет свою собственную область оперативной памяти и запускается независимо от других процессов.
"Поток" (или "Thread") - это легковесный подпроцесс, который работает в рамках процесса и обладает своим собственным стеком вызовов и выполнением инструкций. Множество потоков может работать параллельно в рамках одного процесса и совместно использовать ресурсы, такие как память и CPU, что позволяет эффективнее использовать вычислительные ресурсы компьютера. Потоки могут работать дайнамически, т.е. создаваться и завершаться в процессе работы приложения.
В Java потоки могут быть созданы путем наследования от класса Thread или через реализацию интерфейса Runnable. При запуске потока метод run() становится активным и выполняется в отдельном потоке параллельно с другими потоками в рамках процесса.
Например, следующий код можно использовать для создания потока в Java:
Thread myThread = new MyThread();
myThread.start();
где MyThread - пользовательский класс, унаследованный от класса Thread или реализующий интерфейс Runnable.
990. Дайте определение понятию “синхронизация потоков”.
"Синхронизация потоков" - это процесс контроля над доступом к общим ресурсам между разными потоками исполнения в многопоточной среде. Это важный аспект многопоточного программирования, так как одновременный доступ к общим ресурсам может привести к проблемам безопасности и непредсказуемости работы программы.
В языке Java для синхронизации потоков используются мониторы (или блокировки), которые позволяют потокам входить в критические секции кода поочередно, в порядке очереди, чтобы избежать конфликтов при обращении к общему ресурсу. Для атомарных операций есть специальные синхронизированные методы, которые блокируют объект (или класс), чтобы гарантировать, что только один поток может выполнять код метода в любой момент времени.
Java также предоставляет ключевые слова synchronized и volatile, которые используются для синхронизации потоков.
Ключевое слово synchronized может быть применено к методам и блокам кода, чтобы предотвратить одновременный доступ к общему ресурсу.
Ключевое слово volatile используется для обозначения переменных, значения которых могут быть изменены другими потоками, и гарантирует, что любое изменение будет видно всем потокам.
Синхронизация потоков достигается путем использования механизмов, таких как мониторы, блокировки, условные переменные, семафоры и других. В Java для синхронизации потоков используются ключевые слова synchronized, wait, notify, notifyAll, а также классы Lock, Condition и другие.
991. Как взаимодействуют программы, процессы и потоки?
Программы, процессы и потоки взаимодействуют друг с другом в Java и в других языках программирования следующим образом:
-
Программы- это наборы инструкций, написанных на Java или других языках программирования, которые могут выполняться на компьютере. Программы обычно состоят из одного или нескольких процессов. -
Процессы- это экземпляры выполнения программы на компьютере. Каждый процесс имеет свою собственную область памяти и выполняется в отдельном потоке выполнения, независимо от других процессов на компьютере. -
Потоки- это единицы выполнения внутри процесса. Каждый процесс может содержать несколько потоков, которые выполняются параллельно и совместно работают на решении задачи. Потоки внутри одного процесса имеют общую память и используют ее для обмена информацией.
Программы, процессы и потоки взаимодействуют друг с другом с помощью механизмов синхронизации и обмена информацией, таких как блокировки, семафоры и каналы. Например, процессы могут обмениваться данными, используя сокеты или механизмы межпроцессного взаимодействия, а потоки могут взаимодействовать друг с другом, используя блокировки или другие механизмы синхронизации.
992. В каких случаях целесообразно создавать несколько потоков?
В Java многопоточность может быть полезна во многих случаях, включая:
-
Улучшение производительности: Если есть задача, которую можно легко разделить на несколько частей, то ее можно решить быстрее, используя несколько потоков. Например, можно использовать несколько потоков для обработки массивов данных или поиска в базе данных. -
Использование блокирующих операций: Если задача включает блокирующие операции, такие как чтение из файла или сетевые операции, то многопоточность может помочь ускорить выполнение задачи, позволяя другим потокам выполнять вычисления в то время, как один поток блокируется. -
Событийный цикл: Если нужно обрабатывать события, такие как клики мыши или нажатия клавиш в интерактивном приложении, то многопоточность может помочь избежать блокировки пользовательского интерфейса, позволяя обрабатывать события в отдельных потоках.
Однако необходимо помнить, что использование многопоточности также может привести к проблемам синхронизации и состояния гонки, поэтому важно тщательно продумывать и тестировать свой код, особенно если он работает в многопоточной среде.
993. Что может произойти если два потока будут выполнять один и тот же код в программе?
Если два потока будут выполнять один и тот же код в программе на Java, то может произойти состояние гонки (race condition), когда оба потока пытаются изменять общую область памяти (например, одну и ту же переменную) в то же самое время, что может привести к непредсказуемому поведению программы.
Для предотвращения состояния гонки в Java можно использовать механизмы синхронизации, такие как ключевое слово synchronized, которое позволяет синхронизировать доступ к методу или блоку кода. Еще одним способом является использование объектов класса Lock и Condition.
Также можно использовать конструкцию volatile, чтобы гарантировать согласованность видимости переменной между потоками.
В целом, важно правильно проектировать многопоточные приложения, чтобы избежать состояний гонки и других проблем, связанных с многопоточностью.
994. Что вы знаете о главном потоке программы?
В Java главный поток программы также называется "main thread" и создается автоматически при запуске программы. Этот поток является основным потоком исполнения, который выполняет все инструкции, находящиеся в методе main().
Все операции, которые должны выполняться в основном потоке, должны быть помещены в метод main() или его вызовы. В Java также существует возможность создания новых потоков исполнения с помощью класса Thread.
Например, можно создать новый поток и запустить его следующим образом:
// Создание потока
Thread myThread = new Thread(new MyRunnable());
// Запуск потока
myThread.start();
Здесь MyRunnable - это класс , который реализует интерфейс Runnable и содержит код для выполнения в новом потоке.
Но следует помнить, что все UI-операции, такие как отрисовка на экране, должны выполняться в главном потоке программы. Если выполнить их в других потоках, то это может привести к нестабильности и ошибкам в работе приложения.
995. Какие есть способы создания и запуска потоков?
В Java существует два способа создания thread:
Создание с помощью класса Thread: вы можете создать новый класс, который расширяет класс Thread, и переопределите метод run. Затем вы создаете экземпляр этого класса и вызываете его метод start(), который запускает новый поток. Например:
public class MyThread extends Thread {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}
Реализация интерфейса Runnable: вы можете создать класс, который реализует интерфейс Runnable, который имеет единственный метод run(). Вы создаете экземпляр класса, который реализует Runnable, затем создаете экземпляр класса Thread, передавая в качестве аргумента конструктора экземпляр вашего класса Runnable, и вызываете метод start() из созданного экземпляра Thread. Например:
public class MyRunnable implements Runnable {
public void run() {
System.out.println("Hello from a thread!");
}
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start();
}
}
996. Какой метод запускает поток на выполнение?
В Java метод start() используется для запуска потока на выполнение. Когда вы вызываете метод start() на экземпляре класса Thread, JVM вызывает метод run() в новом потоке. Метод run() содержит код, который должен выполняться в новом потоке.
Пример:
Thread myThread = new Thread(){
public void run(){
System.out.println("Этот код выполняется в отдельном потоке");
}
};
myThread.start();
Здесь мы создаем новый экземпляр Thread и переопределяем метод run() для выполнения нужного кода. Затем мы вызываем метод start() на этом экземпляре Thread, чтобы запустить новый поток выполнения.
На месте переопределения метода run() можно передавать также Runnable объект для выполнения.
997. Какой метод описывает действие потока во время выполнения?
Метод run() описывает действие потока во время выполнения. Этот метод содержит код, который будет выполняться в отдельном потоке. Чтобы запустить поток, необходимо создать экземпляр объекта Thread с указанием реализации метода run(). Затем вызовите метод start() этого объекта, чтобы поток начал работать. Например, вот простой пример создания потока в Java:
public class MyThread implements Runnable {
public void run() {
// Код, выполняемый в потоке
}
public static void main(String[] args) {
Thread t = new Thread(new MyThread());
t.start();
}
}
В этом примере run() содержит код, который будет выполняться в потоке MyThread. Когда main() вызывает t.start(), MyThread.run() начнет выполняться в отдельном потоке.
998. Когда поток завершает свое выполнение?
оток завершает свое выполнение, когда метод run() в потоке завершает свое выполнение. Когда метод run() завершает свое выполнение, поток переходит в состояние TERMINATED. Если вы работаете в многопоточной среде, вы можете использовать метод join() для ожидания завершения выполнения потока. Например:
Thread thread = new Thread(new MyRunnable());
thread.start();
// ждем завершения выполнения потока
try {
thread.join();
} catch (InterruptedException e) {
// обработка исключения
}
Этот код запускает новый поток, ожидает его завершения и продолжает выполнение после того, как поток завершил свою работу.
999. Как синхронизировать метод?
Для синхронизации методов в Java можно использовать ключевое слово synchronized. Это означает, что только один поток может выполнять этот метод в определенный момент времени. Вот пример:
public class MyClass {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized void decrement() {
count--;
}
public synchronized int getCount() {
return count;
}
}
В этом примере все три метода синхронизированы, поэтому только один поток может выполнить любой из них в одно время. Методы могут быть синхронизированы на уровне объекта или класса, и должны быть описаны как public synchronized. Вы также можете использовать блокировки для синхронизации кода с использованием ключевого слова synchronized.
Например, чтобы синхронизировать код, содержащийся внутри блока, можно использовать следующий синтаксис:
public class MyClass {
private int count = 0;
private Object lock = new Object();
public void increment() {
synchronized (lock) {
count++;
}
}
public void decrement() {
synchronized (lock) {
count--;
}
}
public int getCount() {
synchronized (lock) {
return count;
}
}
}
Здесь мы создаем объект lock, который будет использоваться для блокировки. Затем мы используем блокировку для синхронизации каждого метода.
1000. Как принудительно остановить поток?
Для принудительной остановки потока в Java можно использовать метод interrupt() у объекта потока(Thread). Например, чтобы прервать выполнение потока myThread, необходимо вызвать у него метод interrupt():
myThread.interrupt();
После этого у потока будет установлен флаг прерывания(isInterrupted()), который можно использовать для принятия решений в методе run().
Вот пример:
Thread myThread = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
// do something
}
}
});
myThread.start();
// ...
myThread.interrupt(); // прерывание потока
1001. Дайте определение понятию “поток-демон”.
Поток-демон (daemon thread) в Java - это поток, который работает в фоновом режиме и не останавливает работу программы при завершении всех не-daemon потоков. Он может выполнять свою работу в бесконечном цикле или ждать на определенном условии (например, ожидание новых данных в очереди), и может завершиться только в случае принудительного прерывания работы всей программы.
Для того чтобы создать поток-демон, можно использовать метод setDaemon(true) на экземпляре класса Thread перед запуском потока.
Thread myThread = new MyThread();
myThread.setDaemon(true);
myThread.start();
Обратите внимание, что поток-демон не может быть использован для выполнения критически важных операций, таких как сохранение данных. Это связано с тем, что поток-демон может быть прерван в любой момент, если все не-daemon потоки остановят свою работу.
1002. Как создать поток-демон?
Для создания потока-демона в Java нужно установить соответствующий флаг при создании потока при помощи метода setDaemon(true) перед запуском потока. Вот пример кода:
Thread myThread = new Thread(() -> {
// код потока
});
myThread.setDaemon(true);
myThread.start();
В этом коде создается новый поток с лямбда-выражением в качестве тела, устанавливается флаг демона для этого потока и запускается. После запуска этот поток будет работать в фоновом режиме и будет автоматически завершаться, когда завершится основной поток программы.
1003. Как получить текущий поток?
Для получения текущего потока в Java можно использовать метод currentThread() класса Thread. Пример:
Thread currentThread = Thread.currentThread();
Этот код получит текущий поток и сохранит его в переменной currentThread. Вы можете использовать методы этого объекта, такие как getName() и getId(), для получения имени и идентификатора текущего потока соответственно. Например:
String threadName = currentThread.getName();
long threadId = currentThread.getId();
System.out.println("Текущий поток: " + threadName + " (ID=" + threadId + ")");
Этот код выведет имя и идентификатор текущего потока в консоль.
1004. Дайте определение понятию “монитор”.
В Java монитор — это механизм синхронизации, который можно использовать для обеспечения единовременного доступа к разделяемому ресурсу нескольким потокам.
В Java любой объект может быть использован в качестве монитора. Используя ключевое слово synchronized, можно ограничить доступ к критическим секциям кода только одному потоку в любой момент времени. Когда поток пытается получить доступ к методу или блоку кода, защищённым монитором, он автоматически блокируется и ждет, пока монитор освободится.
Для того, чтобы использовать монитор в Java, необходимо синхронизировать блок кода, который хочется защитить от одновременного доступа:
synchronized(obj) {
// код, который нужно защитить от доступа других потоков
}
где obj - это объект монитора. Если какой-то поток уже захватил монитор obj, то другие потоки будут заблокированы при попытке захватить этот монитор.
Использование мониторов в Java позволяет предотвратить race condition, deadlock и другие проблемы, связанные с параллельным доступом к разделяемым ресурсам.
1005. Как приостановить выполнение потока?
Для того, чтобы приостановить выполнение потока в Java, можно использовать метод Thread.sleep(). Этот метод приостанавливает выполнение текущего потока на заданное количество миллисекунд. Вот пример его использования:
try {
Thread.sleep(1000); // Приостановить поток на 1 секунду
} catch (InterruptedException e) {
// Обработка исключения
}
Также можно использовать метод wait() и notify() для передачи управления другому потоку. Вот пример использования этих методов:
// Создаем объект монитора
Object monitor = new Object();
// Поток 1
Thread thread1 = new Thread(() -> {
synchronized (monitor) {
try {
// Приостанавливаем выполнение потока и освобождаем монитор
monitor.wait();
} catch (InterruptedException e) {
// Обработка исключения
}
// Выполняем необходимые действия после возобновления выполнения потока
}
});
// Поток 2
Thread thread2 = new Thread(() -> {
synchronized (monitor) {
// Выполняем необходимые действия
// Уведомляем поток 1 о том, что можно продолжить выполнение
monitor.notify();
}
});
Этот код демонстрирует, как можно передавать управление между потоками, используя методы wait() и notify(). Оба потока синхронизируются на объекте монитора, и поток 2 уведомляет поток 1 о том, что можно продолжить выполнение, вызывая метод notify(). После этого поток 1 продолжает свое выполнение и выполняет необходимые действия.
1006. В каких состояниях может пребывать поток?
В Java потоки могут находиться в различных состояниях, в зависимости от того, что происходит внутри потока и внешних факторов.
Рассмотрим основные состояния потоков в Java:
NEW: поток был создан, но еще не запущен.RUNNABLE: поток запущен и готов к выполнению, но еще не получил процессорное время.BLOCKED: поток остановлен, поскольку ожидает освобождения локированного монитора.WAITING: поток остановлен и ожидает события, которое может быть вызвано другим потоком.TIMED_WAITING: поток остановлен и ожидает события, которое может быть вызвано только после таймаута.TERMINATED: поток завершен и больше не выполняется.
Примеры перевода потока из одного состояния в другое:
NEW-> RUNNABLE: поток становится готовым к выполнению при запуске с помощью метода start().RUNNABLE-> WAITING: поток вызывает метод wait(), чтобы ожидать события.RUNNABLE-> TIMED_WAITING: поток вызывает метод sleep() или wait(timeout) и ожидает события с таймаутом.RUNNABLE-> BLOCKED: поток пытается войти в секцию кода, защищенную заблокированным монитором.RUNNABLE-> TERMINATED: поток завершает свое выполнение, когда выполняется последний оператор в методе run().
1007. Что является монитором при вызове нестатического и статического метода?
В Java каждый объект имеет свой монитор, который может быть использован для синхронизации доступа к объекту из разных потоков. При вызове нестатического метода монитором будет сам объект, для которого этот метод вызван, а при вызове статического метода монитором будет класс, в котором определен этот метод. Таким образом, при вызове нестатического метода монитором будет экземпляр класса, а при вызове статического метода - класс. Для синхронизации доступа к методу можно использовать ключевое слово synchronized в объявлении метода или блоке кода. Пример:
public synchronized void doSomething() {
// код метода, который нужно синхронизировать
}
Также можно использовать объект монитора явно, если нужна более гибкая синхронизация. Для этого нужно получить монитор объекта с помощью ключевого слова synchronized, например:
Object monitor = obj;
synchronized (monitor) {
// блок кода, который нужно синхронизировать
}
Здесь obj - это объект, монитор которого будет использован для синхронизации.
1008. Что является монитором при выполнении участка кода метода?
В Java каждый объект имеет свой монитор, который может быть использован для синхронизации потоков при доступе к этому объекту. При выполнении участка кода метода монитором является объект, на котором вызывается метод с модификатором synchronized. Например, в следующем коде:
public synchronized void doSomething() {
// код метода
}
монитором будет объект, на котором вызывается метод doSomething(), т.е. this.
Также можно использовать блокировки для синхронизации:
Object obj = new Object();
synchronized(obj) {
// блок синхронизации
}
В этом случае монитором будет объект obj.
Нужно учитывать, что только один поток может захватить монитор объекта в определенный момент времени, и другие потоки будут ожидать освобождения монитора, чтобы получить доступ к объекту. Это гарантирует атомарность выполнения операций с объектом в многопоточной среде.
1009. Какие методы позволяют синхронизировать выполнение потоков?
В Java есть несколько методов, позволяющих синхронизировать выполнение потоков:
synchronized блок- позволяет выполнить блок кода только одному потоку в момент времени:-
Синхронизация метода:
public synchronized void myMethod() {
// код метода, который должен быть выполнен только одним потоком одновременно
}
-
Синхронизация блока:
synchronized(myObject) {
// код блока, который должен быть выполнен только одним потоком одновременно
}
-
wait() и notify() методы- позволяют потокам координировать свою работу, чтобы избежать состояния гонки и других проблем с синхронизацией. Метод wait() вызывается на объекте, в который блокирующий поток хочет войти, а метод notify() вызывается на том же объекте, когда блокирующий поток должен быть разблокирован и продолжить свою работу. -
- Метод wait() вызывается потоком, который ждет выполнения определенного условия. Он освобождает монитор объекта, который вызвал его, и приостанавливает выполнение потока, пока другой поток не вызовет метод notify() или notifyAll().
-
- Метод notify() вызывается потоком, который изменяет состояние объекта и оповещает другие потоки, которые вызвали метод wait(). Он будит только один из ожидающих потоков.
-
- Метод notifyAll() вызывается потоком, который изменяет состояние объекта и оповещает все ожидающие потоки.
-
ReentrantLock- позволяет потокам получать эксклюзивный доступ к критическим секциям кода, а также обеспечивает более гибкий и функциональный подход к синхронизации потоков. Включает методы lock() и unlock() для блокировки и разблокировки выполнения потоков.
1010. Какой метод переводит поток в режим ожидания?
Метод, который используется для перевода потока в режим ожидания в Java, называется wait(). Этот метод позволяет временно остановить выполнение потока и перевести его в ожидающее состояние, пока какое-то другое событие не произойдет. Метод wait() может быть вызван на объекте, и поток будет ожидать уведомления от другого потока, который может вызвать методы notify() или notifyAll() на том же объекте. Метод wait() также может принимать аргумент времени ожидания в миллисекундах. Если время истекло, поток продолжит выполнение. Пример использования метода wait():
synchronized (obj) {
while (condition) {
obj.wait();
}
// continue with execution after notified
}
где obj - объект, на котором вызывается wait(), а condition - условие, которое должно выполниться, чтобы продолжить выполнение потока.
1011. Какова функциональность методов notify и notifyAll?
Методы notify() и notifyAll() используются в Java для управления потоками. Оба метода используются, чтобы пробудить ожидающие потоки. Разница между ними заключается в том, что метод notify() пробуждает только один из ожидающих потоков, тогда как метод notifyAll() пробуждает все ожидающие потоки.
Пример использования метода wait() и notify() для синхронизации потоков в Java:
class Message {
private String message;
private boolean empty = true;
public synchronized String read() {
while(empty) {
try {
wait();
} catch (InterruptedException e) {}
}
empty = true;
notifyAll();
return message;
}
public synchronized void write(String message) {
while(!empty) {
try {
wait();
} catch (InterruptedException e) {}
}
empty = false;
this.message = message;
}
}
В этом примере класс Message имеет два метода, read() и write(). Метод read() ожидает, пока не будет доступно значение сообщения, а метод write() устанавливает значение сообщения. Методы wait() и notifyAll() используются для синхронизации потоков, чтобы потоки не пытались читать сообщения, которых еще нет, или записывать сообщения, когда другой поток еще не закончил чтение текущего сообщения.
1012. Что позволяет сделать метод join?
Метод join() в Java предназначен для ожидания завершения работы потока. То есть, если вызвать метод join() на объекте потока, то программа будет ждать завершения работы этого потока перед продолжением своей работы. Это может быть полезно, например, чтобы убедиться, что поток завершил свою задачу перед тем, как продолжать работу с результатами его работы. Например:
Thread t = new MyThread();
t.start(); // запускаем поток
t.join(); // ожидаем завершения работы потока
// продолжаем работу после завершения потока
Также стоит учитывать, что метод join() может бросить исключение InterruptedException, поэтому необходимо обрабатывать его в соответствующем блоке try-catch.
1013. Каковы условия вызова метода wait/notify?
Методы wait() и notify() в Java используются для управления выполнением потоков с помощью монитора объекта. Общие условия вызова этих методов:
Методы wait() и notify()должны вызываться внутри синхронизированного блока кода для объекта монитора.Метод wait()является блокирующим и заставляет вызывающий поток ждать, пока другой поток не вызовет метод notify() или notifyAll() для того же самого объекта монитора.Метод notify()разблокирует один из потоков, ожидающих того же самого объекта монитора, чтобы продолжить выполнение. Если есть несколько потоков, ожидающих, то непредсказуемо, какой из них будет разблокирован.Метод notifyAll()разблокирует все потоки, ожидающие того же самого объекта монитора. Когда один из этих потоков получает доступ к монитору, остальные остаются заблокированными.При вызове метода wait(), поток освобождает блокировку объекта монитора, что позволяет другим потокам использовать этот монитор.При вызове методов notify() или notifyAll(), поток не освобождает блокировки объекта монитора.Если вызвать метод notify() или notifyAll()до метода wait(), то сигнал будет утерян и вызванный метод останется заблокированным.
Эти методы используются для синхронизации потоков в Java, когда несколько потоков работают с общим ресурсом
1014. Дайте определение понятию “взаимная блокировка”.
Взаимная блокировка (deadlock) в Java - это ситуация, когда две или более нити (threads) заблокированы и ждут друг друга, чтобы продолжить работу, не выполняя при этом какую-либо полезную работу. Если две нити удерживают два различных монитора, а каждая из них ждет освобождения монитора, удерживаемого другой нитью, то возникает взаимная блокировка. Решением может быть снятие блокировки одной из нитей, чтобы она могла продолжить работу и освободить ресурсы для другой нити. Для предотвращения взаимной блокировки нужно правильно использовать блокировки, не допуская ситуации, когда один поток блокирует ресурс, не отпуская его, пока не получит доступ к другому ресурсу, находящемуся в распоряжении другого потока.
1015. Чем отличаются методы interrupt, interrupted, isInterrupted?
-
Метод interrupt()прерывает выполнение потока, вызывая исключение InterruptedException. Это может возникнуть в любой точке кода, который может генерировать это исключение, такие как wait(), sleep() и join(). -
Метод interrupted()- это статический метод, который используется для определения состояния прерывания потока, в котором он используется. Он возвращает true, если поток был прерван, и false, если он не был прерван. Этот метод также сбрасывает флаг прерывания. -
Метод isInterrupted()- это нестатический метод, который возвращает состояние прерывания потока. Он возвращает true, если поток был прерван, и false, если он не был прерван. Этот метод не сбрасывает флаг прерывания. Если его вызвать дважды подряд, то он вернет true только в том случае, если между двумя вызовами поток был прерван.
Итак, interrupt() выбрасывает исключение InterruptedException, interrupted() проверяет флаг прерывания и сбрасывает его, а isInterrupted() только проверяет флаг прерывания, не сбрасывая его.
1016. В каком случае будет выброшено исключение InterruptedException, какие методы могут его выбросить?
Исключение InterruptedException выбрасывается в Java в том случае, когда поток исполнения был прерван таким методом, как Thread.interrupt(), Object.wait(), Thread.sleep() или java.util.concurrent методы.
Например, если вы вызываете Thread.sleep() в потоке исполнения, который затем был прерван с помощью Thread.interrupt(), это приведет к выбросу InterruptedException.
Чтобы обработать это исключение, вы можете использовать конструкцию try-catch:
try {
// Some code that might throw InterruptedException
} catch (InterruptedException e) {
// Handle the exception
}
Это позволит вам выполнить необходимые операции, когда исключение произойдет, например почистить ресурсы или выйти из потока.
1017. Модификаторы volatile и метод yield().
Ключевое слово volatile в Java указывает, что переменная может одновременно изменяться несколькими потоками и что при доступе к ней следует использовать синхронизацию потоков.
Метод yield() используется, чтобы предложить, чтобы текущий поток уступил свое процессорное время другому потоку. Это намек, хотя и не гарантия планировщику, что текущий поток готов уступить свое текущее использование процессора. Вот пример использования volatile и yield() в Java:
public class Example {
private volatile boolean flag = false;
public void run() {
while (!flag) {
// do some work
Thread.yield();
}
// do something else
}
public void stop() {
flag = true;
}
}
В этом примере переменная флага является изменчивой, поскольку она подвержена одновременным изменениям. Метод run() проверяет значение переменной флага в цикле и вызывает Thread.yield(), чтобы разрешить выполнение других потоков. Метод stop() устанавливает переменную флага в значение true, в результате чего метод run() выходит из цикла и продолжает выполнять остальной код.
Обратите внимание, что использование yield() обычно не требуется в современных Java-приложениях, поскольку планировщик потоков обычно может управлять выполнением потоков без подсказок со стороны программиста.
1018. Пакет java.util.concurrent
Пакет java.util.concurrent предоставляет классы, интерфейсы и другие утилиты, связанные с параллелизмом, на языке программирования Java. Он включает в себя ряд инструментов для создания и управления параллельными приложениями, такими как блокировки, семафоры, атомарные переменные, пулы потоков и многое другое.
Некоторые часто используемые классы и интерфейсы в java.util.concurrent включают:
Lock: обеспечивает более обширные операции блокировки, чем можно получить с помощью синхронизированных методов и операторов.Semaphore: средство синхронизации, позволяющее ограниченному числу потоков одновременно обращаться к общему ресурсу.AtomicBoolean, AtomicInteger, AtomicLong: обеспечивают атомарный доступ к одному логическому, целочисленному или длинному значению соответственно.CountDownLatch: позволяет одному или нескольким потокам ожидать завершения набора операций, выполняемых в других потоках.Executor, ThreadPoolExecutor, Executors: предоставляют платформу для асинхронного выполнения задач с использованием пула рабочих потоков.
В целом пакет java.util.concurrent является важным пакетом Java для разработки высокопроизводительных масштабируемых параллельных приложений.
1019. Есть некоторый метод, который исполняет операцию i++. Переменная i типа int. Предполагается, что код будет исполнятся в многопоточной среде. Следует ли синхронизировать блок?
Для безопасного использования переменной i в многопоточной среде, необходимо синхронизировать блок кода, который увеличивает значение i. Однако, если в контексте задачи переменная i используется только в рамках одного потока, то нет необходимости в синхронизации блока.
Также стоит учитывать, что в Java тип int - это примитивный тип данных, который имеет атомарную операцию инкремента, то есть увеличение значения переменной i на 1 является неделимой операцией и не требует синхронизации в большинстве случаев.
Однако, если в задаче используется несколько операций с переменной i, которые могут быть выполнены неатомарно, то в этом случае необходимо применять синхронизацию для обеспечения безопасности операций и корректности работы приложения.
1020. Что используется в качестве mutex, если метод объявлен static synchronized? Можно ли создавать новые экземпляры класса, пока выполняется static synchronized метод?
В Java сам объект/класс используется как мьютекс, когда метод объявлен как статически синхронизированный. Это означает, что только один поток может одновременно выполнять метод для каждого класса.
Что касается создания новых экземпляров класса во время выполнения статического синхронизированного метода, то это разрешено. Синхронизированная блокировка удерживается на уровне класса, а не на уровне экземпляра, поэтому во время выполнения статического синхронизированного метода может быть создано несколько экземпляров класса. Однако если в экземпляре выполняется нестатический синхронизированный метод, любая попытка выполнить статический синхронизированный метод в том же классе будет заблокирована до тех пор, пока нестатический синхронизированный метод не завершится.
Обратите внимание, что блокировки статической синхронизации могут вызвать проблемы с производительностью, поскольку блокировка удерживается на уровне класса и потенциально может блокировать одновременный доступ нескольких потоков к другим синхронизированным методам того же класса. Поэтому важно использовать статическую синхронизацию осторожно и только тогда, когда необходимый.
1021. Предположим в методе run возник RuntimeException, который не был пойман. Что случится с потоком? Есть ли способ узнать о том, что Exception произошел (не заключая все тело run в блок try-catch)? Есть ли способ восстановить работу потока после того как это произошло?
Если в методе run возникает RuntimeException, который не был пойман, то поток завершится. Это может произойти, например, если в методе run будет вызван метод с ошибкой, например, вызов несуществующего метода у объекта.
Есть несколько способов узнать о том, что RuntimeException произошел, не заключая все тело run в блок try-catch. Один из таких способов - установить UncaughtExceptionHandler для потока. Например:
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// ...
}
});
thread.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
System.out.println("Exception occurred in thread " + t.getName() + ": " + e.getMessage());
}
});
thread.start();
Здесь мы создали поток и установили UncaughtExceptionHandler для него. Если в потоке возникнет исключение, оно будет передано UncaughtExceptionHandler, и мы сможем обработать его.
Если поток был завершен из-за RuntimeException, то его работу восстановить не удастся. Мы можем создать новый поток и запустить его, но это будет уже новый поток, а не старый, который был завершен.
1021. Какие стандартные инструменты Java вы бы использовали для реализации пула потоков?
Для реализации пула потоков в Java можно использовать Executor framework. Он предоставляет высокоуровневые классы Executor, ExecutorService, ThreadPoolExecutor, ScheduledExecutorService, которые облегчают работу с потоками и позволяют запускать асинхронные задачи. Здесь приведен пример, показывающий создание пула потоков с использованием ThreadPoolExecutor:
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExample {
public static void main(String[] args) {
int corePoolSize = 5;
int maxPoolSize = 10;
long keepAliveTime = 5000;
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(corePoolSize);
executor.setMaximumPoolSize(maxPoolSize);
executor.setKeepAliveTime(keepAliveTime, TimeUnit.MILLISECONDS);
executor.execute(new Task("Task 1"));
executor.execute(new Task("Task 2"));
executor.execute(new Task("Task 3"));
executor.shutdown();
}
}
class Task implements Runnable {
private String name;
public Task(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(name + " is running. Thread id: " + Thread.currentThread().getId());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
ThreadPoolExecutor создает пул потоков с фиксированной длиной, и все задачи, которые передаются в executor, выполняются в этих потоках. Он автоматически удаляет ненужные потоки, которые простаивают достаточно долго благодаря keepAliveTime. Количество потоков в пуле может быть настроено с помощью метода setMaximumPoolSize.
1022. Что такое ThreadGroup и зачем он нужен?
ThreadGroup в Java - это класс, который предоставляет удобный способ управления группами потоков в JVM. ThreadGroup используется для организации потоков в группы и позволяет управлять ими как единым целым. ThreadGroup предоставляет возможность проверять количество потоков в группе, приостанавливать и возобновлять выполнение потоков в группе и останавливать все потоки в группе одновременно.
ThreadGroup позволяет создать иерархическую структуру групп потоков. При создании новой группы потоков указывается родительская группа, которая создает связь между ними, образуя иерархическую структуру. Если поток не привязан к какой-либо группе, то он принадлежит к корневой группе, которая создается автоматически при запуске JVM.
Пример использования ThreadGroup:
ThreadGroup group = new ThreadGroup("MyGroup");
Thread thread1 = new Thread(group, new MyRunnable(), "Thread 1");
Thread thread2 = new Thread(group, new MyRunnable(), "Thread 2");
// Запуск потоков
thread1.start();
thread2.start();
// Приостановка работы всех потоков в группе
group.suspend();
// Возобновление работы всех потоков в группе
group.resume();
// Завершение работы всех потоков в группе
group.interrupt();
Мы создаем новую группу потоков с именем "MyGroup" и запускаем два потока, каждый привязывая к этой группе. Мы можем приостановить, возобновить или прервать выполнение всех потоков в группе одновременно с помощью методов suspend(), resume(), interrupt(), соответственно.
1023. Что такое ThreadPool и зачем он нужен?
ThreadPool (пул потоков) в Java представляет собой механизм, который позволяет эффективно управлять и переиспользовать потоки выполнения. Он представлен классом ThreadPoolExecutor из пакета java.util.concurrent.
Потоки выполнения используются для асинхронного выполнения кода и обработки задач. Однако создание нового потока для каждой задачи может быть ресурсоемким и приводить к излишней нагрузке на систему. ThreadPool позволяет создать ограниченное количество заранее созданных потоков, которые могут выполнять задачи из пула.
Основные преимущества использования ThreadPool включают:
Повышение производительности: При использовании пула потоков можно избежать накладных расходов на создание нового потока для каждой задачи. Задачи могут быть поставлены в очередь и выполняться параллельно в доступных потоках, что позволяет более эффективно использовать ресурсы системы.Управление ресурсами: Пул потоков позволяет определить оптимальное количество потоков для конкретной системы. Можно задать максимальное количество потоков, которое пул будет поддерживать одновременно, чтобы избежать перегрузки системы.Контроль нагрузки: Пул потоков может использоваться для ограничения количества задач, которые в данный момент могут выполняться параллельно. Это особенно полезно при работе с внешними ресурсами или ограниченными системными ресурсами, чтобы избежать их перегрузки.Упрощение программирования: Использование ThreadPool позволяет абстрагироваться от прямого управления потоками выполнения. Разработчику не нужно беспокоиться о создании и уничтожении потоков, поскольку пул самостоятельно управляет ими.
За счет этих преимуществ ThreadPool является полезным инструментом для многопоточного программирования в Java, который помогает оптимизировать использование ресурсов и повышает производительность при обработке задач.
1024. Что такое ThreadPoolExecutor и зачем он нужен?
ThreadPoolExecutor - это класс в языке Java, который предоставляет удобный способ создания и управления пулом потоков (thread pool). Пул потоков представляет собой группу заранее созданных потоков, которые могут выполнять задачи параллельно.
ThreadPoolExecutor выступает в роли исполнителя (executor) для задач, которые нужно выполнить асинхронно. Он автоматически управляет потоками, назначая им задачи из очереди задач. Когда задача завершается, поток освобождается и может быть использован для выполнения следующей задачи.
Основные преимущества ThreadPoolExecutor:
Управление ресурсами: Он предотвращает создание новых потоков для каждой задачи, что позволяет эффективно использовать ресурсы системы.Повышение производительности: Задачи выполняются параллельно, что позволяет ускорить выполнение программы.Ограничение количества потоков: Вы можете настроить максимальное количество потоков в пуле для контроля нагрузки на систему.Управление очередью задач: Если все потоки заняты, новые задачи могут быть поставлены в ожидание в очереди, пока не освободится поток.
ThreadPoolExecutor предоставляет различные методы для настройки параметров пула потоков, таких как размер пула, максимальное количество потоков, время ожидания и т. д. Это позволяет точно настроить пул под конкретные требования приложения.
Использование ThreadPoolExecutor упрощает работу с потоками в Java и способствует более эффективному использованию ресурсов системы.
1025. Что такое «атомарные типы» в Java?
Атомарные типы в Java представляют собой специальные классы из пакета java.util.concurrent.atomic, которые обеспечивают атомарность операций чтения и записи для определенных типов данных. Это означает, что операции с атомарными типами выполняются как неделимые и непрерываемые операции, гарантирующие целостность данных.
В Java предоставляются следующие атомарные типы:
AtomicBoolean: Позволяет выполнять атомарные операции над значениями типа boolean.AtomicInteger: Предоставляет атомарные операции над значениями типа int.AtomicLong: Позволяет выполнять атомарные операции над значениями типа long.AtomicReference: Предоставляет атомарные операции над ссылками на объекты.AtomicIntegerArray: Позволяет выполнять атомарные операции над массивами значений типа int.AtomicLongArray: Предоставляет атомарные операции над массивами значений типа long.AtomicReferenceArray: Позволяет выполнять атомарные операции над массивами ссылок на объекты.
Классы атомарных типов предлагают методы, такие как get() для получения текущего значения, set() для установки нового значения, getAndSet() для считывания текущего значения и установки нового значения, а также другие методы для выполнения атомарных операций, таких как инкремент, декремент, сравнение и т.д.
Атомарные типы особенно полезны в многопоточной среде, где несколько потоков могут одновременно обращаться к одному и тому же значению. Они гарантируют атомарность операций, что помогает предотвратить проблемы с состоянием гонки (race conditions) и обеспечивает корректное чтение и запись данных без необходимости использования блокировок или синхронизации.
1026. Зачем нужен класс ThreadLocal?
Класс ThreadLocal в Java используется для создания локальных переменных, которые будут иметь отдельное значение для каждого потока. Каждый поток, работающий с ThreadLocal, будет иметь свою собственную копию переменной, и изменения, внесенные одним потоком, не будут видны другим потокам.
Основная цель ThreadLocal - обеспечить безопасность потоков при работе с разделяемыми объектами или ресурсами. Вместо использования общих переменных, которые могут вызывать состояние гонки (race conditions) и неоднозначность результатов при доступе из нескольких потоков, каждый поток может иметь свою отдельную копию данных через ThreadLocal.
Некоторые примеры использования ThreadLocal:
Хранение контекста потока:ThreadLocal может использоваться для хранения и передачи информации о контексте выполнения текущего потока, такой как пользовательский идентификатор, язык, часовой пояс и т.д. Это особенно полезно в веб-приложениях, где каждый запрос обрабатывается отдельным потоком.Управление соединениями с базой данных: ThreadLocal позволяет каждому потоку иметь свое собственное соединение с базой данных, устраняя необходимость вручную управлять и передавать соединения между потоками.Форматирование даты и чисел: ThreadLocal может быть использован для сохранения экземпляров форматтеров даты или чисел, чтобы каждый поток имел свой независимый экземпляр для форматирования безопасности потоков.
Важно отметить, что ThreadLocal следует использовать осторожно, так как он может привести к утечке памяти, если не освобождается правильным образом. Когда поток больше не нуждается в своей локальной переменной, необходимо вызвать метод remove() на объекте ThreadLocal, чтобы избежать утечек памяти.
1027. Что такое Executor?
В Java Executor - это интерфейс из пакета java.util.concurrent, который предоставляет абстракцию для выполнения асинхронных задач. Он представляет собой механизм для управления потоками и позволяет разделять задачи на более мелкие, выполняемые параллельно.
Executor обеспечивает разделение между задачей (что нужно выполнить) и механизмом выполнения (как это будет выполнено). Он определяет всего один метод:
void execute(Runnable command);
Метод execute() принимает объект типа Runnable (или его подклассы) в качестве параметра и назначает его для выполнения. Исполнение самой задачи может происходить в отдельном потоке, пуле потоков или другой среде исполнения, управляемой конкретной реализацией Executor.
Некоторые распространенные реализации интерфейса Executor включают:
ExecutorService: Расширяет интерфейс Executor и добавляет дополнительные возможности, такие как возвратные значения и завершение задач. Предоставляет методы для управления циклами выполнения и получения результатов задач.ThreadPoolExecutor: Реализация ExecutorService, которая создает и управляет пулом потоков для выполнения задач. Позволяет контролировать параметры пула потоков, такие как размер пула, очередь задач и политику отклонения задач.ScheduledExecutorService: Расширение ExecutorService, которое поддерживает планирование выполнения задач в определенное время или с определенной периодичностью. Позволяет создавать периодические задачи и запускать их с заданным интервалом.
Использование Executor и его реализаций позволяет эффективно использовать ресурсы системы, управлять параллельным выполнением задач и повысить производительность приложений, особенно в случае большого количества асинхронных операций или длительных задач.
1028. Что такое ExecutorService?
ExecutorService - это интерфейс в пакете java.util.concurrent, который расширяет базовый интерфейс Executor и предоставляет более высокоуровневые функции для выполнения асинхронных задач. Он представляет собой службу исполнения (пул потоков), которая управляет жизненным циклом потоков и обеспечивает удобный способ управления множеством задач.
Интерфейс ExecutorService определяет несколько методов, включая:
submit(Runnable task): Представляет задачу типа Runnable для выполнения и возвращает объект Future, который представляет собой результат выполнения задачи. Метод submit() можно использовать для отправки задач на выполнение и получения их результатов, если они имеют значения возврата.submit(Callable<T> task): Аналогично предыдущему методу, но принимает задачу типа Callable, которая может возвращать значение. Возвращает объект Future, через который можно получить результат выполнения задачи.shutdown(): Закрывает ExecutorService после завершения всех ранее отправленных задач. Этот метод остановит прием новых задач и начнет процесс завершения работы пула потоков.shutdownNow(): Немедленно останавливает ExecutorService, прерывая выполняющиеся задачи и предоставляя список невыполненных задач.awaitTermination(long timeout, TimeUnit unit): Ожидает завершения работы ExecutorService в течение определенного времени. Метод блокирует текущий поток до тех пор, пока пул потоков не завершит свою работу или истечет указанный таймаут.
Множество других методов для управления состоянием, контроля выполнения задач и мониторинга активности пула потоков.
ExecutorService предоставляет удобный способ управления потоками и выполнением асинхронных задач. Он автоматически управляет пулом потоков, обеспечивает повторное использование потоков и контроль нагрузки системы. Это особенно полезно при работе с большим количеством задач или длительными операциями, когда требуется эффективное использование ресурсов и контроль над исполнением задач.
1029. Зачем нужен ScheduledExecutorService?
ScheduledExecutorService - это интерфейс в пакете java.util.concurrent, который расширяет интерфейс ExecutorService и предоставляет возможность планирования выполнения задач в будущем или с периодическим интервалом. Он используется для выполнения задач по расписанию.
Некоторые примеры использования ScheduledExecutorService:
Планирование однократного выполнения задачи: Можно запланировать выполнение задачи через определенное время с помощью метода schedule(Runnable task, long delay, TimeUnit unit). Например, вы можете запланировать выполнение определенной операции через 5 секунд.Планирование периодического выполнения задачи: Метод scheduleAtFixedRate(Runnable task, long initialDelay, long period, TimeUnit unit) позволяет запланировать выполнение задачи через определенное начальное время и затем продолжать ее выполнение с указанным периодом. Например, можно запланировать выполнение определенных действий каждые 10 секунд.Планирование выполнения задачи с задержкой между исполнениями: Метод scheduleWithFixedDelay(Runnable task, long initialDelay, long delay, TimeUnit unit) позволяет запланировать выполнение задачи через определенное начальное время и затем продолжать ее выполнение с указанным интервалом между исполнениями. Например, можно запланировать выполнение определенной операции с задержкой 2 секунды между исполнениями.
ScheduledExecutorService предоставляет удобный способ для планирования и выполнения задач в определенное время или с определенной периодичностью. Он обеспечивает надежную и гибкую работу с задачами, связанными с расписанием, и может быть полезен в различных сценариях, от автоматического обновления данных до планирования регулярных задач в приложении.
1030. Расскажите о модели памяти Java?
Модель памяти Java (Java Memory Model, JMM) определяет правила и гарантии относительно того, как потоки взаимодействуют с общей памятью при выполнении операций чтения и записи. Она обеспечивает консистентность и предсказуемость работы многопоточных программ.
Основные характеристики модели памяти Java:
Похоже на последовательное выполнение: JMM гарантирует, что программа будет работать так, как если бы все операции выполнялись последовательно в одном потоке. Это означает, что даже если в реальности операции выполняются параллельно, поведение программы не должно зависеть от конкретного порядка выполнения операций.Гарантии видимости: JMM определяет, когда изменения, сделанные одним потоком, будут видны другим потокам. Например, если один поток записывает значение в общую переменную, JMM гарантирует, что другие потоки увидят это новое значение после соответствующей синхронизации.Атомарность операций: JMM предоставляет атомарность для некоторых простых операций, таких как чтение и запись переменной типа int или boolean. Это означает, что эти операции гарантированно выполняются полностью и невозможно получить "сломанное" значение.Порядок выполнения операций: JMM определяет отношение порядка между операциями чтения и записи в разных потоках. В частности, она задает понятие happens-before (происходит-до), которое определяет, что результат операции записи будет виден для операции чтения, следующей за ней.Синхронизация: JMM предоставляет средства синхронизации, такие как ключевое слово synchronized и классы Lock, Semaphore и другие. Они обеспечивают возможность создания критических секций, блокировок и других механизмов для координации доступа к общим данным из разных потоков.
Соблюдение правил модели памяти Java важно для написания корректных и надежных многопоточных программ. Правильное использование синхронизации и средств, предоставляемых JMM, позволяет избегать проблем с состоянием гонки (race conditions), видимостью данных и другими проблемами, связанными с параллельным выполнением.
1031. Что такое «потокобезопасность»?
Потокобезопасность (thread safety) в Java относится к свойству кода или объекта, которое гарантирует корректное и безопасное выполнение операций одновременно из разных потоков. В многопоточной среде, где несколько потоков исполняются параллельно, потокобезопасный код обеспечивает правильность результатов и предотвращает возможные ошибки, такие как состояние гонки (race conditions), блокировки (deadlocks) и другие проблемы, связанные с конкурентным доступом к общим данным.
В Java существует несколько подходов для достижения потокобезопасности:
Синхронизация: Использование ключевого слова synchronized или блоков синхронизации (synchronized block) позволяет установить монитор (lock) на объекте или методе, чтобы гарантировать, что только один поток может выполнять код внутри защищенной области одновременно.Атомарные операции: Java предоставляет классы-обертки для некоторых базовых типов данных, таких как AtomicInteger, AtomicLong, AtomicBoolean, которые обеспечивают атомарные операции чтения и записи, исключая состояние гонки.Использование блокировок: Java предоставляет механизмы для управления блокировками, такие как ReentrantLock и ReadWriteLock, которые позволяют более гибко контролировать доступ к общим ресурсам.Использование неизменяемых (immutable) объектов: Если объект не может быть изменен после создания, то его можно безопасно использовать в многопоточной среде без необходимости дополнительных механизмов синхронизации.
Правильное обеспечение потокобезопасности критически важно для написания надежных и безопасных многопоточных приложений в Java.
1032. В чём разница между «конкуренцией» и «параллелизмом»?
В контексте многопоточности в Java, конкуренция (concurrency) и параллелизм (parallelism) являются двумя разными концепциями, связанными с одновременным выполнением задач. Вот их определения и различия:
Конкуренция (Concurrency):
Конкуренция означает, что несколько задач выполняются одновременно, но не обязательно одновременно на физическом уровне (на разных процессорах или ядрах). Задачи могут быть переключены между собой, чтобы дать иллюзию одновременного выполнения. В многопоточном приложении с конкуренцией потоки могут исполняться параллельно, если доступны ресурсы процессора, но также могут и переключаться по времени.
Параллелизм (Parallelism):
Параллелизм означает фактическое одновременное выполнение нескольких задач на разных физических ресурсах, таких как множество процессоров или ядер в многоядерной системе. При использовании параллелизма, задачи действительно выполняются одновременно и могут значительно увеличить производительность приложения.
Основное отличие между конкуренцией и параллелизмом заключается в том, что конкуренция описывает способность системы обрабатывать множество задач одновременно, независимо от физического параллелизма, в то время как параллелизм предполагает реальное одновременное выполнение задач на разных физических ресурсах.
В Java, понятие конкуренции охватывает использование потоков (threads) для создания асинхронных операций и управления доступом к общим данным. При помощи многопоточности можно достичь конкуренции даже на системах с одним процессором или ядром. С другой стороны, параллелизм в Java может быть достигнут с использованием параллельных стримов (parallel streams), фреймворков параллельной обработки данных (parallel processing frameworks) или явным созданием нескольких потоков, которые выполняются на разных процессорах или ядрах.
1033. Что такое «кооперативная многозадачность»? Какой тип многозадачности использует Java? Чем обусловлен этот выбор?
Кооперативная многозадачность (cooperative multitasking) - это тип многозадачности, при котором каждая задача явно передает управление другим задачам, когда она заканчивает свою работу или достигает точки синхронизации. В этом подходе каждая задача должна "сотрудничать" с другими задачами, чтобы обеспечить справедливое распределение ресурсов и позволить другим задачам выполняться.
Java использует кооперативную многозадачность на основе модели потоков (threads). В Java каждый поток имеет возможность выполнить некоторый код и затем явно передать управление другим потокам с помощью методов или конструкций, таких как yield(), sleep() или блокировки (synchronized). Каждый поток сам контролирует свое выполнение и сотрудничает с другими потоками, чтобы дать им возможность работать.
Выбор кооперативной многозадачности в Java обусловлен несколькими факторами:
Простота использования: Кооперативная многозадачность обычно более проста для программистов, так как они могут явно контролировать передачу управления между задачами без необходимости в сложной синхронизации и управлении потоками.Безопасность: Кооперативная многозадачность обеспечивает предсказуемое поведение и избегает состояний гонки и других проблем, связанных с параллельным доступом к общим данным, так как задачи явно сотрудничают и передают управление.Поддержка однопоточных моделей программирования: Java была разработана для поддержки как однопоточных, так и многопоточных приложений. Кооперативная многозадачность позволяет легко интегрировать асинхронное выполнение задач в однопоточные программы без необходимости полностью переходить на многопоточную модель.
Хотя кооперативная многозадачность имеет свои преимущества, она также имеет некоторые ограничения. Например, если одна задача заблокирует или не вернет управление, то это может привести к блокировке всего приложения. Это называется проблемой "замороженного потока" (frozen thread). В более современных версиях Java появились такие механизмы, как фреймворк Fork/Join и параллельные стримы (parallel streams), которые позволяют использовать и другие типы многозадачности, такие как неблокирующая многозадачность (non-blocking multitasking) или асинхронное выполнение задач (asynchronous task execution).
1034. Что такое ordering, as-if-serial semantics, sequential consistency, visibility, atomicity, happens-before, mutual exclusion, safe publication?
В Java существуют различные концепции и термины, связанные с параллельным выполнением кода и обеспечением корректности работы программы. Вот объяснения некоторых из них:
Ordering (упорядочивание): Управление порядком выполнения операций в многопоточной среде или при работе с гарантированно упорядоченными структурами данных.As-if-serial semantics (семантика "как если бы это выполнялось последовательно"): Это принцип, согласно которому результат выполнения программы должен быть таким же, как если бы все операции выполнялись последовательно, даже если фактически происходит параллельное выполнение.Sequential consistency (последовательная согласованность): Гарантирует, что все потоки видят один и тот же порядок операций, как если бы они выполнялись последовательно в одном потоке.Visibility (видимость): Обеспечивает, что изменения, сделанные одним потоком в разделяемых переменных, будут видны другим потокам. Без правильного обеспечения видимости возможны ошибки синхронизации и непредсказуемые результаты.Atomicity (атомарность): Гарантирует, что операция выполняется как неделимая единица и не может быть прервана или разделена на части. Атомарные операции обеспечивают согласованность данных в многопоточной среде.Happens-before (происходит-до): Устанавливает отношение порядка между операциями в коде. Если операция A происходит-до операции B, то B видит все изменения, внесенные A.Mutual exclusion (взаимное исключение): Механизм, позволяющий гарантировать, что только один поток может выполнять критическую секцию кода в определенный момент времени. Это обеспечивает консистентное состояние при доступе к разделяемым ресурсам.Safe publication (безопасная публикация): Методика обеспечения корректной и безопасной видимости объектов в многопоточной среде. Безопасная публикация гарантирует, что другие потоки будут видеть правильное и полностью инициализированное состояние объекта.
Эти концепции и термины являются основными для понимания и управления параллельным выполнением кода в Java и помогают гарантировать правильность и надежность программ.
1035. Чем отличается процесс от потока?
В Java процесс и поток - это два разных понятия, связанных с параллельным выполнением кода, и вот их отличия:
Процесс:
- Процесс представляет собой независимый экземпляр выполняющейся программы. Каждый процесс имеет свою собственную область памяти и состояние.
- Процессы изолированы друг от друга и не могут напрямую обмениваться данными или ресурсами. Передача данных между процессами требует использования механизмов межпроцессного взаимодействия (IPC).
- В Java создание и управление процессами выполняется с помощью класса Process и связанных классов из пакета java.lang.Process.
Поток:
- Поток представляет собой легковесный исполнитель внутри процесса. Он работает в рамках адресного пространства процесса и может иметь доступ к общей памяти и ресурсам процесса.
- Потоки внутри одного процесса могут параллельно выполняться и обмениваться данными без необходимости использовать механизмы IPC.
- В Java создание и управление потоками выполняется с помощью класса Thread или реализации интерфейса Runnable из пакета java.lang.Thread.
Основное отличие между процессами и потоками заключается в степени изоляции и использования общих ресурсов. Процессы полностью изолированы друг от друга, в то время как потоки работают в рамках одного процесса и могут обмениваться данными напрямую. Использование потоков более эффективно по ресурсам, так как они не требуют создания и управления отдельными адресными пространствами памяти для каждого потока, как это делается при создании процессов.
1036. Что такое «зелёные потоки» и есть ли они в Java?
Термин "зелёные потоки" ("green threads") обычно относится к механизму планирования и выполнения потоков, реализованному на уровне виртуальной машины (VM) или выполнении кода. Они являются альтернативой потокам операционной системы.
В старых версиях Java (до Java 1.2) использовалась технология зелёных потоков, где планирование и управление потоками выполнялось напрямую виртуальной машиной Java (JVM), а не операционной системой. Это позволяло Java-программам запускать и параллельно выполнять большое количество потоков на платформах, которые не поддерживали нативные многопоточные функции.
Однако начиная с Java 1.2 и более новых версий, реализации Java Virtual Machine (JVM) стали опираться на многопоточные возможности операционной системы, чтобы эффективно использовать ресурсы процессора и ядра. В современных версиях Java, таких как Java 8 и выше, зелёные потоки не используются по умолчанию, и управление потоками передаётся операционной системе.
Таким образом, в современных версиях Java, зелёные потоки не являются характерной особенностью. Вместо этого Java полагается на многопоточность операционной системы для эффективного выполнения параллельного кода.
1037. Каким образом можно создать поток?
В Java существует несколько способов создания потоков. Вот несколько из них:
Создание потока путем расширения класса Thread:
class MyThread extends Thread {
@Override
public void run() {
// Код, который будет выполняться в потоке
}
}
// Создание и запуск потока
MyThread thread = new MyThread();
thread.start();
Реализация интерфейса Runnable:
class MyRunnable implements Runnable {
@Override
public void run() {
// Код, который будет выполняться в потоке
}
}
// Создание и запуск потока
Thread thread = new Thread(new MyRunnable());
thread.start();
Использование лямбда-выражений (начиная с Java 8):
Thread thread = new Thread(() -> {
// Код, который будет выполняться в потоке
});
thread.start();
Использование исполнителя (Executor) из пакета java.util.concurrent:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> {
// Код, который будет выполняться в потоке
});
Когда вы создаете поток, вы должны переопределить метод run(), который содержит код, выполняемый в потоке. Затем вызовите метод start() для запуска потока.
Обратите внимание, что использование Runnable или исполнителей (Executor) является более предпочтительным подходом, так как позволяет отделить код потока от механизма выполнения и лучше поддерживает принципы объектно-ориентированного программирования.
1038. Чем различаются Thread и Runnable?
Thread и Runnable - это два различных подхода к созданию потоков в Java.
Thread:
- Thread является классом в Java, который представляет отдельный поток выполнения.
- При использовании Thread, вы расширяете класс Thread и переопределяете метод run(), содержащий код, выполняемый в потоке.
- Сам по себе Thread имеет некоторые дополнительные методы и функциональность, такие как управление жизненным циклом потока (старт, приостановка, возобновление), доступ к текущему потоку (с помощью Thread.currentThread()) и т.д.
- Код потока напрямую находится в классе Thread, что может усложнить повторное использование или расширение функциональности.
Runnable:
- Runnable является функциональным интерфейсом в Java, представляющим исполнительный блок кода, который может быть выполнен потоком.
- При использовании Runnable, вы реализуете интерфейс Runnable и определяете метод run(), содержащий код, выполняемый в потоке.
- Runnable не имеет дополнительного функционала, связанного с управлением жизненным циклом потока.
- Код потока находится в отдельном классе, который может быть передан экземпляру Thread для выполнения.
Выбор между использованием Thread и Runnable зависит от конкретной ситуации. В целом, использование Runnable рекомендуется, так как позволяет отделить код потока от механизма выполнения и лучше поддерживает принципы объектно-ориентированного программирования.
1039. В чём заключается разница между методами start() и run()?
Java, разница между методами start() и run() связана с созданием и запуском потока выполнения.
Метод start():
- Метод start() является частью класса Thread и используется для запуска нового потока.
- При вызове start(), происходит следующее:
-
- Создается новый поток выполнения.
-
- Вызывается метод run() в новом потоке.
- Код, определенный в методе run(), будет выполняться параллельно с остальным кодом программы в отдельном потоке.
- Запуск потока осуществляется путем вызова start() один раз для каждого экземпляра Thread.
Метод run():
- Метод run() является частью интерфейса Runnable или может быть переопределен в классе, расширяющем Thread.
- Когда вы вызываете метод run(), код, определенный внутри него, выполняется в текущем потоке.
- Если метод run() вызывается напрямую, то код выполняется последовательно без создания нового потока.
- Обычно метод run() используется для определения задачи (тела) потока, а не для запуска самого потока.
Таким образом, основная разница заключается в том, что start() создает новый поток и вызывает run() в этом потоке, тогда как run() выполняет код последовательно в текущем потоке. В большинстве случаев вы должны использовать метод start(), чтобы запустить выполнение кода в отдельном потоке.
1040. Как принудительно запустить поток?
В Java нет способа принудительно запустить поток, так как управление запуском потока полностью контролируется JVM (Java Virtual Machine). Когда вы вызываете метод start() для объекта класса Thread, JVM решает, когда и как запустить этот поток.
Метод start() является способом запросить JVM на запуск потока, но точное время запуска зависит от планировщика потоков в JVM. Планировщик определяет, когда и как долго каждый поток будет выполняться в рамках доступного процессорного времени.
Если вы хотите убедиться, что ваш поток начал выполнение, вы можете использовать метод isAlive(), который проверяет, выполняется ли поток или уже завершился. Например:
Thread thread = new Thread(myRunnable);
thread.start();
// Проверка, что поток запущен
if (thread.isAlive()) {
System.out.println("Поток запущен");
} else {
System.out.println("Поток не запущен");
}
Однако помните, что это просто проверка состояния потока в момент вызова метода isAlive(). Это не гарантирует, что поток будет активным или выполнит значимую работу в данный момент времени.
1041. Что такое «монитор» в Java?
В Java термин "монитор" относится к концепции синхронизации и взаимодействия потоков.
Монитор - это механизм, предоставляемый языком Java для обеспечения безопасности при работе с общими ресурсами (например, переменными или объектами) из нескольких потоков. Он основан на использовании ключевого слова synchronized и блоков синхронизации.
Когда метод или блок объявлен как synchronized, он получает монитор объекта, на котором вызывается этот метод или блок. Монитор позволяет только одному потоку за раз входить в блок синхронизации. Если другой поток пытается войти в блок, пока первый поток еще не вышел из него, то он будет ожидать до тех пор, пока монитор не будет освобожден первым потоком.
Монитор также обеспечивает принцип "видимости" изменений в общих данных между потоками. Когда поток захватывает монитор, все его изменения в общих данных становятся видимыми для других потоков после того, как они войдут в этот же монитор.
Мониторы позволяют синхронизировать доступ к общим ресурсам и предотвращают состояние гонок (race condition) и другие проблемы, связанные с параллельным выполнением потоков.
1042. Дайте определение понятию «синхронизация».
В контексте программирования на Java, синхронизация - это процесс координации или упорядочивания выполнения потоков с целью предотвращения состояний гонок (race conditions) и обеспечения корректного доступа к общим ресурсам.
Синхронизация позволяет управлять взаимодействием между потоками, чтобы они могли безопасно работать с общими данными. Когда несколько потоков одновременно обращаются к общей переменной или объекту, возникает возможность непредсказуемого поведения или ошибок, таких как гонки данных, взаимная блокировка (deadlock) и условие гонки (livelock).
Для решения этих проблем Java предоставляет механизмы синхронизации, например, использование ключевого слова synchronized, блоков синхронизации, методов wait(), notify() и notifyAll(), а также классов из пакета java.util.concurrent.
При помощи синхронизации можно достичь следующих целей:
Безопасность потоков: Гарантировать, что общие данные не будут испорчены при параллельном доступе.Упорядочение выполнения: Установить порядок выполнения потоков и синхронизировать их работы.Обеспечение видимости изменений: Гарантировать, что изменения, внесенные одним потоком, будут видны другим потокам.
Синхронизация позволяет создавать потокобезопасные программы, обеспечивая корректное взаимодействие между потоками и предотвращая проблемы, связанные с параллельным выполнением кода.
1043. Какие существуют способы синхронизации в Java?
В Java существует несколько способов синхронизации для обеспечения безопасности выполнения кода в многопоточной среде:
Ключевое слово synchronized: Можно использовать ключевое слово synchronized для создания синхронизированных блоков или методов. Когда поток входит в синхронизированный блок или вызывает синхронизированный метод, он захватывает монитор объекта, на котором происходит синхронизация, и другие потоки будут ожидать, пока монитор не будет освобожден.
Пример использования синхронизированного блока:
synchronized (объект) {
// Критическая секция
}
Пример использования синхронизированного метода:
public synchronized void synchronizedMethod() {
// Критическая секция
}
Объекты Lock из пакета java.util.concurrent.locks: Пакет java.util.concurrent.locks предоставляет различные реализации интерфейса Lock, такие как ReentrantLock, ReadWriteLock и другие. Эти объекты предоставляют более гибкий и мощный механизм синхронизации, чем ключевое слово synchronized. Для использования Lock необходимо вызывать методы lock() и unlock() для захвата и освобождения блокировки соответственно.
Пример использования объекта ReentrantLock:
private Lock lock = new ReentrantLock();
public void someMethod() {
lock.lock();
try {
// Критическая секция
} finally {
lock.unlock();
}
}
Объекты Condition из пакета java.util.concurrent.locks: При использовании объектов Lock можно создавать условия (Condition), которые позволяют потокам ожидать определенного условия перед продолжением выполнения. Методы await(), signal() и signalAll() используются для управления ожиданием и возобновлением работы потоков.
Пример использования Condition:
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void awaitCondition() throws InterruptedException {
lock.lock();
try {
while (!conditionMet) {
condition.await();
}
// Продолжение выполнения после удовлетворения условия
} finally {
lock.unlock();
}
}
public void signalCondition() {
lock.lock();
try {
conditionMet = true;
condition.signalAll();
} finally {
lock.unlock();
}
}
Синхронизированные коллекции:В Java также доступны специальные коллекции, которые предназначены для безопасного использования в многопоточной среде, такие как ConcurrentHashMap, CopyOnWriteArrayList и другие. Эти коллекции обеспечивают встроенную синхронизацию, чтобы гарантировать безопасность при параллельном доступе из нескольких потоков.
Пример использования ConcurrentHashMap:
Map<String, String> concurrentMap = new ConcurrentHashMap<>();
concurrentMap.put("key", "value");
Каждый из этих способов имеет свои преимущества и может быть применен в разных ситуациях в зависимости от требований вашей программы.
1044. В каких состояниях может находиться поток?
В Java поток может находиться в следующих состояниях:
NEW (новый): Поток создан, но ещё не был запущен.RUNNABLE (выполняемый): Поток готов к выполнению и ожидает выделения процессорного времени. Он может быть либо активным и выполняться, либо ожидать своей очереди на выполнение.BLOCKED (заблокированный): Поток заблокирован и ожидает освобождения блокировки другого объекта. Это происходит, когда поток пытается получить монитор блокировки, который уже захвачен другим потоком.WAITING (ожидающий): Поток находится в состоянии ожидания и будет оставаться в этом состоянии до получения определенного сигнала или прерывания. Например, поток может вызвать метод wait() и ожидать вызова метода notify() или notifyAll() другим потоком.TIMED_WAITING (ожидающий с таймаутом): Поток находится в состоянии ожидания с указанным временным интервалом. Это может произойти, когда поток вызывает методы sleep(long millis), join(long millis) или wait(long millis).TERMINATED (завершённый): Поток завершил свое выполнение и больше не может быть запущен.
Отметим, что переходы между состояниями потока управляются планировщиком потоков в Java, а точное поведение может зависеть от реализации JVM и операционной системы.
1045. Можно ли создавать новые экземпляры класса, пока выполняется static synchronized метод?
Нет, нельзя создавать новые экземпляры класса, пока выполняется static synchronized метод.
Когда метод помечен модификаторами static synchronized, он получает блокировку на уровне класса. Это означает, что только один поток может выполнить этот метод для данного класса в конкретный момент времени.
Если другой поток пытается создать новый экземпляр класса, который имеет static synchronized метод, то он будет ожидать освобождения блокировки класса. Блокировка будет удерживаться текущим потоком до тех пор, пока метод не будет полностью выполнен.
Таким образом, создание новых экземпляров класса будет заблокировано до того, как static synchronized метод завершит свое выполнение и освободит блокировку класса.
1046. Зачем может быть нужен private мьютекс?
Private мьютекс (также называемый эксклюзивным или монопольным мьютексом) может быть полезен в следующих ситуациях:
Защита от состояния гонки: Когда несколько потоков или процессов имеют доступ к общим данным, private мьютекс может использоваться для предотвращения одновременного доступа к этим данным. Он гарантирует, что только один поток или процесс может получить доступ к защищенным ресурсам в определенный момент времени. Это позволяет избежать состояний гонки и ошибок согласованности данных.Управление доступом к ресурсам: Private мьютекс может использоваться для управления доступом к разделяемым ресурсам, таким как файлы, базы данных или оборудование. Он позволяет одному потоку или процессу получить эксклюзивное право на доступ к ресурсам, пока другие потоки или процессы ожидают освобождения мьютекса.Реализация критических секций: Private мьютекс может быть использован для создания критических секций, то есть участков кода, которые должны выполняться атомарно. Когда поток входит в критическую секцию, он блокирует мьютекс, чтобы предотвратить доступ других потоков к этой секции. Это обеспечивает непрерывное выполнение критического кода без прерываний со стороны других потоков.Синхронизация потоков: Private мьютекс может использоваться для синхронизации потоков и координации их действий. Он может использоваться для ожидания определенного события или условия перед продолжением выполнения потока. Мьютекс может быть захвачен одним потоком и освобожден другим потоком, чтобы сигнализировать о наступлении события или удовлетворении условия.
В целом, private мьютекс предоставляет механизм для контроля доступа к ресурсам и синхронизации выполнения потоков, что важно для обеспечения правильности работы программы и избежания ошибок, вызванных одновременным доступом к общим данным.
1047. Как работают методы wait() и notify()/notifyAll()?
В Java методы wait(), notify() и notifyAll() используются для реализации механизма синхронизации и взаимодействия между потоками.
Методы wait() вызываются на объекте и заставляют поток, вызвавший этот метод, ожидать до тех пор, пока другой поток не вызовет метод notify() или notifyAll() на том же самом объекте.
Работа метода wait():
- Во-первых, поток вызывает метод wait() на объекте, который будет использоваться для синхронизации.
- Поток освобождает блокировку(монитор) объекта и ожидает до тех пор, пока другой поток не вызовет метод notify() или notifyAll() на том же объекте.
- Когда поток получает уведомление (метод notify() или notifyAll() был вызван на объекте), он просыпается и пытается получить блокировку объекта, чтобы продолжить свое выполнение.
Методы notify() и notifyAll() используются для уведомления потоков, ожидающих на объекте, что произошло определенное событие или изменение состояния. Разница между методами заключается в следующем:
- Метод notify() выбирает случайный поток из ожидающих на объекте и даёт ему сигнал для продолжения выполнения. Остальные потоки остаются в состоянии ожидания.
- Метод notifyAll() уведомляет все ожидающие потоки на объекте, что позволяет им продолжить выполнение. Важно отметить, что методы wait(), notify() и notifyAll() должны вызываться из синхронизированного контекста, то есть в блоке synchronized или при использовании монитора объекта (synchronized(object)).
Эти методы используются для координирования работы между различными потоками и позволяют достичь согласованности и синхронизации взаимодействия потоков в Java.
1048. В чем разница между notify() и notifyAll()?
Методы notify() и notifyAll() в Java используются для уведомления потоков, ожидающих на объекте, о том, что произошло определенное событие или изменение состояния.
Основная разница между notify() и notifyAll() заключается в следующем:
-
notify(): Этот метод выбирает случайный поток из ожидающих на объекте и даёт ему сигнал (уведомление) для продолжения выполнения. Остальные потоки остаются в состоянии ожидания. Если есть несколько потоков, которые ожидают на объекте, то не гарантируется, какой именно поток будет выбран. -
notifyAll(): Этот метод уведомляет все ожидающие потоки на объекте, что позволяет им продолжить выполнение. Все потоки, ожидающие на объекте, будут разбужены. Каждый поток должен повторно проверить условие ожидания для принятия решения о дальнейшем выполнении.
Выбор между notify() и notifyAll() зависит от требований вашего приложения и логики работы потоков.
Если вам необходимо уведомить только один случайный поток, который ожидает на объекте, то вы можете использовать notify(). Это может быть полезно, например, если вы хотите передать некоторые данные или ресурсы только одному потоку.
С другой стороны, если вам нужно уведомить все ожидающие потоки, чтобы они продолжили выполнение, то notifyAll() будет правильным выбором. Это может быть полезно, когда несколько потоков ожидают выполнения какого-либо общего условия или когда изменение состояния объекта должно быть известно всем потокам.
Важно отметить, что методы notify() и notifyAll() должны вызываться из синхронизированного контекста, то есть в блоке synchronized или при использовании монитора объекта (synchronized(object)).
1049. Почему методы wait() и notify() вызываются только в синхронизированном блоке?
Методы wait() и notify() в Java вызываются только в синхронизированном блоке, потому что они используют механизм синхронизации объектов для управления потоками.
В Java каждый объект имеет внутренний монитор (или блокировку), который используется для обеспечения эксклюзивного доступа к объекту одним потоком в определенный момент времени. Когда поток пытается получить монитор объекта, он должен войти в синхронизированный контекст. Это может быть выполнено с помощью ключевого слова synchronized или при использовании метода synchronized на объекте.
Методы wait() и notify() являются частью механизма синхронизации объектов в Java и требуют владения монитором объекта для своего корректного выполнения. Вот почему они должны вызываться только внутри синхронизированного блока или метода.
Когда поток вызывает wait() на объекте, он освобождает монитор объекта и переходит в состояние ожидания до тех пор, пока другой поток не вызовет notify() или notifyAll() на том же самом объекте. Вызывая wait(), поток передает управление другим потокам и ожидает уведомления для продолжения своей работы.
Аналогично, когда поток вызывает notify() или notifyAll(), он уведомляет один или все ожидающие потоки (которые ранее вызвали wait() на том же объекте), что они могут продолжить выполнение. Важно вызывать notify() или notifyAll() только после изменения состояния объекта, которое должно быть известно ожидающим потокам.
Использование синхронизированных блоков и методов вокруг вызовов wait() и notify() обеспечивает правильную синхронизацию и координацию между потоками, предотвращая возникновение гонок данных или других проблем, связанных с параллельным выполнением потоков.
1050. Чем отличается работа метода wait() с параметром и без параметра?
В Java метод wait() может быть вызван как с параметром, так и без параметра. Вот их различия:
wait(): Этот вариант метода wait() вызывается без параметра. Когда поток вызывает wait() без параметра, он переходит в состояние ожидания до тех пор, пока другой поток не вызовет notify() или notifyAll() на том же объекте. При получении уведомления поток продолжит свое выполнение.
Пример использования:
synchronized (monitorObject) {
while (<condition>) {
try {
monitorObject.wait();
} catch (InterruptedException e) {
// Обработка исключения
}
}
// Код, который будет выполнен после получения уведомления
}
wait(long timeout): В этом варианте метода wait() указывается временной интервал (timeout), в миллисекундах, в течение которого поток будет ожидать уведомления. Если за указанный интервал времени не произошло уведомления, поток самостоятельно просыпается и продолжает свое выполнение.
Пример использования:
synchronized (monitorObject) {
while (<condition>) {
try {
monitorObject.wait(1000); // Ожидание 1 секунду
} catch (InterruptedException e) {
// Обработка исключения
}
}
// Код, который будет выполнен после получения уведомления или по истечении времени ожидания
}
Оба варианта метода wait() используются для синхронизации и координации между потоками. Они позволяют одному потоку передать управление другому потоку и ожидать определенного условия или уведомления, прежде чем продолжить выполнение.
1051. Чем отличаются методы Thread.sleep() и Thread.yield()?
Методы Thread.sleep() и Thread.yield() влияют на выполнение потоков, но отличаются по своему действию:
Thread.sleep(): Этот метод приостанавливает выполнение текущего потока на указанный период времени (в миллисекундах). После истечения указанного времени поток возобновляет свое выполнение.
Пример использования:
try {
Thread.sleep(1000); // Приостановить выполнение потока на 1 секунду
} catch (InterruptedException e) {
// Обработка исключения
}
Метод Thread.sleep() может быть полезен, когда необходимо добавить задержку между операциями или создать паузу в выполнении потока. Однако следует быть осторожным, чтобы избегать чрезмерного использования этого метода, так как он может привести к неэффективности работы программы.
Thread.yield(): Этот метод предлагает "отдать" процессорное время другим потокам с тем же приоритетом, которые готовы к выполнению. Если есть другие потоки с аналогичным приоритетом, они получат возможность продолжить выполнение, а текущий поток может остаться в состоянии готовности.
Пример использования:
Thread.yield(); // Предоставить возможность для выполнения другим потокам
Метод Thread.yield() может быть полезен в ситуациях, когда потоки с более высоким приоритетом могут забирать большую часть процессорного времени, и низкоприоритетному потоку нужно предоставить возможность выполнения.
Важно отметить, что использование Thread.sleep() и Thread.yield() следует осуществлять с учетом требований и логики вашего кода. Они должны быть применены с осторожностью, чтобы избежать нежелательных эффектов или неэффективной работы приложения.
1052. Как работает метод Thread.join()?
Метод Thread.join() используется для ожидания завершения выполнения другого потока. Когда вызывается метод join() на определенном потоке, текущий поток будет приостановлен до тех пор, пока указанный поток не завершится.
Синтаксис метода join() следующий:
public final void join() throws InterruptedException
Вызов метода join() может выбросить исключение типа InterruptedException, поэтому требуется обработка этого исключения или его объявление в сигнатуре метода.
Пример использования метода join():
Thread thread = new Thread(new MyRunnable());
thread.start(); // Запуск потока
try {
thread.join(); // Ожидание завершения потока
} catch (InterruptedException e) {
// Обработка исключения
}
В приведенном примере поток thread запускается, а затем метод join() блокирует текущий поток, пока thread не завершит свое выполнение.
Метод join() позволяет координировать выполнение различных потоков, например, дождаться завершения потока перед продолжением работы основного потока или перед выполнением последующих операций, зависящих от результата работы другого потока.
Важно учесть, что использование метода join() может вызывать задержку выполнения программы, особенно если поток, на котором вызывается join(), продолжает работать в течение длительного времени.
1053. Что такое deadlock?
Deadlock (взаимная блокировка) - это ситуация в многопоточном программировании, когда два или более потока зацикливаются и ожидают ресурсы, которые контролируют другие потоки. В результате ни один из потоков не может продолжить свою работу.
Deadlock возникает, когда выполнены следующие условия, называемые "четырьмя условиями взаимной блокировки":
Взаимная исключительность (Mutual Exclusion): Потоки требуют доступа к ресурсу, который не может быть одновременно использован более чем одним потоком.Удержание и ожидание (Hold and Wait): Поток, уже удерживающий некоторый ресурс, запрашивает доступ к другому ресурсу, удерживаемому другим потоком, и ожидает его освобождения.Отсутствие прерывания (No Preemption): Ресурсы не могут быть принудительно изъяты у потоков, которые их удерживают. Только сам поток может освободить ресурсы по завершению своего выполнения.Циклическая зависимость на графе запросов ресурсов: Существует цикл потоков, где каждый поток ожидает ресурс, удерживаемый следующим потоком в цепочке. Когда эти условия выполняются одновременно, возникает взаимная блокировка, и все потоки, участвующие в блокировке, останавливаются и не могут продолжить работу до тех пор, пока блокировка не будет разрешена внешним вмешательством.
Deadlock является проблемой в многопоточном программировании, и его следует избегать. Для этого можно использовать стратегии, такие как правильная упорядоченность получения ресурсов, избегание ожидания на двух ресурсах одновременно, использование таймаутов или использование алгоритмов, предотвращающих возникновение взаимной блокировки.
1054. Что такое livelock?
Livelock (живая блокировка) - это ситуация в многопоточном программировании, когда два или более потока находятся в состоянии постоянного переключения и не могут продвинуться дальше, хотя они активны и выполняют некоторую работу. В отличие от deadlock (взаимной блокировки), где потоки ожидают друг друга, в livelock потоки активно реагируют на действия других потоков, что приводит к бесконечному циклу взаимодействия.
В livelock два или более потока могут постоянно менять свои состояния, выполнять операции и откатываться назад, но в конечном итоге не достигают прогресса или завершения задачи. Это может происходить, когда потоки пытаются избежать конфликтов или взаимной блокировки, но их стратегии обхода друг друга не дают им возможности пройти дальше.
Примером livelock может быть ситуация, когда два человека стоят перед узким проходом и каждый из них пытается уступить дорогу другому. Они продолжают двигаться туда-сюда, но ни один из них не может пройти, так как каждый всегда уступает дорогу другому.
Livelock является нежелательным состоянием в многопоточном программировании, поскольку потоки тратят ресурсы на бесполезные операции и не могут завершить свою работу. Для предотвращения livelock необходимо разработать стратегии обработки конфликтов и взаимодействия между потоками, чтобы избежать застревания в бесконечных циклах взаимодействия.
1055. Как проверить, удерживает ли поток монитор определённого ресурса?
В Java вы можете проверить, удерживает ли поток монитор определенного ресурса с помощью метода Thread.holdsLock(Object obj). Этот метод позволяет проверить, удерживает ли текущий поток монитор объекта, указанного в качестве аргумента.
Вот пример использования метода holdsLock:
Object resource = new Object();
// В блоке кода поток получает монитор ресурса
synchronized (resource) {
// Проверяем, удерживает ли текущий поток монитор ресурса
boolean holdsLock = Thread.holdsLock(resource);
if (holdsLock) {
System.out.println("Текущий поток удерживает монитор ресурса.");
} else {
System.out.println("Текущий поток не удерживает монитор ресурса.");
}
}
В этом примере мы создаем объект resource и захватываем его монитор с помощью блока synchronized. Затем мы используем метод holdsLock(resource), чтобы проверить, удерживает ли текущий поток монитор этого ресурса. Результат выводится на консоль.
Обратите внимание, что метод holdsLock является статическим методом класса Thread, поэтому вызывайте его непосредственно через класс Thread.
1056. На каком объекте происходит синхронизация при вызове static synchronized метода?
При вызове static synchronized метода синхронизация происходит на объекте класса, в котором определен этот метод. Каждый класс в Java имеет свой монитор, который используется для синхронизации доступа к статическим методам и полям этого класса.
Когда поток вызывает static synchronized метод, он должен получить монитор объекта класса, чтобы выполнить метод. Если монитор уже занят другим потоком, то вызывающий поток будет ожидать освобождения монитора.
Это отличается от синхронизации на экземплярных методах, где синхронизация происходит на уровне конкретного экземпляра объекта.
1057. Для чего используется ключевое слово volatile, synchronized, transient, native?
В Java ключевые слова volatile, synchronized, transient и native используются для различных целей:
volatile: Ключевое слово volatile применяется к переменным и обозначает, что значение этой переменной может быть изменено несколькими потоками, и эти изменения должны быть видимы всем остальным потокам. Использование volatile гарантирует, что операции чтения и записи этой переменной производятся из основной памяти, а не из кэша потока, что помогает предотвратить ошибки синхронизации.synchronized: Ключевое слово synchronized используется для создания критической секции (блокировки), в которой только один поток может выполнять код в заданное время. Это обеспечивает синхронизацию доступа к общим ресурсам и предотвращает состояние гонки и другие проблемы многопоточности.transient: Ключевое слово transient используется в контексте сериализации объектов. При сериализации объекта ключевое слово transient указывает на то, что соответствующее поле не должно быть сериализовано (сохранено в поток) и восстановлено при десериализации. Это может быть полезно, если поле содержит временные данные или не является сериализуемым.native: Ключевое слово native используется для объявления метода, реализация которого находится в коде, написанном на другом языке, таком как C или C++. Метод, помеченный как native, обеспечивает связь с нативным кодом, который может выполнять операции, недоступные в Java, например, взаимодействие с операционной системой или использование специфических библиотек.
Важно отметить, что использование этих ключевых слов требует понимания соответствующих концепций и осторожности при их применении. Они могут повлиять на поведение программы и требуют правильного использования.
1058. В чём различия между volatile и Atomic переменными?
Ключевое слово volatile и классы из пакета java.util.concurrent.atomic, такие как AtomicInteger, AtomicLong и другие, оба используются для обеспечения потокобезопасности в многопоточной среде, но есть некоторые различия:
Вид переменных: volatile может применяться только к переменным, в то время как классы из пакета java.util.concurrent.atomic предоставляют атомарные операции для определенных типов данных, таких как целые числа (AtomicInteger, AtomicLong), булевы значения (AtomicBoolean), ссылки (AtomicReference) и т.д.
Атомарность операций: Классы из пакета java.util.concurrent.atomic предоставляют атомарные операции чтения и записи для соответствующих типов данных. Это означает, что операции чтения и записи этих переменных являются атомарными и гарантированно безопасны в многопоточной среде. С другой стороны, ключевое слово volatile обеспечивает только видимость изменений значения переменной между потоками, но не обеспечивает атомарности операций.
Работа с состоянием: Классы из пакета java.util.concurrent.atomic позволяют выполнять атомарные операции над переменными, такие как инкремент, декремент, обновление и т.д. Они предоставляют методы, которые гарантируют атомарность операций над переменными. С другой стороны, volatile применяется к переменной целиком и обеспечивает видимость ее изменений между потоками, но не предоставляет специфических атомарных операций.
Область применения: volatile наиболее полезно, когда переменная используется для синхронизации состояния или флага, например, для сигнализации остановки потока. Классы из пакета java.util.concurrent.atomic особенно полезны, когда требуется выполнение атомарных операций над числовыми значениями или ссылками в многопоточной среде.
В целом, использование volatile и классов из пакета java.util.concurrent.atomic зависит от конкретной ситуации и требований вашей программы. Если вам нужно обеспечить только видимость изменений переменной, то volatile может быть хорошим выбором. Если вам нужно обеспечить атомарность операций над переменными или выполнение сложных операций, вы можете воспользоваться классами из пакета java.util.concurrent.atomic.
1059. В чём заключаются различия между java.util.concurrent.Atomic*.compareAndSwap() и java.util.concurrent.Atomic*.weakCompareAndSwap().
Различия между методами compareAndSwap() и weakCompareAndSwap() в классах из пакета java.util.concurrent.atomic заключаются в их гарантиях относительно успешности операции сравнения и обмена (compare-and-swap).
Метод compareAndSwap():
- Этот метод является строгим и гарантирует атомарность операции compare-and-swap.
- Если текущее значение переменной соответствует ожидаемому значению, то происходит обмен на новое значение, и метод возвращает true.
- Если текущее значение не соответствует ожидаемому значению, то ничего не происходит, и метод возвращает false.
- В случае успешного выполнения операции обмена, гарантируется, что другие потоки увидят новое значение переменной.
Метод weakCompareAndSwap():
- Этот метод является слабым и не гарантирует полную атомарность операции compare-and-swap.
- Если текущее значение переменной соответствует ожидаемому значению, то может произойти обмен на новое значение и метод возвращает true.
- Однако, если текущее значение не соответствует ожидаемому значению, поведение метода не определено. Он может завершиться с ошибкой или вернуть false.
- При успешном выполнении операции обмена, не гарантируется, что другие потоки увидят новое значение переменной.
Разница в гарантиях атомарности операции и поведении при несоответствии ожидаемого значения позволяют методу weakCompareAndSwap() быть более производительным в определенных сценариях, но менее предсказуемым и надежным. В то же время, метод compareAndSwap() обеспечивает строгую атомарность операции compare-and-swap и предоставляет более надежные гарантии видимости изменений между потоками.
Выбор между этими методами зависит от требований вашей программы и уровня гарантий, которые вам необходимы. Если вам нужна полная атомарность и надежность операции сравнения и обмена, используйте compareAndSwap(). Если вы готовы принять некоторые ограничения и хотите достичь большей производительности, можете использовать weakCompareAndSwap().
1060. Что значит «приоритет потока»?
В Java, приоритет потока относится к числовой оценке, которую вы можете присвоить потоку, чтобы указать относительную важность или приоритет его выполнения по сравнению с другими потоками. Приоритеты потоков используются планировщиком потоков для определения порядка выполнения потоков.
Каждый поток в Java имеет свой приоритет, который можно установить с помощью метода setPriority(int priority) класса Thread. В классе Thread определены следующие константы приоритетов:
Thread.MIN_PRIORITY (1): Минимальный приоритет.Thread.NORM_PRIORITY (5): Нормальный приоритет (значение по умолчанию).Thread.MAX_PRIORITY (10): Максимальный приоритет. Планировщик потоков обычно учитывает приоритеты потоков при принятии решения о том, какой поток будет выполняться в данный момент времени. Однако гарантии относительного порядка выполнения потоков с разными приоритетами не даются. Планировщик может использовать различные алгоритмы планирования в разных реализациях JVM и на разных операционных системах.
Важно отметить, что приоритеты потоков не гарантируют абсолютного порядка выполнения. Даже если один поток имеет более высокий приоритет, другой поток с меньшим приоритетом все равно может быть выбран для выполнения планировщиком. Приоритеты служат скорее как указание предпочтений для планировщика, но не являются строгой командой о порядке выполнения.
В целом, использование приоритетов потоков должно быть обдуманным и осознанным, поскольку неправильное использование приоритетов может привести к проблемам, таким как чрезмерная конкуренция за ресурсы или "голодание" потоков с более низким приоритетом.
1061. Что такое «потоки-демоны»?
В Java потоки-демоны (daemon threads) - это специальный тип потоков, которые работают в фоновом режиме и обслуживают другие потоки, называемые пользовательскими потоками (user threads). Основная особенность потоков-демонов заключается в том, что они не мешают завершению программы, когда все пользовательские потоки завершены.
Когда основной поток Java (обычно главный поток) завершает свое выполнение, JVM проверяет, остались ли активные потоки-демоны. Если все оставшиеся потоки являются потоками-демонами, JVM завершает работу и программа полностью прекращает выполнение без ожидания завершения демонов.
Потоки-демоны полезны для выполнения фоновых задач, таких как автоматическое сохранение данных, синхронизация или очистка ресурсов во время работы пользователя. Они могут выполняться параллельно с пользовательскими потоками, и их основная задача состоит в поддержке работы приложения, а не в реализации бизнес-логики.
Чтобы установить поток в качестве потока-демона, используйте метод setDaemon(true) перед запуском потока. Пример:
Thread daemonThread = new Thread(new MyRunnable());
daemonThread.setDaemon(true);
daemonThread.start();
Важно отметить, что потоки-демоны должны быть созданы до запуска любых пользовательских потоков. После запуска поток не может изменить свой статус на поток-демон.
1062. Можно ли сделать основной поток программы демоном?
Нет, нельзя сделать основной поток программы демоном в Java. Основной поток, также известный как главный поток (main thread), не может быть установлен в качестве потока-демона.
Потоки-демоны должны быть явно созданы и запущены после старта основного потока. Основной поток выполняет код метода main, который является точкой входа в программу, и он сам по себе не может быть установлен в качестве потока-демона.
Однако вы можете создать новый поток, установить его в качестве потока-демона и запустить вашу основную логику программы в этом потоке. Например:
public class Main {
public static void main(String[] args) {
Thread daemonThread = new Thread(new MyRunnable());
daemonThread.setDaemon(true);
daemonThread.start();
// Основная логика программы
// ...
}
}
В этом примере создается новый поток с использованием интерфейса Runnable (MyRunnable - пользовательская реализация интерфейса Runnable). Затем этот поток устанавливается в качестве потока-демона с помощью метода setDaemon(true) перед запуском. После этого вы можете выполнить остальную логику программы в основном потоке или создать другие пользовательские потоки.
1063. Что значит «усыпить» поток?
В Java "усыпление" потока означает временную остановку выполнения потока на заданное количество времени. Когда поток усыплен, он переходит в состояние "ожидания" и не выполняет никаких операций в течение указанного периода времени.
Усыпление потока может быть полезным в ситуациях, когда вы хотите замедлить выполнение потока или добавить паузу между операциями. Например, это может быть полезно для синхронизации потоков или создания задержки перед повторным выполнением какой-либо операции.
В Java усыпление потока выполняется с использованием метода Thread.sleep(). Метод принимает аргумент, представляющий количество времени в миллисекундах, на которое нужно усыпить поток. Затем поток будет приостановлен на указанное время.
Пример использования Thread.sleep():
public class Main {
public static void main(String[] args) {
System.out.println("Начало выполнения");
try {
// Усыпляем поток на 2 секунды (2000 миллисекунд)
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Завершение выполнения");
}
}
В этом примере основной поток программы будет усыплен на 2 секунды после вывода строки "Начало выполнения". Затем, после того как проходит указанное время, поток продолжит свое выполнение и выведет строку "Завершение выполнения".
1064. Чем отличаются два интерфейса Runnable и Callable?
Интерфейсы Runnable и Callable в Java представляют два различных способа для создания многопоточных задач, которые могут быть выполнены другими потоками.
Runnable:
- Определен в пакете java.lang.
- Представляет простую функциональность, которая может быть выполнена параллельно.
- Имеет единственный метод void run(), который не принимает аргументов и не возвращает результат.
- Метод run() содержит код, который будет выполняться в отдельном потоке.
- Когда объект Runnable передается в конструктор класса Thread, он становится исполняемым кодом этого потока.
- Не возвращает результат или выбрасывает проверяемое исключение.
Callable:
- Определен в пакете java.util.concurrent.
- Появился в Java 5 и представляет более мощную альтернативу Runnable.
- Подобно Runnable, он представляет задачу, которую можно выполнить параллельно.
- Отличие заключается в том, что Callable может возвращать результат и выбрасывать исключения.
- Имеет единственный метод V call() throws Exception, который возвращает значение типа V (обобщенный тип) и может выбрасывать исключения.
- Метод call() содержит код, который будет выполняться в отдельном потоке.
- Когда объект Callable передается в ExecutorService и запускается с помощью метода submit(), он возвращает объект Future, который представляет результат выполнения задачи.
- Объект Future позволяет получить результат выполнения задачи, проверить ее статус и отменить ее выполнение.
- Использование Runnable или Callable зависит от требуемой функциональности и потребностей вашего приложения. Если вам необходимо только выполнить некоторый код в параллельном потоке без возвращаемого значения или выбрасываемых исключений, то можно использовать Runnable. Если вам нужно получить результат выполнения задачи или обрабатывать исключения, то более подходящим будет использование Callable.
1065. Что такое FutureTask?
FutureTask - это класс в Java, который реализует интерфейсы Runnable и Future. Он представляет собой удобный способ выполнения асинхронных задач и получения их результатов.
FutureTask можно использовать для выполнения вычислений в отдельном потоке и получения результата в основном потоке, даже если вычисления еще не завершены.
Основные особенности FutureTask:
Он может быть создан на основе объекта, реализующего интерфейс Callable, или на основе объекта, реализующего интерфейс Runnable.
При создании объекта FutureTask передается экземпляр Callable или Runnable, который содержит код выполняемой задачи.
Задача может быть запущена при помощи метода run() или submit() (который наследуется из интерфейса Runnable).
Метод get() позволяет получить результат выполнения задачи. Если задача еще не завершилась, то данный вызов будет блокировать текущий поток до завершения задачи и возврата результата.
Методы isDone() и isCancelled() позволяют проверить состояние задачи. Метод cancel(boolean mayInterruptIfRunning) позволяет отменить выполнение задачи. Пример использования FutureTask:
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Main {
public static void main(String[] args) {
Callable<Integer> callableTask = () -> {
// Выполняем какие-то вычисления и возвращаем результат
Thread.sleep(2000);
return 42;
};
FutureTask<Integer> futureTask = new FutureTask<>(callableTask);
// Запускаем задачу в отдельном потоке
new Thread(futureTask).start();
System.out.println("Выполняется основная работа...");
try {
// Получаем результат выполнения задачи
Integer result = futureTask.get();
System.out.println("Результат: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
В этом примере FutureTask создается на основе Callable, выполняющего некоторые вычисления. После запуска задачи в отдельном потоке, основной поток продолжает свою работу. Затем метод get() вызывается для получения результата выполнения задачи. Если задача еще не завершилась, то текущий поток будет заблокирован до ее завершения.
1066. В чем заключаются различия между CyclicBarrier и CountDownLatch?
CyclicBarrier и CountDownLatch - это два разных механизма синхронизации, предоставляемые Java для координирования потоков. Оба класса позволяют одному или нескольким потокам ждать завершения определенного количества операций, прежде чем продолжить свое выполнение. Однако у них есть несколько ключевых различий:
Количество событий:
CountDownLatchориентирован на одноразовое ожидание фиксированного количества событий. После того, как заданное количество вызовов метода countDown() будет выполнено, все ожидающие потоки будут разблокированы.CyclicBarrierпозволяет повторно использовать барьер после каждого прохождения группы потоков через него. Выполняется сразу же после того, как заданное количество потоков вызовет метод await(), блокируя дальнейшее выполнение до достижения барьера.
Возможность ожидания:
CountDownLatchне предоставляет возможности переключиться в ожидающем потоке после вызова countDown(). Разблокированные потоки могут продолжить свое выполнение незамедлительно.CyclicBarrierпредоставляет дополнительную возможность для ожидающих потоков переключиться и выполнить некоторое действие, определенное в Runnable, перед тем как продолжить свое выполнение. Это может быть полезно для согласования состояния между потоками.
Участники:
CountDownLatchне имеет понятия об участниках. Оно просто ждет завершения фиксированного количества операций.CyclicBarrierожидает определенное количество участников (потоков), которые будут проходить через барьер и вызывать метод await().
Возможность сброса:
CountDownLatchне предоставляет метод для сброса состояния. Однажды достигнуто установленное количество событий, оно не может быть сброшено для повторного использования.- CyclicBarrier можно сбросить вызовом метода reset(). После сброса его можно использовать снова для ожидания новой группы потоков.
Использование CountDownLatch или CyclicBarrier следует выбирать в зависимости от конкретных требований вашего приложения.
1067. Что такое race condition?
Race condition (гонка условий) - это ситуация, возникающая в многопоточной среде, когда поведение программы зависит от того, в каком порядке выполняются операции или доступа к общему ресурсу нескольких потоков. В результате непредсказуемого выполнения операций может возникнуть конфликт и привести к неправильным результатам или некорректному состоянию программы.
Пример race condition можно представить с помощью следующего сценария: два потока одновременно пытаются увеличить значение переменной на 1. Первый поток читает значение переменной, затем второй поток также читает значение переменной, после чего оба потока увеличивают значение на 1 и записывают его обратно в переменную. Однако, так как оба потока выполняются параллельно, возможны следующие проблемы:
Проблема гонки на чтение-запись: Если оба потока считывают значение переменной одновременно, то каждый из них будет работать со своей копией значения, и при записи обратно в переменную одно из значений будет потеряно.
Проблема гонки на запись-запись: Если оба потока выполняют операцию увеличения значения одновременно, то они могут перезаписывать результаты друг друга, и в итоге переменная будет содержать некорректное значение.
Race condition может возникнуть при любых операциях, которые зависят от текущего или предыдущего состояния общего ресурса. Для предотвращения race condition необходимо использовать синхронизацию или механизмы блокировки, которые обеспечивают правильную синхронизацию доступа к общим ресурсам в многопоточной среде.
1068. Существует ли способ решения проблемы race condition?
Да, в Java существуют несколько способов предотвращения и решения проблемы race condition:
Синхронизация методов: Вы можете использовать ключевое слово synchronized для синхронизации методов, чтобы только один поток мог выполнить их в определенный момент времени. Например:
public synchronized void increment() {
// Код увеличения значения переменной
}
Синхронизация блоков кода: Вместо синхронизации целого метода вы также можете использовать блоки synchronized для синхронизации только нужных участков кода. Например:
public void increment() {
synchronized (this) {
// Код увеличения значения переменной
}
}
Использование ReentrantLock: Класс ReentrantLock из пакета java.util.concurrent.locks предоставляет более гибкий механизм блокировки, чем ключевое слово synchronized. Вы можете захватывать и освобождать блокировку явным образом в нужных участках кода. Пример использования:
import java.util.concurrent.locks.ReentrantLock;
private ReentrantLock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
// Код увеличения значения переменной
} finally {
lock.unlock();
}
}
Использование атомарных классов: Java предлагает набор атомарных классов, таких как AtomicInteger, которые обеспечивают атомарные операции чтения и записи без необходимости явной синхронизации. Например:
import java.util.concurrent.atomic.AtomicInteger;
private AtomicInteger counter = new AtomicInteger();
public void increment() {
counter.incrementAndGet();
}
Использование volatile переменных: Пометка переменной как volatile гарантирует, что ее изменения будут видны другим потокам без кэширования значения. Однако, это не решает все проблемы race condition и может быть ограничено определенными ситуациями использования.
Каждый из этих подходов имеет свои особенности и подходит для разных сценариев. Выбор конкретного способа зависит от требований вашего приложения и контекста использования.
1069. Как остановить поток?
В Java есть несколько способов остановить выполнение потока. Вот некоторые из них:
Использование метода interrupt(): Вы можете вызвать метод interrupt() на экземпляре потока, чтобы отправить ему запрос на прерывание. Поток может проверять свой статус на предмет прерывания и корректно завершить свою работу. Например:
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
// Код выполнения потока
}
});
// Прервать поток
thread.interrupt();
В вашем коде внутри потока регулярно проверяйте статус isInterrupted(), чтобы определить, должен ли поток завершиться.
Использование флага для контроля: Вы можете использовать флаговую переменную для управления выполнением потока. Этот флаг должен быть доступен из другого потока, который хочет остановить первый поток. Например:
private volatile boolean isRunning = true;
public void stopThread() {
isRunning = false;
}
public void run() {
while (isRunning) {
// Код выполнения потока
}
}
Метод stopThread() может быть вызван из другого места кода для изменения значения флага isRunning и остановки выполнения потока.
Использование метода stop(): Метод stop() класса Thread может быть использован для немедленного прерывания выполнения потока. Однако, этот метод считается устаревшим и не рекомендуется к использованию, так как он может оставить приложение в неконсистентном состоянии.
Важно отметить, что безопасное и корректное прерывание потока зависит от того, какой код выполняется внутри потока. Ваш код должен проверять статус прерывания или использовать другие механизмы синхронизации для правильного завершения работы и освобождения ресурсов перед остановкой.
1070. Почему не рекомендуется использовать метод Thread.stop()?
Метод Thread.stop() был объявлен устаревшим и не рекомендуется к использованию по нескольким причинам:
Небезопасное завершение потока: Метод stop() немедленно останавливает выполнение потока, не давая ему возможность корректно завершить свою работу. Он может быть вызван из другого потока и мгновенно "убить" целевой поток в любой точке его выполнения. Это может привести к непредсказуемым последствиям и оставить приложение в неконсистентном состоянии.
Потенциальные блокировки и утечка ресурсов: Если поток был остановлен в момент, когда он заблокирован на какой-либо операции (например, ожидание блокировки), то блокировка может остаться захваченной навсегда, что приведет к блокировке других частей кода или утечке ресурсов.
Нарушение консистентности данных: Если поток был остановлен в середине операции, это может привести к нарушению консистентности данных. Например, если поток останавливается в момент записи данных в файл или базу данных, то данные могут оказаться неполными или поврежденными.
Вместо метода stop() рекомендуется использовать более безопасные и контролируемые способы остановки потоков, такие как использование флагов для контроля выполнения или метода interrupt(), который позволяет отправить запрос на прерывание потока, а сам поток может корректно завершить свою работу. Это дает возможность потоку упорядоченно завершить свою работу и освободить ресурсы.
1071. Что происходит, когда в потоке выбрасывается исключение?
Когда исключение выбрасывается в потоке, происходит следующее:
Поток останавливается: Выброшенное исключение прекращает нормальное выполнение потока. Последующий код внутри метода или блока, где было выброшено исключение, не выполняется.
Стек вызовов разматывается: Когда исключение выбрасывается, стек вызовов (stack trace) потока разматывается. Это означает, что поток отслеживает последовательность методов, которые вызывались до момента выброса исключения. Таким образом, информация о вызове методов и сведения об исключении сохраняются для дальнейшего анализа и отладки.
Исключение передается вверх по стеку вызовов: Если исключение не обрабатывается внутри текущего метода или блока, оно передается вверх по стеку вызовов. Это означает, что исключение может быть перехвачено и обработано в более высоких уровнях вызова.
Прекращение выполнения потока: Если исключение не обрабатывается во всей цепочке вызовов, то в конечном итоге оно может достигнуть верхнего уровня потока (такого как метод run() в классе Thread). В этом случае, по умолчанию, исключение будет выведено на консоль, и выполнение потока будет прекращено.
Обработка исключений в потоках важна для обеспечения безопасности и корректности выполнения программы. Исключения могут быть перехвачены и обработаны с помощью блоков try-catch, что позволяет предотвратить нежелательные последствия выброса исключения и продолжить выполнение программы.
1072. В чем разница между interrupted() и isInterrupted()?
В Java существуют два метода для работы с прерыванием потоков: interrupted() и isInterrupted(). Вот их различия:
interrupted(): Это статический метод класса Thread, который проверяет, был ли текущий поток прерван, и сбрасывает флаг прерывания. Если метод возвращает true, это означает, что на текущий поток был вызван метод interrupt() и флаг прерывания был установлен. После возвращения true, флаг прерывания сбрасывается, чтобы следующий вызов interrupted() вернул false. Если метод возвращает false, это может означать, что либо поток не был прерван, либо флаг прерывания уже был сброшен.
isInterrupted(): Это метод экземпляра класса Thread, который проверяет, был ли текущий поток прерван, но не изменяет флаг прерывания. Он возвращает true, если флаг прерывания установлен, и false, если флаг прерывания не установлен. Вызов isInterrupted() не сбрасывает флаг прерывания, поэтому последующие вызовы будут возвращать тот же результат.
Важно отметить, что interrupted() является статическим методом, вызываемым на классе Thread, а isInterrupted() является методом объекта потока.
Пример использования:
Thread thread = new Thread(() -> {
while (!Thread.interrupted()) {
// Выполнение работы
}
});
// Прерывание потока
thread.interrupt();
// Проверка флага прерывания
boolean interrupted = Thread.interrupted(); // Возвращает true и сбрасывает флаг прерывания
boolean isInterrupted = thread.isInterrupted(); // Возвращает true без изменения флага прерывания
В общем случае, isInterrupted() обычно предпочтительнее, так как он не изменяет состояние флага прерывания, позволяя более точно контролировать работу потока. Однако, выбор между ними зависит от конкретных требований вашего кода и контекста использования.
1073. Что такое «пул потоков»?
Пул потоков (thread pool) в Java - это механизм, который позволяет эффективно управлять и переиспользовать потоки для выполнения задач. Он представляет собой пул заранее созданных потоков, готовых к выполнению задач.
Вместо создания нового потока каждый раз, когда требуется выполнить задачу, пул потоков предоставляет готовые потоки из пула. Задача передается одному из свободных потоков для выполнения. После завершения задачи поток возвращается обратно в пул и может быть использован для выполнения следующей задачи.
Преимущества использования пула потоков:
Управление ресурсами: Пул потоков позволяет контролировать количество одновременно работающих потоков. Это полезно для предотвращения создания большого количества потоков и перегрузки системы.
Повторное использование потоков: Вместо создания нового потока для каждой задачи, пул потоков повторно использует уже существующие потоки. Это уменьшает накладные расходы на создание и уничтожение потоков, что может повысить производительность.
Ограничение очереди задач: Пул потоков может иметь ограничение на количество задач, которые могут быть поставлены в очередь для выполнения. Это помогает избежать превышения памяти или перегрузки системы, когда задачи накапливаются быстрее, чем они могут быть обработаны.
Java предоставляет встроенную реализацию пула потоков с помощью класса ExecutorService. Этот класс предоставляет методы для выполнения задач в пуле потоков, управления жизненным циклом пула и получения результатов выполнения задач.
Пример создания и использования пула потоков с использованием ExecutorService:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExample {
public static void main(String[] args) {
// Создание пула потоков с фиксированным размером (3 потока)
ExecutorService executor = Executors.newFixedThreadPool(3);
// Постановка задач в очередь для выполнения
for (int i = 0; i < 10; i++) {
final int taskId = i;
executor.execute(() -> {
System.out.println("Task " + taskId + " is being executed by " + Thread.currentThread().getName());
// Выполнение задачи
});
}
// Завершение работы пула потоков
executor.shutdown();
}
}
В этом примере создается пул потоков с фиксированным размером, содержащий 3 потока. Затем 10 задач поставляются в очередь для выполнения. Каждая задача выполняется одним из доступных потоков пула. После завершения всех задач метод shutdown() вызывается для корректного завершения работы пула потоков.
Пулы потоков являются мощным инструментом для управления и распределения выполнения задач в многопоточных приложениях, позволяя достичь более эффективной обработки задач и оптимального использования ресурсов системы.
1074. Какого размера должен быть пул потоков?
Размер пула потоков в Java зависит от конкретных требований и характеристик вашего приложения. Нет одного универсального размера пула, который подходил бы для всех случаев. Оптимальный размер пула потоков может быть определен на основе следующих факторов:
Тип задач: Размер пула потоков может зависеть от типа задач, которые вы планируете выполнять. Если ваши задачи являются CPU-интенсивными, то количество потоков может быть примерно равно количеству доступных процессорных ядер на системе. Для I/O-интенсивных задач, таких как чтение/запись из сети или базы данных, можно использовать больший размер пула, поскольку потоки не будут активно использовать CPU.
Ресурсы системы: Размер пула потоков должен соответствовать ресурсам вашей системы. Слишком большой размер пула может привести к перегрузке системы, из-за чего возникнет избыточное потребление памяти и контекстных переключений между потоками. С другой стороны, слишком маленький пул может не использовать полностью доступные ресурсы системы и не обеспечить достаточную пропускную способность выполнения задач.
Производительность: Размер пула потоков может быть настроен на основе требуемой производительности вашего приложения. Вы можете экспериментировать с разными размерами пула и измерять производительность, чтобы найти оптимальное значение. Увеличение размера пула потоков может увеличить параллелизм и ускорить обработку задач до некоторого предела, после чего дополнительное увеличение размера пула может не привести к значимому улучшению производительности.
Ограничения ресурсов: Ваше приложение может ограничивать доступные ресурсы для пула потоков. Например, вы можете иметь ограниченный объем памяти или максимальное количество одновременно работающих потоков. Размер пула должен быть настроен в соответствии с этими ограничениями.
Важно помнить, что создание слишком большого пула потоков может привести к избыточному потреблению ресурсов и ухудшению производительности, в то время как слишком маленький пул может ограничивать пропускную способность и эффективность выполнения задач. Рекомендуется проводить тестирование и настройку размера пула потоков для оптимальной производительности вашего приложения в конкретном сценарии использования.
1075. Что будет, если очередь пула потоков уже заполнена, но подаётся новая задача?
Если очередь пула потоков уже заполнена, и подается новая задача, то в зависимости от настроек пула потоков может произойти одно из следующих:
Поток будет заблокирован: Некоторые реализации пула потоков могут блокировать поток, который подает задачу, пока не освободится место в очереди. Это может привести к блокировке вызывающего потока до тех пор, пока задача не будет принята к выполнению в пуле потоков.
Исключение будет сгенерировано: Другие реализации пула потоков могут выбрасывать исключение или возвращать ошибку, когда очередь пула потоков полностью заполнена. В этом случае вызывающий код должен обрабатывать это исключение и принять соответствующие меры (например, повторить попытку позже или применить альтернативные стратегии выполнения задачи).
Задача будет отклонена: Некоторые пулы потоков могут иметь стратегию отклонения задач, которая будет применяться, когда очередь заполнена. В этом случае новая задача может быть отклонена и не выполнена.
Какой именно сценарий будет применяться, зависит от конкретной реализации пула потоков и настроек, которые вы задали. При выборе или настройке пула потоков важно учесть возможные последствия переполнения очереди и обработки новых задач, чтобы избежать блокировок, ошибок или потери задач.
1076. В чём заключается различие между методами submit() и execute() у пула потоков?
В Java пул потоков предоставляет два основных метода для отправки задач на выполнение: submit() и execute(). Вот их основные различия:
Возвращаемое значение: Метод submit() возвращает объект типа Future, который представляет собой результат выполнения задачи или позволяет управлять ее состоянием и получать результаты в будущем. С другой стороны, метод execute() не возвращает никакого значения.
Обработка исключений: При использовании метода submit() исключения, возникающие во время выполнения задачи, обернуты в объект Future. Вы можете явно обрабатывать исключения, получая их из объекта Future при вызове get(). В случае метода execute(), исключения, возникающие внутри задачи, будут перехвачены пулом потоков и переданы в обработчик необработанных исключений (UncaughtExceptionHandler), если он был установлен.
Расширенные возможности Future: Метод submit() возвращает объект Future, который предоставляет дополнительные возможности для управления задачей. Вы можете проверять состояние задачи, отменять ее выполнение, ожидать завершения и получать результаты. Метод execute() выполняет задачу без предоставления таких возможностей.
В большинстве случаев рекомендуется использовать метод submit(), поскольку он предоставляет более гибкий и мощный интерфейс для управления задачами в пуле потоков. Однако, если вам не требуется получать результаты задачи или управлять ее выполнением, то можно использовать метод execute() для более простого и краткого вызова.
1077. В чем заключаются различия между cтеком (stack) и кучей (heap) с точки зрения многопоточности?
Стек (stack) и куча (heap) - это две области памяти, используемые в программировании, в том числе при работе с многопоточностью. Вот основные различия между стеком и кучей с точки зрения многопоточности:
Организация памяти: Стек - это локальная область памяти, связанная непосредственно с каждым потоком. Каждый поток имеет свой отдельный стек, который содержит данные, связанные с вызовами функций, локальными переменными и контекстом выполнения потока. Куча - это общая область памяти, доступная для всех потоков. Она содержит глобальные и динамически выделенные объекты.
Распределение памяти: Выделение и освобождение памяти в стеке является автоматическим и происходит по мере входа и выхода из функций. При создании потока ему выделяется фиксированный размер стека. В куче распределение памяти является более гибким и может быть управляемым программистом с помощью операций выделения и освобождения памяти, таких как создание и удаление объектов.
Скорость доступа: Доступ к стеку является быстрым, поскольку каждый поток имеет свой собственный стек и доступ осуществляется непосредственно. Доступ к куче может быть медленнее, поскольку объекты в куче распределены динамически и могут быть разрозненными в памяти.
Потоковая безопасность: Каждый поток имеет свой собственный стек, что делает его потоково безопасным. Каждый поток имеет доступ только к своему собственному стеку и не может изменять данные других потоков напрямую. Куча, с другой стороны, является общей для всех потоков, и доступ к объектам в куче должен быть синхронизирован для предотвращения гонок данных и проблем многопоточности.
В целом, стек и куча имеют разные цели и области применения в многопоточных приложениях. Стек используется для хранения локальных данных и контекста выполнения потока, в то время как куча используется для распределения глобальных и динамических объектов между потоками.
1078. Как поделиться данными между двумя потоками?
В Java существует несколько способов поделиться данными между двумя потоками. Вот некоторые из распространенных подходов:
Синхронизированный метод или блок: Вы можете использовать ключевое слово synchronized для обеспечения синхронизации доступа к общим данным. Это позволит только одному потоку одновременно выполнять код в синхронизированном блоке или методе.
// Объект, содержащий общие данные
class SharedData {
private int sharedVariable;
public synchronized void setSharedVariable(int value) {
this.sharedVariable = value;
}
public synchronized int getSharedVariable() {
return sharedVariable;
}
}
// Использование общих данных в двух потоках
SharedData sharedData = new SharedData();
// Поток 1
Thread thread1 = new Thread(() -> {
sharedData.setSharedVariable(10);
});
// Поток 2
Thread thread2 = new Thread(() -> {
int value = sharedData.getSharedVariable();
System.out.println(value);
});
Использование классов из пакета java.util.concurrent: Java предоставляет различные классы и интерфейсы в пакете java.util.concurrent, которые облегчают синхронизацию и обмен данными между потоками. Например, Lock, Condition, Semaphore, CountDownLatch и другие. Эти классы предоставляют более гибкую синхронизацию и управление потоками.
Использование пайпов (Pipe): Пайпы могут использоваться для обмена данными между двумя потоками. Один поток записывает данные в пайп (PipedOutputStream), а другой поток читает данные из него (PipedInputStream). Пайпы позволяют передавать данные в одном направлении, поэтому требуется создание двух экземпляров пайпа для двунаправленного обмена данными.
// Создание пайпа
PipedOutputStream outputStream = new PipedOutputStream();
PipedInputStream inputStream = new PipedInputStream(outputStream);
// Поток записи в пайп
Thread writerThread = new Thread(() -> {
try {
outputStream.write(10);
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
});
// Поток чтения из пайпа
Thread readerThread = new Thread(() -> {
try {
int value = inputStream.read();
System.out.println(value);
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
});
Использование блокирующей очереди (Blocking Queue): Вы можете создать блокирующую очередь (BlockingQueue) и использовать ее для передачи данных между потоками. Одни потоки могут помещать данные в очередь, а другие потоки могут извлекать данные из нее. Блокирующая очередь автоматически управляет синхронизацией и блокировкой при доступе к данным.
// Создание блокирующей очереди
BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(10);
// Поток записи в очередь
Thread writerThread = new Thread(() -> {
try {
queue.put(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// Поток чтения из очереди
Thread readerThread = new Thread(() -> {
try {
int value = queue.take();
System.out.println(value);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Это лишь некоторые из возможных способов поделиться данными между потоками в Java. Какой метод выбрать зависит от конкретной задачи и требований вашего приложения.
1079. Какой параметр запуска JVM используется для контроля размера стека потока?
В JVM (Java Virtual Machine) для контроля размера стека потока используется параметр запуска -Xss. Этот параметр позволяет указать размер стека потока в байтах или килобайтах.
Синтаксис использования параметра -Xss следующий:
-Xss<size>
где <size> представляет собой размер стека потока. Размер можно задать числом с последующим указанием единицы измерения, например:
k или K - килобайты m или M - мегабайты Например, чтобы установить размер стека потока в 512 килобайт, вы можете использовать следующую опцию:
-Xss512k
По умолчанию размер стека потока может быть разным для разных операционных систем и JVM-реализаций. Обычно он составляет несколько мегабайт. Однако, если ваше приложение требует большего размера стека, вы можете изменить его, используя параметр -Xss.
Важно отметить, что изменение размера стека потока может повлиять на производительность и использование ресурсов системы, поэтому рекомендуется тщательно настраивать этот параметр, основываясь на требованиях вашего приложения.
1080. Как получить дамп потока?
В Java вы можете получить дамп потока (thread dump) с помощью стандартных инструментов, таких как утилита jstack или команда jcmd.
С использованием утилиты jstack:
Откройте командную строку или терминал.
Запустите утилиту jstack и передайте идентификатор процесса Java вашего приложения. Например:
jstack <pid>
Подождите некоторое время, пока утилита соберет информацию о потоках.
Результат будет выведен в командной строке или терминале.
С использованием команды jcmd:
Откройте командную строку или терминал.
Запустите команду jcmd и передайте идентификатор процесса Java вашего приложения, а затем ключ Thread.print. Например:
jcmd <pid> Thread.print
Подождите некоторое время, пока команда соберет информацию о потоках.
Результат будет выведен в командной строке или терминале.
Обратите внимание, что <pid> должен быть заменен на фактический идентификатор процесса Java вашего приложения. Вы можете найти идентификатор процесса, запустив команду jps или используя инструменты мониторинга процессов вашей операционной системы.
Полученный дамп потока содержит информацию о каждом потоке в вашем приложении, включая его состояние, стек вызовов и блокировки. Это может быть полезно для анализа производительности, выявления проблем с блокировками или поиска узких мест в вашем коде.
1081. Что такое ThreadLocal-переменная?
ThreadLocal-переменная в Java представляет собой особый тип переменной, который позволяет каждому потоку иметь свою собственную копию значения переменной. Другими словами, каждый поток будет иметь доступ только к своей индивидуальной версии переменной, сохраненной в ThreadLocal-объекте.
ThreadLocal-переменные полезны в многопоточных приложениях, где несколько потоков работают с общими ресурсами, но требуется изолировать значения этих ресурсов для каждого потока. Каждый поток может установить свое собственное значение в ThreadLocal-переменной, и эти значения будут независимыми для каждого потока.
Пример использования ThreadLocal-переменной:
public class MyRunnable implements Runnable {
private static ThreadLocal<Integer> threadLocal = new ThreadLocal<>();
@Override
public void run() {
// Установка значения ThreadLocal-переменной для текущего потока
threadLocal.set((int) (Math.random() * 100));
// Получение значения ThreadLocal-переменной для текущего потока
int value = threadLocal.get();
System.out.println("Значение ThreadLocal-переменной для потока " + Thread.currentThread().getId() + ": " + value);
// Очистка ThreadLocal-переменной для текущего потока
threadLocal.remove();
}
}
public class Main {
public static void main(String[] args) {
MyRunnable runnable = new MyRunnable();
// Создание и запуск нескольких потоков
Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(runnable);
thread1.start();
thread2.start();
}
}
В этом примере каждый поток устанавливает случайное значение в ThreadLocal-переменной threadLocal и выводит его на консоль. Значения, установленные в переменной threadLocal, независимы для каждого потока, и каждый поток может получить только свое собственное значение.
ThreadLocal-переменные также могут быть полезны при передаче контекста или состояния между различными компонентами внутри одного потока, например, приложений, основанных на обработке запросов.
1082. Назовите различия между synchronized и ReentrantLock?
Ниже перечислены некоторые различия между synchronized и ReentrantLock в Java:
Гибкость использования: ReentrantLock предоставляет более гибкий способ управления блокировками в сравнении с synchronized. Он обеспечивает возможность использования нескольких условных переменных, попыток получить блокировку с таймаутом и прерываниями, что делает его более мощным инструментом для управления потоками.
synchronized, с другой стороны, предоставляет простой и удобный способ синхронизации методов или блоков, но не поддерживает дополнительные функции, такие как условные переменные.
Возможность захвата нескольких блокировок: ReentrantLock позволяет потоку захватывать несколько блокировок одновременно, что может быть полезно в некоторых сценариях синхронизации. С synchronized можно использовать только один монитор за раз.
Поддержка справедливости: ReentrantLock может работать в режиме "справедливой" блокировки, где блокировка будет предоставлена самому долго ожидающему потоку. Это помогает избежать проблемы "голодания" (starvation), когда некоторые потоки постоянно вытесняются другими. В synchronized нет встроенной поддержки справедливости.
Улучшенная производительность: В некоторых случаях использование ReentrantLock может дать лучшую производительность по сравнению с synchronized. Однако это зависит от конкретных условий и оптимизаций JVM, поэтому результаты могут варьироваться.
Управление блокировкой: ReentrantLock предоставляет более точный контроль над блокировкой благодаря методам like lock(), unlock(), tryLock() и т.д., которые могут быть полезными в сложных сценариях синхронизации. synchronized обрабатывается автоматически JVM, и у нас меньше возможностей для явного контроля.
Оба synchronized и ReentrantLock являются инструментами синхронизации в Java, и выбор между ними зависит от конкретных требований и сценариев приложения.
1083. Что такое ReadWriteLock?
ReadWriteLock - это интерфейс в Java, который предоставляет механизм блокировки для чтения и записи данных. Он позволяет оптимизировать доступ к общим данным в случаях, когда доступ на чтение является более частым, чем доступ на запись.
ReadWriteLock имеет два основных метода: readLock() и writeLock().
Метод readLock() возвращает экземпляр Lock, который используется для блокировки доступа на чтение к данным. Множество потоков может одновременно получить доступ на чтение, если другой поток не блокирует доступ на запись.
Метод writeLock() возвращает экземпляр Lock, который используется для блокировки доступа на запись к данным. Только один поток может удерживать блокировку на запись, и при этом все остальные потоки будут заблокированы в ожидании окончания записи.
Пример использования ReadWriteLock:
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class Example {
private final ReadWriteLock lock = new ReentrantReadWriteLock();
private int data;
public void readData() {
lock.readLock().lock();
try {
// Чтение данных из переменной data
} finally {
lock.readLock().unlock();
}
}
public void writeData() {
lock.writeLock().lock();
try {
// Запись данных в переменную data
} finally {
lock.writeLock().unlock();
}
}
}
В этом примере ReadWriteLock используется для синхронизации доступа к переменной data. Метод readData() блокирует доступ на чтение, позволяя нескольким потокам одновременно читать данные. Метод writeData() блокирует доступ на запись, позволяя только одному потоку выполнять запись данных.
Использование ReadWriteLock может улучшить производительность в приложениях, где доступ на чтение является доминирующей операцией, и конкурентный доступ на запись редкость.
1084. Что такое «блокирующий метод»?
В Java термин "блокирующий метод" относится к методу, который временно останавливает выполнение текущего потока до завершения определенного условия или операции. Это означает, что при вызове блокирующего метода, выполнение текущего потока будет приостановлено до выполнения определенных условий или завершения операции, после чего поток продолжит свою работу.
Блокирующие методы являются основными элементами в многопоточном программировании и используются для синхронизации работы потоков или для ожидания определенных условий. Они часто связаны с мониторами, блокировками и другими конструкциями синхронизации.
Например, в классе Object в Java есть несколько блокирующих методов, таких как wait(), notify() и notifyAll(). Метод wait() используется для приостановки выполнения текущего потока до тех пор, пока другой поток не вызовет метод notify() или notifyAll() на том же объекте. Эти методы широко используются для реализации механизмов синхронизации и сигнализации между потоками.
Когда поток вызывает блокирующий метод, он может быть приостановлен до тех пор, пока не будет выполнено определенное условие или завершена операция. Во время блокировки поток может ожидать ресурсов, получения данных, завершения операций ввода-вывода и других событий. Когда условие становится истинным или операция завершается, поток разблокируется и продолжает свое выполнение.
Однако при использовании блокирующих методов следует быть осторожным, чтобы избежать возможных проблем, таких как дедлоки (deadlock) или голодание потоков (starvation). Правильное использование блокирующих методов и правильная организация синхронизации между потоками являются важными аспектами при разработке многопоточных приложений на Java.
1085. Что такое «фреймворк Fork/Join»?
Фреймворк Fork/Join (разделение/объединение) - это механизм параллельного выполнения задач в Java, предоставляемый пакетом java.util.concurrent начиная с версии Java 7. Он представляет собой абстракцию для управления задачами, которые могут быть разделены на более мелкие подзадачи и объединены в результат.
Фреймворк Fork/Join основан на модели "работник-потребитель" (worker-consumer), где задачи рекурсивно разделяются на подзадачи до тех пор, пока они не станут достаточно маленькими для непосредственного выполнения. Затем результаты подзадач объединяются, чтобы получить окончательный результат.
Основные компоненты фреймворка Fork/Join:
Разделение (Fork): Задача разделяется на более мелкие подзадачи. Это происходит путем создания новых экземпляров задачи и добавления их в рабочую очередь (work queue) для дальнейшего выполнения.
Выполнение (Execute): Подзадачи выполняются независимо друг от друга. Каждая подзадача может быть выполнена в отдельном потоке или использовать имеющиеся потоки в пуле потоков.
Объединение (Join): Результаты выполнения подзадач объединяются, чтобы получить окончательный результат. Обычно это делается путем комбинирования (например, сложения или конкатенации) результатов подзадач.
Фреймворк Fork/Join предоставляет класс ForkJoinTask в качестве базового класса для задач и класс ForkJoinPool для управления пулом потоков исполнителей. Он также предоставляет методы для разделения задач, проверки доступности рабочих потоков и объединения результатов.
Фреймворк Fork/Join полезен для параллельного выполнения рекурсивных алгоритмов, таких как сортировка слиянием (merge sort), обход деревьев, генерация фракталов и других задач, которые могут быть эффективно разделены на подзадачи. Он обеспечивает автоматическое управление потоками и балансировку нагрузки, что помогает достичь лучшей производительности при параллельном выполнении задач.
1086. Что такое Semaphore?
В Java Semaphore (семафор) - это средство синхронизации, которое позволяет контролировать доступ к ресурсам в многопоточной среде. Он представляет собой счетчик, который может быть использован для ограничения количества потоков, имеющих доступ к определенному ресурсу или критической секции.
Семафор поддерживает две основные операции:
acquire(): Если значение счетчика семафора больше нуля, поток продолжает выполнение и значение счетчика уменьшается на единицу. Если значение счетчика равно нулю, поток блокируется до тех пор, пока другой поток не освободит ресурс и увеличит значение счетчика.
release(): Поток освобождает ресурс и увеличивает значение счетчика на единицу. Если есть потоки, ожидающие доступа к ресурсу, один из них получит доступ.
Семафор может быть создан с начальным значением счетчика, которое указывает на количество доступных ресурсов. Значение счетчика может изменяться динамически в процессе выполнения программы.
Semaphore часто используется для ограничения числа потоков, которые могут выполнять определенную операцию или получать доступ к ресурсам с ограниченной пропускной способностью, таким как базы данных, пулы соединений или ограниченное количество разрешений на выполнение определенных задач.
Пример использования Semaphore:
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
private static final int MAX_THREADS = 5;
private static final Semaphore semaphore = new Semaphore(MAX_THREADS);
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(new WorkerThread());
thread.start();
}
}
static class WorkerThread implements Runnable {
@Override
public void run() {
try {
// Acquire the semaphore
semaphore.acquire();
// Access the shared resource or perform an operation
System.out.println("Thread " + Thread.currentThread().getId() + " is accessing the resource.");
Thread.sleep(2000); // Simulate some work
// Release the semaphore
semaphore.release();
System.out.println("Thread " + Thread.currentThread().getId() + " has released the resource.");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
В приведенном выше примере создается Semaphore с максимальным числом потоков равным 5. Каждый поток запрашивает доступ к ресурсу с помощью acquire() перед выполнением работы и освобождает ресурс с помощью release() после завершения. Если все 5 потоков уже заняли ресурсы, следующие потоки будут ожидать освобождения ресурса другими потоками.
1087. Что такое double checked locking Singleton?
Double Checked Locking Singleton (синглтон с двойной проверкой блокировки) - это особый подход к созданию синглтона в Java, который обеспечивает ленивую инициализацию объекта с возможностью синхронизации при многопоточном доступе.
Основная идея double checked locking singleton заключается в использовании блока синхронизации только для первого доступа к созданию экземпляра синглтона. После этого блокировка не применяется, чтобы избежать накладных расходов на синхронизацию для каждого последующего доступа к синглтону.
Пример реализации Double Checked Locking Singleton:
public class DoubleCheckedLockingSingleton {
private static volatile DoubleCheckedLockingSingleton instance;
private DoubleCheckedLockingSingleton() {
// Приватный конструктор
}
public static DoubleCheckedLockingSingleton getInstance() {
if (instance == null) { // Первая проверка без синхронизации
synchronized (DoubleCheckedLockingSingleton.class) {
if (instance == null) { // Вторая проверка с синхронизацией
instance = new DoubleCheckedLockingSingleton();
}
}
}
return instance;
}
}
В этом примере переменная instance объявлена как volatile, что гарантирует видимость изменений переменной между потоками. Первая проверка instance == null выполняется без синхронизации для обеспечения более высокой производительности. Если объект уже создан и переменная instance не является null, блокировка не требуется.
Однако, при первом доступе к синглтону, когда instance == null, поток входит в синхронизированный блок для создания экземпляра синглтона. Это позволяет только одному потоку получить доступ к этому блоку, а остальные потоки будут ожидать вне блока. После создания экземпляра instance, остальные потоки, которые ожидали за пределами синхронизированного блока, больше не требуют блокировки.
Double checked locking singleton обеспечивает ленивую инициализацию объекта синглтона и хорошую производительность при многопоточном доступе. Однако, его реализация может быть сложной и подвержена ошибкам, связанным с порядком инициализации и видимостью изменений переменных между потоками. С появлением Java 5 и последующих версий, предпочтительным способом создания синглтона стал использование статического вложенного класса (static nested class) или перечисления (enum) вместо double checked locking singleton.
1088. Как создать потокобезопасный Singleton?
Создание потокобезопасного синглтона в Java можно осуществить с использованием различных подходов. Вот несколько способов:
Используя synchronized метод getInstance():
public class ThreadSafeSingleton {
private static ThreadSafeSingleton instance;
private ThreadSafeSingleton() {
// Приватный конструктор
}
public static synchronized ThreadSafeSingleton getInstance() {
if (instance == null) {
instance = new ThreadSafeSingleton();
}
return instance;
}
}
В этом примере метод getInstance() объявлен как synchronized, что гарантирует, что только один поток может выполнить его одновременно. Однако, этот подход может вызывать некоторые накладные расходы на производительность из-за блокировки всего метода при каждом доступе к синглтону.
Используя synchronized блок внутри метода getInstance():
public class ThreadSafeSingleton {
private static ThreadSafeSingleton instance;
private ThreadSafeSingleton() {
// Приватный конструктор
}
public static ThreadSafeSingleton getInstance() {
if (instance == null) {
synchronized (ThreadSafeSingleton.class) {
if (instance == null) {
instance = new ThreadSafeSingleton();
}
}
}
return instance;
}
}
В этом подходе используется double checked locking, который обеспечивает ленивую инициализацию синглтона без синхронизации при каждом доступе. Однако, реализация double checked locking может быть сложной и подвержена ошибкам.
Используя статический вложенный класс (static nested class):
public class ThreadSafeSingleton {
private ThreadSafeSingleton() {
// Приватный конструктор
}
private static class SingletonHelper {
private static final ThreadSafeSingleton instance = new ThreadSafeSingleton();
}
public static ThreadSafeSingleton getInstance() {
return SingletonHelper.instance;
}
}
В этом подходе экземпляр синглтона создается при загрузке класса SingletonHelper, что гарантирует потокобезопасность. Это основано на механизме инициализации статических полей в Java.
Используя перечисление (enum):
public enum ThreadSafeSingleton {
INSTANCE;
// Дополнительные поля и методы
public void doSomething() {
// Реализация
}
}
В этом подходе синглтон создается автоматически при загрузке перечисления и гарантируется его уникальность и потокобезопасность.
Выбор конкретного подхода зависит от требований и контекста вашего приложения. Важно помнить, что потокобезопасность синглтона - это только один из аспектов, которые следует учитывать при разработке.
1089. Чем полезны неизменяемые объекты?
Неизменяемые объекты в Java имеют несколько преимуществ и могут быть полезными в различных ситуациях. Вот некоторые преимущества неизменяемых объектов:
Потокобезопасность: Неизменяемые объекты являются потокобезопасными, поскольку они не могут быть изменены после создания. Это устраняет необходимость в синхронизации при доступе к объекту из разных потоков, что может повысить производительность и упростить разработку многопоточных приложений.
Безопасность: Так как неизменяемые объекты не могут быть изменены после создания, это обеспечивает защиту от ошибочного или злонамеренного изменения данных. Неизменяемые объекты особенно полезны в контексте безопасности, например, при работе с паролями, ключами шифрования и другой конфиденциальной информацией.
Кеш-френдли: Неизменяемые объекты могут быть использованы в качестве ключей в кэширующих структурах данных, таких как HashMap или HashSet. Поскольку эти объекты не могут изменить свое состояние, их хеш-значение остается неизменным, что позволяет эффективно использовать их в качестве ключей.
Устойчивость к ошибкам: Неизменяемые объекты помогают предотвратить ошибки, связанные с изменением объектов в непредсказуемых местах кода. Поскольку неизменяемые объекты гарантированно не изменятся, это может упростить отладку и повысить надежность программы.
Потенциальная оптимизация: Некоторые операции над неизменяемыми объектами могут быть более эффективными, чем операции над изменяемыми объектами. Например, копирование неизменяемого объекта может быть просто выполнено путем передачи ссылки на него, тогда как копирование изменяемого объекта может потребовать полного копирования всех его данных.
Несмотря на все преимущества неизменяемых объектов, важно заметить, что они также имеют ограничения. Например, при каждом изменении неизменяемого объекта требуется создание нового объекта, что может потребовать дополнительных ресурсов. Поэтому, выбор между изменяемыми и неизменяемыми объектами должен основываться на конкретных требованиях и контексте вашего приложения.
1090. Что такое busy spin?
Busy spin (занятое ожидание) — это техника синхронизации, при которой поток активно повторяет цикл ожидания до выполнения определенного условия, вместо блокировки или перевода потока в режим ожидания. В Java такую технику можно реализовать с использованием цикла while.
В контексте многопоточной программы, когда один поток ждет завершения выполнения другого потока, можно использовать busy spin для активного ожидания без переключения контекста между потоками. Вместо того, чтобы вызывать методы, такие как wait() или sleep(), поток повторяет короткую инструкцию или цикл, проверяя условие, пока не будет выполнено.
Пример кода с busy spin может выглядеть следующим образом:
while (!condition) {
// Повторять цикл, пока условие не будет выполнено
}
При использовании busy spin необходимо быть осторожным, особенно в случаях, когда ожидание может занимать значительное количество времени и потреблять процессорные ресурсы. Busy spin может быть эффективен в некоторых случаях, если время ожидания очень короткое и высокая скорость отклика является критическим требованием.
Однако в большинстве случаев предпочтительно использовать другие механизмы синхронизации, такие как блокировки (lock) или условные переменные (condition variables), чтобы потоки могли перейти в режим ожидания и освободить процессорные ресурсы до того, как определенное условие будет выполнено.
1091. Перечислите принципы, которым вы следуете в многопоточном программировании?
В многопоточном программировании существует несколько принципов, которым можно следовать для создания безопасных и эффективных многопоточных приложений. Вот некоторые из них:
Правильная синхронизация: Обеспечьте правильную синхронизацию доступа к общим данным или ресурсам во избежание состояния гонки (race conditions) или других ошибок синхронизации. Используйте механизмы синхронизации, такие как блокировки (lock), мониторы или атомарные операции, чтобы координировать доступ нескольких потоков к разделяемым данным.
Потокобезопасность: Разработайте код таким образом, чтобы он был потокобезопасным. Это означает, что ваш код должен работать корректно при одновременном доступе нескольких потоков к нему. Избегайте гонок данных и других потенциальных конфликтов между потоками.
Использование подходящих структур данных: Выбирайте подходящие структуры данных для задач многопоточного программирования. Некоторые структуры данных, такие как блокирующие очереди (blocking queues) или конкурентные коллекции (concurrent collections), уже встроены в Java и обеспечивают безопасный доступ к данным из нескольких потоков.
Избегание ненужной блокировки: Старайтесь минимизировать использование блокировок, особенно глобальных блокировок, чтобы избежать ситуаций, когда один поток блокирует другие, что может привести к снижению производительности или даже возникновению deadlock'ов. Рассмотрите возможность использования более легковесных механизмов синхронизации, таких как CAS-операции или условные переменные (condition variables).
Управление ресурсами: Обратите внимание на правильное управление ресурсами в многопоточном окружении. Например, убедитесь, что потоки корректно освобождают ресурсы после завершения своей работы, чтобы избежать утечек памяти или других проблем с ресурсами.
Тестирование и отладка: Проводите тщательное тестирование своего многопоточного кода, проверяя его работу при различных условиях и нагрузках. Используйте инструменты для анализа и отладки, чтобы выявить потенциальные проблемы, такие как состояния гонок или deadlock'ы.
Разделение задач: Разбейте задачи на более мелкие и независимые подзадачи, которые можно выполнять параллельно. Это поможет увеличить уровень параллелизма в вашем приложении и повысить его производительность.
Избегание гонок данных: Анализируйте код и идентифицируйте места, где возможны гонки данных. Используйте правильные механизмы синхронизации (например, блокировки) или структуры данных (например, атомарные типы данных), чтобы обеспечить согласованность данных и избежать гонок.
Обработка исключений: Учитесь корректно обрабатывать исключения в многопоточном окружении. Правильная обработка исключений может помочь избежать неконтролируемого завершения потоков и предотвратить утечки ресурсов.
Это лишь несколько принципов, которыми следует руководствоваться в многопоточном программировании. Важно понимать основные концепции и принципы работы с потоками, а также постоянно развивать свои знания и навыки в этой области.
1092. Какое из следующих утверждений о потоках неверно?
1093. Даны 3 потока Т1, Т2 и Т3? Как реализовать выполнение в последовательности Т1, Т2, Т3?
В Java можно использовать механизмы синхронизации, такие как методы wait() и notify(), чтобы реализовать выполнение потоков в заданной последовательности. Вот пример кода, демонстрирующий это:
public class SequenceExecution {
private static final Object lock = new Object();
private static int currentThread = 1;
public static void main(String[] args) {
Thread t1 = new Thread(new Task("T1", 1));
Thread t2 = new Thread(new Task("T2", 2));
Thread t3 = new Thread(new Task("T3", 3));
t1.start();
t2.start();
t3.start();
}
static class Task implements Runnable {
private final String name;
private final int threadId;
public Task(String name, int threadId) {
this.name = name;
this.threadId = threadId;
}
@Override
public void run() {
synchronized (lock) {
try {
while (threadId != currentThread) {
lock.wait();
}
System.out.println(name);
currentThread++;
lock.notifyAll();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
В этом примере создаются три потока: Т1, Т2 и Т3. Каждый поток выполняет свою задачу в методе run(). Перед выполнением задачи каждый поток проверяет значение переменной currentThread и ожидает, если оно не соответствует его идентификатору потока (threadId). Когда поток выполняет свою задачу, он увеличивает значение currentThread и оповещает все ожидающие потоки с помощью метода notifyAll().
Таким образом, потоки будут выполняться в последовательности Т1, Т2, Т3. Однако следует отметить, что точный порядок выполнения может зависеть от планировщика потоков операционной системы, и поэтому возможны некоторые вариации в реальном времени выполнения.
1094. Напишите минимальный неблокирующий стек (всего два метода — push() и pop()).
Неблокирующие структуры данных в Java могут быть реализованы с использованием атомарных операций и циклов CAS (Compare-and-Swap). Вот пример минимальной реализации неблокирующего стека с методами push() и pop():
import java.util.concurrent.atomic.AtomicReference;
public class NonBlockingStack<T> {
private static class Node<T> {
final T value;
Node<T> next;
Node(T value) {
this.value = value;
}
}
private final AtomicReference<Node<T>> top = new AtomicReference<>();
public void push(T value) {
Node<T> newNode = new Node<>(value);
Node<T> oldTop;
do {
oldTop = top.get();
newNode.next = oldTop;
} while (!top.compareAndSet(oldTop, newNode));
}
public T pop() {
Node<T> oldTop;
Node<T> newTop;
do {
oldTop = top.get();
if (oldTop == null) {
return null; // Стек пуст
}
newTop = oldTop.next;
} while (!top.compareAndSet(oldTop, newTop));
return oldTop.value;
}
}
В этой реализации используется класс AtomicReference, который обеспечивает атомарные операции чтения и записи ссылок. Каждый элемент стека представлен узлом Node, содержащим значение и ссылку на следующий узел.
Метод push() добавляет новый элемент на вершину стека. Он создает новый узел со значением и затем повторяет цикл CAS, чтобы попытаться обновить вершину стека на новый узел. Если операция CAS успешна, то новый узел успешно добавлен на вершину стека.
Метод pop() удаляет элемент с вершины стека. Он также использует цикл CAS для обновления вершины стека на следующий узел. Если операция CAS успешна, то возвращается значение удаленного узла.
Обратите внимание, что при использовании неблокирующих структур данных не гарантируется строгое соблюдение порядка операций между потоками. Это означает, что порядок, в котором элементы будут извлекаться из стека, может немного отличаться от порядка, в котором они были добавлены.
1095. Напишите минимальный неблокирующий стек (всего два метода — push() и pop()) с использованием Semaphore.
Неблокирующие структуры данных, такие как стек, обычно не используют семафоры для своей реализации, поскольку семафоры могут блокировать потоки, что противоречит идеологии неблокирующих алгоритмов. Однако я могу предложить вам реализацию неблокирующего стека без использования семафоров.
Вот пример минимальной реализации неблокирующего стека с методами push() и pop() на основе атомарных операций CAS (Compare-and-Swap):
import java.util.concurrent.atomic.AtomicReference;
public class NonBlockingStack<T> {
private static class Node<T> {
final T value;
Node<T> next;
Node(T value) {
this.value = value;
}
}
private final AtomicReference<Node<T>> top = new AtomicReference<>();
public void push(T value) {
Node<T> newNode = new Node<>(value);
do {
newNode.next = top.get();
} while (!top.compareAndSet(newNode.next, newNode));
}
public T pop() {
Node<T> oldTop;
Node<T> newTop;
do {
oldTop = top.get();
if (oldTop == null) {
return null; // Стек пуст
}
newTop = oldTop.next;
} while (!top.compareAndSet(oldTop, newTop));
return oldTop.value;
}
}
В этой реализации используется класс AtomicReference, который обеспечивает атомарные операции чтения и записи ссылок. Каждый элемент стека представлен узлом Node, содержащим значение и ссылку на следующий узел.
Метод push() добавляет новый элемент на вершину стека. Он создает новый узел со значением и затем повторяет цикл CAS, чтобы попытаться обновить вершину стека на новый узел. Если операция CAS успешна, то новый узел успешно добавлен на вершину стека.
Метод pop() удаляет элемент с вершины стека. Он также использует цикл CAS для обновления вершины стека на следующий узел. Если операция CAS успешна, то возвращается значение удаленного узла.
Такая реализация обеспечивает неблокирующее выполнение операций push() и pop(), не приводя потоки в состояние блокировки или ожидания.
1096. Напишите минимальный неблокирующий ArrayList (всего четыре метода — add(), get(), remove(), size()).
Ниже приведена минимальная реализация неблокирующего ArrayList с методами add(), get(), remove() и size(). Эта реализация использует атомарные операции CAS (Compare-and-Swap) для обеспечения неблокирующих операций.
import java.util.concurrent.atomic.AtomicReferenceArray;
public class NonBlockingArrayList<T> {
private static final int DEFAULT_CAPACITY = 16;
private AtomicReferenceArray<T> array;
private AtomicInteger size;
public NonBlockingArrayList() {
this(DEFAULT_CAPACITY);
}
public NonBlockingArrayList(int capacity) {
array = new AtomicReferenceArray<>(capacity);
size = new AtomicInteger(0);
}
public void add(T element) {
int index = size.getAndIncrement();
if (index >= array.length()) {
// Увеличение размера массива при нехватке места
int newCapacity = array.length() * 2;
AtomicReferenceArray<T> newArray = new AtomicReferenceArray<>(newCapacity);
for (int i = 0; i < array.length(); i++) {
newArray.set(i, array.get(i));
}
array = newArray;
}
array.set(index, element);
}
public T get(int index) {
if (index < 0 || index >= size.get()) {
throw new IndexOutOfBoundsException();
}
return array.get(index);
}
public T remove(int index) {
if (index < 0 || index >= size.get()) {
throw new IndexOutOfBoundsException();
}
T removedElement = array.get(index);
for (int i = index; i < size.get() - 1; i++) {
T nextElement = array.get(i + 1);
array.set(i, nextElement);
}
array.set(size.get() - 1, null);
size.decrementAndGet();
return removedElement;
}
public int size() {
return size.get();
}
}
В этой реализации используются классы AtomicReferenceArray и AtomicInteger для обеспечения атомарного доступа к массиву и размеру списка соответственно. AtomicReferenceArray предоставляет атомарные операции чтения и записи элементов массива.
Метод add() добавляет элемент в список. Если внутренний массив заполнен, происходит его увеличение в два раза. Метод get() возвращает элемент по указанному индексу. Метод remove() удаляет элемент по указанному индексу и сдвигает остальные элементы, чтобы заполнить пустую позицию. Метод size() возвращает текущий размер списка.
Обратите внимание, что эта реализация не обрабатывает конкурентный доступ из нескольких потоков. Для поддержки конкурентного доступа и безопасности потоков требуется дополнительная работа, например, использование CAS-операций при реализации методов add(), remove() и size().
1097. Напишите потокобезопасную реализацию класса с неблокирующим методом BigInteger next(), который возвращает элементы последовательности: [1, 2, 4, 8, 16, ...].
Ниже приведена потокобезопасная реализация класса с неблокирующим методом next(), который возвращает элементы последовательности [1, 2, 4, 8, 16, ...]:
import java.math.BigInteger;
import java.util.concurrent.atomic.AtomicReference;
public class PowerOfTwoSequence {
private AtomicReference<BigInteger> current;
public PowerOfTwoSequence() {
current = new AtomicReference<>(BigInteger.ONE);
}
public BigInteger next() {
while (true) {
BigInteger currentValue = current.get();
BigInteger nextValue = currentValue.multiply(BigInteger.TWO);
if (current.compareAndSet(currentValue, nextValue)) {
return currentValue;
}
}
}
}
В этой реализации используется класс AtomicReference для обеспечения атомарного доступа к текущему значению последовательности. Метод next() выполняет цикл, пока не удастся успешно обновить текущее значение с помощью операции compareAndSet(). Если операция выполнена успешно, то возвращается предыдущее значение последовательности. Таким образом, каждый вызов next() возвращает следующее значение в последовательности [1, 2, 4, 8, 16, ...].
Обратите внимание, что данная реализация гарантирует корректность работы в многопоточной среде без блокировки потоков.
1098. Напишите простейший многопоточный ограниченный буфер с использованием synchronized.
Пример простейшего многопоточного ограниченного буфера с использованием synchronized:
import java.util.LinkedList;
import java.util.Queue;
public class BoundedBuffer<T> {
private int capacity;
private Queue<T> buffer;
public BoundedBuffer(int capacity) {
this.capacity = capacity;
this.buffer = new LinkedList<>();
}
public synchronized void put(T element) throws InterruptedException {
while (buffer.size() == capacity) {
wait();
}
buffer.offer(element);
notifyAll();
}
public synchronized T take() throws InterruptedException {
while (buffer.isEmpty()) {
wait();
}
T element = buffer.poll();
notifyAll();
return element;
}
}
В этой реализации используются ключевое слово synchronized и методы wait() и notifyAll() для обеспечения синхронизации и взаимодействия между потоками.
Метод put(T element) добавляет элемент в буфер. Если буфер заполнен, вызывающий поток блокируется с помощью wait(), пока не появится место в буфере. Когда элемент успешно добавлен, другие потоки, которые могут ждать освобождения буфера, будут разблокированы с помощью notifyAll().
Метод take() извлекает элемент из буфера. Если буфер пуст, вызывающий поток блокируется с помощью wait(), пока в буфере не появится элемент. Когда элемент успешно извлечен, другие потоки, которые могут ждать добавления элемента в буфер, будут разблокированы с помощью notifyAll().
Обратите внимание, что методы put() и take() объявляют ожидаемое исключение InterruptedException, поскольку операции блокировки (через wait()) могут быть прерваны другими потоками. Это позволяет обработать прерывание правильным образом или пробросить его выше для дальнейшей обработки.
1099. Напишите простейший многопоточный ограниченный буфер с использованием ReentrantLock.
Пример простейшего многопоточного ограниченного буфера с использованием ReentrantLock:
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class BoundedBuffer<T> {
private int capacity;
private Queue<T> buffer;
private ReentrantLock lock;
private Condition notFullCondition;
private Condition notEmptyCondition;
public BoundedBuffer(int capacity) {
this.capacity = capacity;
this.buffer = new LinkedList<>();
this.lock = new ReentrantLock();
this.notFullCondition = lock.newCondition();
this.notEmptyCondition = lock.newCondition();
}
public void put(T element) throws InterruptedException {
lock.lock();
try {
while (buffer.size() == capacity) {
notFullCondition.await();
}
buffer.offer(element);
notEmptyCondition.signalAll();
} finally {
lock.unlock();
}
}
public T take() throws InterruptedException {
lock.lock();
try {
while (buffer.isEmpty()) {
notEmptyCondition.await();
}
T element = buffer.poll();
notFullCondition.signalAll();
return element;
} finally {
lock.unlock();
}
}
}
В этой реализации используется класс ReentrantLock для обеспечения синхронизации и взаимодействия между потоками. Класс Condition используется для определения условий ожидания и оповещения.
Метод put(T element) добавляет элемент в буфер. Если буфер заполнен, вызывающий поток блокируется с помощью await() на условии notFullCondition, пока не появится место в буфере. Когда элемент успешно добавлен, другие потоки, которые могут ждать освобождения буфера, будут оповещены с помощью signalAll() на условии notEmptyCondition.
Метод take() извлекает элемент из буфера. Если буфер пуст, вызывающий поток блокируется с помощью await() на условии notEmptyCondition, пока в буфере не появится элемент. Когда элемент успешно извлечен, другие потоки, которые могут ждать добавления элемента в буфер, будут оповещены с помощью signalAll() на условии notFullCondition.
Обратите внимание, что блокировки с использованием lock() и unlock() должны быть обернуты в конструкцию try-finally, чтобы гарантировать правильное освобождение блокировки даже в случае исключения.
к оглавлению
9. Java 8 (перейти в раздел)
1100. Какие нововведения, появились в Java 8 и JDK 8?
Некоторые функции Java 8 и JDK 8:
Лямбда-выраженияФункциональные интерфейсыStream APIМетоды по умолчанию в интерфейсахНовые методы в классе java.util.OptionalНовые методы в классе java.util.Date и java.timeОбновленный синтаксис try-with-resourcesНовые методы для работы со строками в классе java.lang.StringМетоды для работы с файлами в классе java.nio.file.FilesНовые методы для работы с коллекциями в классе java.util.Collection и java.util.Map
1101. Что такое «лямбда»? Какова структура и особенности использования лямбда-выражения?
Лямбда-выражения в Java - это способ создания анонимных функций (функций без имени), которые могут использоваться для реализации функционального программирования. Лямбда-выражения представляют собой компактный способ определения функции, не требующий лишних словесных конструкций.
Структура лямбда-выражения в Java имеет следующий вид:
(parameters) -> expression
Здесь параметры представляют собой список параметров функции, а expression - выражение, которое должно выполняться внутри функции.
Пример лямбда-выражения для вычисления квадрата числа:
(x) -> x * x
Выше мы определяем анонимную функцию, которая получает на вход число x и возвращает значение x * x.
Особенности использования лямбда-выражений в Java:
Лямбда-выражениямогут быть переданы как аргументы методов или использованы в качестве значений переменных функционального типа.Лямбда-выраженияне могут быть использованы самостоятельно, они всегда привязаны к функциональному интерфейсу.Функциональный интерфейсопределяет тип параметра лямбда-выражения и тип его результата.Лямбда-выражениямогут использовать переменные, определенные вне тела выражения. Эти переменные должны быть объявлены как final или effectively final.
Пример использования лямбда-выражений в Java:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4);
numbers.stream().map(x -> x * x).forEach(System.out::println);
1102. К каким переменным есть доступ у лямбда-выражений?
В лямбда-выражениях в Java можно обращаться к локальным переменным, объявленным во внешнем блоке. Однако такие переменные должны быть объявлены как final или effectively final. Это значит, что значение переменной не может быть изменено после присвоения.
Например, следующий код корректен, потому что переменная i объявлена как final:
final int i = 42;
Runnable r = () -> System.out.println("The answer is " + i);
А вот следующий код выдаст ошибку компиляции, потому что переменная i не объявлена как final:
int i = 42;
Runnable r = () -> System.out.println("The answer is " + i);
i = 43; // ошибка компиляции
Также в лямбда-выражении можно ссылаться на static переменные класса, как и на методы этого класса.
1103. Как отсортировать список строк с помощью лямбда-выражения?
Чтобы отсортировать список строк с помощью лямбда-выражения в Java, вы можете использовать метод sort() из класса List вместе с лямбда-выражением, которое задает порядок сортировки. Вот пример:
List<String> myList = new ArrayList<String>();
myList.add("b");
myList.add("a");
myList.add("c");
myList.sort((s1, s2) -> s1.compareTo(s2));
System.out.println(myList); //[a, b, c]
В этом примере sort() метод вызывается для списка строк myList, а лямбда-выражение (s1, s2) -> s1.compareTo(s2) определяет порядок сортировки. Оно сравнивает две строки s1 и s2 и возвращает результат сравнения в соответствии с методом compareTo() из интерфейса Comparable.
Обратите внимание, что при сортировке строк метод compareTo() сравнивает строки в лексикографическом порядке (т. е. в алфавитном порядке). Если вы хотите сортировать строки по другому критерию, вы можете изменить лямбда-выражение.
1104. Что такое «ссылка на метод»?
"Ссылка на метод" (method reference) - это компактное выражение в языке Java, которое позволяет использовать существующий метод в качестве значения функции. Вместо использования лямбда-выражения для определения функции, можно передать ссылку на уже существующий метод, который будет использоваться в качестве функции. Это позволяет писать более лаконичный и читаемый код.
Ссылка на метод может быть создана с помощью оператора двойного двоеточия (::). Например, System.out::println- ссылка на статический метод println класса System.out.
Существуют три вида ссылок на методы:
Ссылка на статический метод (ClassName::methodName).Ссылка на метод определенный в объекте (object::methodName).Ссылка на конструктор (ClassName::new).
Например, вместо того, чтобы писать лямбда-выражение для вывода строки в консоль, можно использовать ссылку на метод println класса System.out:
list.forEach(System.out::println);
Это эквивалентно следующему лямбда-выражению:
list.forEach(s -> System.out.println(s));
1105. Какие виды ссылок на методы вы знаете?
В Java существуют несколько типов ссылок на методы:
Ссылки на статические методы: ContainingClass::staticMethodNameСсылки на методы экземпляра: containingObject::instanceMethodNameСсылки на конструкторы: ClassName::newСсылки на методы с одним параметром, который совместим с функциональным интерфейсом: TypeName::methodName
Например, вот как можно использовать ссылку на методы с помощью лямбда-выражения:
Function<String, Integer> strLength = String::length;
int len = strLength.apply("Hello World"); // len = 11
В этом примере, метод String::length используется для получения длины строки, и ссылка на метод передается функциональному интерфейсу Function<String, Integer>, который принимает строку и возвращает целое число.
1106. Объясните выражение System.out::println.
Выражение System.out::println в Java относится к ссылке на метод. В частности, это относится к методу println объекта out класса System.
Метод println используется для вывода сообщения на консоль и добавления в конце символа новой строки. Объект System.out является экземпляром класса PrintStream и предоставляет удобные методы для записи данных на консоль.
Когда вы используете выражение ссылки на метод System.out::println, вы, по сути, создаете ссылку на метод println, которую затем можно передать как аргумент метода или сохранить в переменной. Хотя это может выглядеть как лямбда-выражение, это не совсем то же самое. Вот пример того, как использовать ссылку на этот метод в лямбда-выражении для печати значений массива:
String[] names = {"Alice", "Bob", "Charlie"};
Arrays.stream(names).forEach(System.out::println);
Это выведет:
Alice
Bob
Charlie
Метод forEach интерфейса Stream принимает лямбда-выражение, которое принимает элемент потока в качестве входных данных. В этом случае ссылка на метод System.out::println используется для вывода каждого элемента массива имен на консоль.
1107. Что такое «функциональные интерфейсы»?
"Функциональные интерфейсы" в Java - это интерфейсы, которые содержат только один абстрактный метод. Они предназначены для использования с лямбда-выражениями (lambda expressions) и методами ссылок (method references) в Java 8 и выше.
Java предоставляет несколько встроенных функциональных интерфейсов в пакете java.util.function, таких как Predicate, Consumer, Function, Supplier и другие. Каждый из этих интерфейсов представляет функцию, которую можно передать в качестве аргумента или вернуть как результат из другого метода, что делает возможным написание более конкретного кода, чем это было раньше.
Например, Predicate представляет функцию, которая принимает один аргумент и возвращает значение типа boolean.
Интерфейс Function представляет функцию, которая принимает один аргумент и возвращает значение другого типа. Consumer представляет функцию, которая принимает один аргумент и ничего не возвращает, а Supplier представляет функцию, которая ничего не принимает и возвращает значение.
Использование функциональных интерфейсов вместе с лямбда-выражениями позволяет более эффективно и просто передавать функции в другие методы и создавать новые функции внутри других методов.
Пример использования интерфейса Function:
import java.util.function.Function;
public class Example {
public static void main(String[] args) {
Function<Integer, Integer> square = x -> x * x;
System.out.println(square.apply(5)); // выводит на экран 25
}
}
Этот код создает новую функцию square, которая принимает целое число и возвращает его квадрат. Затем мы вызываем эту функцию и передаем ей число.
Еще примеры:
Predicate<String> isLong = s -> s.length() > 10;
boolean result = isLong.test("This is a very long string");
System.out.println(result); // Output: true
Consumer<String> printUpperCase = s -> System.out.println(s.toUpperCase());
printUpperCase.accept("hello"); // Output: HELLO
Supplier<Double> randomDouble = () -> Math.random();
double value = randomDouble.get();
System.out.println(value); // Output: a random double value between 0.0 and 1.0
1108. Для чего нужны функциональные интерфейсы Function<T,R>, DoubleFunction<R>, IntFunction<R> и LongFunction<R>?
Функциональные интерфейсы Function<T,R>, DoubleFunction<R>, IntFunction<R> и LongFunction<R> предназначены для работы с лямбда-выражениями и представляют функции, которые принимают один или несколько аргументов и возвращают результат.
Function<T,R>принимает один аргумент типа T и возвращает результат типа R. Он может использоваться для преобразования объектов одного типа в объекты другого типа.DoubleFunction<R>принимает один аргумент типа double и возвращает результат типа R.IntFunction<R>принимает один аргумент типа int и возвращает результат типа R.LongFunction<R>принимает один аргумент типа long и возвращает результат типа R.
Эти интерфейсы могут использоваться вместе с лямбда-выражениями для определения различных функций, например для преобразования данных, обработки числовых значений и т.д.
Пример использования Function<T,R> в лямбда-выражении:
Function<Integer, Integer> multiplyByTwo = x -> x * 2;
int result = multiplyByTwo.apply(5); // результат: 10
Пример использования IntFunction в лямбда-выражении:
IntFunction<String> intToString = x -> Integer.toString(x);
String result = intToString.apply(5); // результат: "5"
Пример использования DoubleFunction в лямбда-выражении:
DoubleFunction<Integer> roundUp = x -> (int) Math.ceil(x);
int result = roundUp.apply(4.2); // результат: 5
Пример использования LongFunction в лямбда-выражении:
LongFunction<String> longToString = x -> Long.toString(x);
String result = longToString.apply(5000000000L); // результат: "5000000000"
1109. Для чего нужны функциональные интерфейсы UnaryOperator<T>, DoubleUnaryOperator, IntUnaryOperator и LongUnaryOperator?
Функциональные интерфейсы UnaryOperator, DoubleUnaryOperator, IntUnaryOperator и LongUnaryOperator в Java представляют функции, которые принимают один аргумент и возвращают результат того же типа, что и аргумент (за исключением DoubleUnaryOperator, который может возвращать результат другого числового типа). Они являются частью пакета java.util.function, который был представлен в Java 8 для поддержки функционального программирования.
UnaryOperator принимает один аргумент типа T и возвращает значение того же типа. DoubleUnaryOperator, IntUnaryOperator и LongUnaryOperator работают аналогично, но принимают аргументы типов double, int и long соответственно.
Пример использования UnaryOperator:
UnaryOperator<String> upperCase = str -> str.toUpperCase();
System.out.println(upperCase.apply("hello"));
Этот код создает объект UnaryOperator, который берет строку и преобразует ее в верхний регистр. Затем он вызывает метод apply() этого объекта на строке "hello", что приводит к выводу строки "HELLO".
Таким образом, эти функциональные интерфейсы позволяют передавать функции как параметры в методы, а также использовать их для создания лямбда-выражений и ссылок на методы.
1110. Для чего нужны функциональные интерфейсы BinaryOperator<T>, DoubleBinaryOperator, IntBinaryOperator и LongBinaryOperator?
В Java функциональные интерфейсы BinaryOperator, DoubleBinaryOperator, IntBinaryOperator и LongBinaryOperator используются для задания операций, принимающих два аргумента одного типа и возвращающих значение того же типа. BinaryOperator применяется к обобщенному типу T, а DoubleBinaryOperator, IntBinaryOperator и LongBinaryOperator - к примитивным числовым типам double, int и long соответственно.
- Пример использования BinaryOperator:
BinaryOperator<Integer> add = (x, y) -> x + y;
int result = add.apply(2, 3); // result будет равен 5
- Пример использования DoubleBinaryOperator:
DoubleBinaryOperator average = (x, y) -> (x + y) / 2.0;
double result = average.applyAsDouble(5.0, 7.0); // result будет равен 6.0
- Пример использования IntBinaryOperator:
IntBinaryOperator max = (x, y) -> x > y ? x : y;
int result = max.applyAsInt(4, 6); // result будет равен 6
- Пример использования LongBinaryOperator:
LongBinaryOperator multiply = (x, y) -> x * y;
long result = multiply.applyAsLong(3L, 5L); // result будет равен 15L
Такие функциональные интерфейсы могут быть использованы для более удобной реализации применения различных операций к элементам коллекции и для более гибкой работой с лямбда-выражениями.
1111. Для чего нужны функциональные интерфейсы Predicate<T>, DoublePredicate, IntPredicate и LongPredicate?
Java функциональные интерфейсы Predicate, DoublePredicate, IntPredicate и LongPredicate используются для проверки условий на соответствие определенному типу данных.
Predicate используется для определения условия, которое может быть применено к объекту типа T, возвращается булево значение true/false. DoublePredicate, IntPredicate и LongPredicate используются для определения условия, которое может быть применено соответственно к типам double, int и long.
- Пример использования Predicate:
Predicate<String> startsWithA = (s) -> s.startsWith("A");
boolean result = startsWithA.test("Apple");
// result равен true
- Пример использования IntPredicate:
IntPredicate isEven = (n) -> n % 2 == 0;
boolean result = isEven.test(4);
// result равен true
Такие интерфейсы могут использоваться в различных операциях фильтрации, сортировки, поиске и т.д. в коллекциях.
1112. Для чего нужны функциональные интерфейсы Consumer<T>, DoubleConsumer, IntConsumer и LongConsumer?
Функциональные интерфейсы Consumer, DoubleConsumer, IntConsumer и LongConsumer используются в Java 8 и выше для представления функций, которые принимают один или несколько аргументов и не возвращают значения (т.е. представляют "потребление" данных). Эти интерфейсы могут использоваться в простых выражениях лямбда или методов ссылки для передачи функциональных параметров, не требующих явного определения функций.
Consumer используется для представления операции, которая принимает один аргумент типа T, и не возвращает результат. Например, вы можете использовать Consumer для вывода списка элементов:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(name -> System.out.println(name)); // используется Consumer<T> в качестве своего функционального параметра
DoubleConsumer, IntConsumer и LongConsumer представляют аналогичные операции для числовых значений с плавающей точкой, целочисленных (int) и длинных целых (long) значений соответственно. Эти функциональные интерфейсы обеспечивают более эффективную обработку примитивных переменных, чем использование Consumer.
1113. Для чего нужны функциональные интерфейсы Supplier<T>, BooleanSupplier, DoubleSupplier, IntSupplier и LongSupplier?
В Java функциональные интерфейсы Supplier, BooleanSupplier, DoubleSupplier, IntSupplier и LongSupplier используются для представления функций, которые не принимают аргументы и возвращают значения определенных типов.
Supplier<T>- функциональный интерфейс, который описывает метод get(), который принимает ноль аргументов и возвращает значение типа T. Он может использоваться в качестве поставщика значений для других функций.BooleanSupplier- функциональный интерфейс, который описывает метод getAsBoolean(), который принимает ноль аргументов и возвращает значение типа boolean. Он может использоваться, когда нужно предоставить поставщика логических значений.DoubleSupplier- функциональный интерфейс, который описывает метод getAsDouble(), который принимает ноль аргументов и возвращает значение типа double. Он может использоваться, когда нужно предоставить поставщика значений double.IntSupplier- функциональный интерфейс, который описывает метод getAsInt(), который принимает ноль аргументов и возвращает значение типа int. Он может использоваться, когда нужно предоставить поставщика значений int.LongSupplier- функциональный интерфейс, который описывает метод getAsLong(), который принимает ноль аргументов и возвращает значение типа long. Он может использоваться, когда нужно предоставить поставщика значений long.
Эти функциональные интерфейсы делают код более читабельным, позволяют избежать дублирования кода и улучшают производительность. Они также могут использоваться для передачи функций в качестве параметров в другие методы, что делает код более гибким и расширяемым.
1114. Для чего нужен функциональный интерфейс BiConsumer<T,U>?
В Java 8 и более поздних версиях, функциональный интерфейс BiConsumer<T,U> определяет метод accept с двумя аргументами, без возвращаемого значения, что позволяет передавать функцию, которая принимает два аргумента и выполняет какие-то действия. Это полезно, когда необходимо передать функцию для выполнения операций на парах значений.
Например, если у Вас есть коллекция, и вы хотите пройти через каждый элемент, для выполнения некоторых операций над множеством значений с помощью forEach(), можно использовать BiConsumer для выполнения операций над элементами коллекции.
Вот пример использования BiConsumer:
List<String> names = Arrays.asList("Alex", "Bob", "Charlie");
BiConsumer<Integer, String> biConsumer = (index, name) -> System.out.println(index + "-" + name);
IntStream.range(0, names.size()).forEach(i -> biConsumer.accept(i, names.get(i)));
Этот пример выведет:
0-Alex
1-Bob
2-Charlie
где BiConsumer используется для построения значения пары, содержащего индекс элемента списка и сам элемент, а затем передается в метод forEach() для обработки.
1114. Для чего нужен функциональный интерфейс BiFunction<T,U,R>?
Функциональный интерфейс BiFunction<T, U, R> в Java определяет функцию, которая принимает два аргумента типов T и U и возвращает результат типа R. Этот интерфейс может использоваться для передачи функции в качестве аргумента в метод, который ожидает функцию, или как тип результата, возвращаемого из метода, который возвращает функцию. Например, можно использовать BiFunction для объединения двух коллекций в одну, где результатом является коллекция, содержащая все элементы первой и второй коллекций.
Вот пример использования BiFunction для объединения двух списков строк:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.function.BiFunction;
public class Main {
public static void main(String[] args) {
List<String> list1 = Arrays.asList("a", "b", "c");
List<String> list2 = Arrays.asList("d", "e", "f");
BiFunction<List<String>, List<String>, List<String>> mergeLists = (l1, l2) -> {
List<String> result = new ArrayList<>(l1);
result.addAll(l2);
return result;
};
List<String> mergedList = mergeLists.apply(list1, list2);
System.out.println(mergedList);
}
}
Этот код объединяет два списка строк и выводит результат: [a, b, c, d, e, f].
1115. Для чего нужен функциональный интерфейс BiPredicate<T,U>?
Функциональный интерфейс BiPredicate<T, U> в Java используется для определения метода, который принимает два аргумента типа T и U и возвращает значение типа boolean. Он широко используется для тестирования условий, которые зависят от двух значений.
Как и другие функциональные интерфейсы в Java 8, BiPredicate<T, U> можно использовать для создания лямбда-выражений. Например, приведенный ниже код использует BiPredicate для сравнения двух строк:
BiPredicate<String,String> equals = (s1, s2) -> s1.equals(s2);
if(equals.test("hello","hello")){
System.out.println("Strings are equal");
}
Этот код создает лямбда-выражение, которое сравнивает две строки и возвращает true, если они совпадают. Затем этот BiPredicate используется для проверки, равны ли две строки, и выводится сообщение "Strings are equal".
1116. Для чего нужны функциональные интерфейсы вида _To_Function?
Функциональные интерфейсы вида _To_Function в Java представляют собой интерфейсы, которые определяют функции, которые принимают в качестве аргумента объект типа T и возвращают объект типа R. Эти интерфейсы используются в лямбда-выражениях и могут быть использованы везде, где требуется функция с заданным типом. В частности, они полезны для реализации стримовых операций, таких как отображение, фильтрация или свертка, а также для обобщения кода, улучшения его читаемости и сокращения объема кода при работе с функциями высшего порядка. Например, интерфейс DoubleToIntFunction определяет функцию, которая преобразует значение типа double в значение типа int.
1117. Для чего нужны функциональные интерфейсы ToDoubleBiFunction<T,U>, ToIntBiFunction<T,U> и ToLongBiFunction<T,U>?
Данные функциональные интерфейсы из пакета java.util.function используются для описания функций, которые принимают два аргумента определенных типов и возвращают результаты определенного типа.
-
ToDoubleBiFunction<T,U>- функция, которая принимает два аргумента типа T и U и возвращает результат типа double. -
ToIntBiFunction<T,U>- функция, которая принимает два аргумента типа T и U и возвращает результат типа int. -
ToLongBiFunction<T,U>- функция, которая принимает два аргумента типа T и U и возвращает результат типа long.
Эти интерфейсы могут использоваться для представления функций, которые принимают два аргумента, например, для агрегации данных или преобразования пары значений. Например, ToDoubleBiFunction может использоваться для среднего значения двух чисел типа double, ToIntBiFunction для суммирования двух чисел типа int, ToLongBiFunction для произведения двух чисел типа long. Их использование особенно удобно в лямбда-выражениях, которые можно передавать в качестве аргументов методов для обработки данных в коллекциях и потоках данных (Streams).
Классы, которые реализуют эти интерфейсы, могут использоваться для обработки данных, таких как список или массив объектов, каждый из которых имеет два свойства. Например, можно отсортировать список объектов, используя метод sorted() и передавая ему компаратор, который будет сравнивать объекты с помощью методов ToDoubleBiFunction, ToIntBiFunction или ToLongBiFunction.
Пример использования ToDoubleBiFunction<T,U>:
import java.util.function.ToDoubleBiFunction;
public class Example {
public static void main(String[] args) {
ToDoubleBiFunction<Integer, Integer> product = (a, b) -> a * b * 1.0;
double result = product.applyAsDouble(2, 3);
System.out.println(result);
}
}
В этом примере создается объект ToDoubleBiFunction, который перемножает два целых числа и возвращает результат в виде дробного числа. Затем этот объект используется для вычисления произведения двух чисел (2 и 3) и результат выводится на консоль.
Аналогичным образом можно использовать ToIntBiFunction и ToLongBiFunction, чтобы выполнить операции с целочисленными и длинными целыми числами.
1118. Для чего нужны функциональные интерфейсы ToDoubleFunction<T>, ToIntFunction<T> и ToLongFunction<T>?
Функциональные интерфейсы ToDoubleFunction, ToIntFunction и ToLongFunction являются частями пакета java.util.function в Java 8 и позже, и используются в лямбда-выражениях для преобразования значений типа T в значения типа double, int и long соответственно. Каждый из этих функциональных интерфейсов определяет только один метод, принимающий входное значение типа T и возвращающий преобразованное значение типа double, int или long. Например, ToDoubleFunction имеет метод applyAsDouble(T t), который принимает значение типа T и возвращает преобразованное значение типа double.
Пример использования ToDoubleFunction:
ToDoubleFunction<Integer> square = i -> i * i * 1.0;
double result = square.applyAsDouble(5); // result = 25.0
Здесь лямбда-выражение i -> i * i * 1.0 принимает значение типа Integer, возвращает его квадрат, умноженный на 1.0, чтобы получить результат типа double.
Использование ToIntFunction и ToLongFunction аналогичны. Они часто используются при обработке больших наборов данных в функциональном стиле кодирования.
1119. Для чего нужны функциональные интерфейсы ObjDoubleConsumer<T>, ObjIntConsumer<T> и ObjLongConsumer<T>?
Функциональные интерфейсы ObjDoubleConsumer, ObjIntConsumer и ObjLongConsumer в Java предназначены для передачи функций с двумя аргументами типа double, int и long соответственно. Эти интерфейсы обеспечивают типизированный доступ к методам, принимающим два аргумента.
Например, можно использовать интерфейс ObjIntConsumer для передачи функции, которая принимает объект типа T и целочисленное значение, и выполняет некоторые действия над ними. Подобным образом для произвольных типов данных можно использовать ObjDoubleConsumer и ObjLongConsumer.
Эти функциональные интерфейсы входят в состав пакета java.util.function в Java 8 и выше. Они предоставляют средства для работы с лямбда-выражениями и методами ссылки, позволяя удобно и эффективно использовать функциональное программирование в Java.
1120. Что такое StringJoiner?
StringJoiner - это класс в Java, который был добавлен в Java 8 для создания строки, объединяя элементы с использованием разделителя и опционального префикса и суффикса.
Он имеет конструктор, который может принимать разделитель, префикс и суффикс, а также методы add() для добавления элементов в строку и toString() для получения окончательной строки.
Вот пример использования класса StringJoiner в Java:
StringJoiner sj = new StringJoiner(", ", "{", "}");
sj.add("John")
.add("Doe")
.add("Jane");
String result = sj.toString(); // "{John, Doe, Jane}"
В этом примере мы создаем объект StringJoiner с разделителем ", ", префиксом "{" и суффиксом "}". Затем мы добавляем три элемента ("John", "Doe" и "Jane") с помощью метода add(), а затем используем метод toString() для получения окончательной строки.
Еще примры:
StringJoiner joiner = new StringJoiner(",");
joiner.add("apple");
joiner.add("orange");
joiner.add("banana");
String joined = joiner.toString(); // "apple,orange,banana"
Важно отметить, что StringJoiner внутри использует StringBuilder для объединения строк, что делает его более оптимальным по скорости выполнения, чем использование конкатенации строк с помощью оператора "+".
1120. Что такое default методы интрефейса?
Методы по умолчанию в интерфейсах Java были введены в Java 8 и позволяют интерфейсам предоставлять реализации для своих методов. Это означает, что интерфейсы теперь могут иметь конкретные методы в дополнение к абстрактным методам, что было невозможно до Java 8.
С помощью методов по умолчанию вы можете добавлять новые методы в интерфейс, не нарушая существующие реализации этого интерфейса в классах, которые его реализуют. Это связано с тем, что метод по умолчанию предоставляет реализацию по умолчанию, которую при необходимости можно переопределить в классе реализации. Вот пример интерфейса с методом по умолчанию:
public interface MyInterface {
void myMethod();
default void myDefaultMethod() {
// default implementation
}
}
Классы, реализующие этот интерфейс, автоматически наследуют реализацию myDefaultMethod по умолчанию. Если они хотят предоставить альтернативную реализацию, они могут просто переопределить ее в классе.
Методы по умолчанию особенно полезны при работе с унаследованным кодом, поскольку они позволяют добавлять новые функции в интерфейсы без необходимости изменять существующие конкретные реализации этих интерфейсов.
1121. Как вызывать default метод интерфейса в реализующем этот интерфейс классе?
В Java default методы интерфейса предоставляют реализацию по умолчанию, которую можно использовать в классе, который реализует этот интерфейс или переопределить, если необходимо.
Для вызова default метода интерфейса в классе необходимо использовать его объект, так как метод не является статическим. Например, если у нас есть интерфейс с default методом, как показано ниже:
public interface MyInterface {
default void myMethod() {
System.out.println("Default method");
}
}
Мы можем реализовать этот интерфейс в классе следующим образом:
public class MyClass implements MyInterface {
public void myOtherMethod() {
// вызов default метода интерфейса
MyInterface.super.myMethod();
}
}
В этом примере мы используем ключевое слово super для вызова default метода из интерфейса.
1122. Что такое static метод интерфейса?
В Java вы можете объявлять статические методы в интерфейсах с помощью ключевого слова static. Статические методы в интерфейсах автономны, что означает, что они не работают ни с одним экземпляром интерфейса и не привязаны к реализующему классу. Вот пример того, как объявить статический метод в интерфейсе:
public interface MyInterface {
static void myStaticMethod() {
System.out.println("This is a static method in an interface");
}
}
Чтобы вызвать этот статический метод, вы можете просто использовать имя интерфейса:
MyInterface.myStaticMethod();
Статические методы в интерфейсах могут быть полезны в служебных классах, где требуется метод, не привязанный к экземпляру класса, но логически связанный с классом. Кроме того, они могут помочь с организацией кода и сделать код более кратким и читабельным.
1123. Как вызывать static метод интерфейса?
Чтобы вызвать статический метод в интерфейсе Java, вы можете использовать имя интерфейса, за которым следует имя метода, например:
public interface MyInterface {
static void myStaticMethod() {
System.out.println("Hello from static method!");
}
}
class MyClass {
public static void main(String[] args) {
MyInterface.myStaticMethod(); // call static method
}
}
В этом примере MyInterface — это имя интерфейса, а myStaticMethod() — имя статического метода, определенного в интерфейсе. Чтобы вызвать статический метод, мы используем имя интерфейса, за которым следует имя метода, разделенное точкой (.). Обратите внимание, что вам не нужен экземпляр интерфейса для вызова статического метода, так как он принадлежит самому интерфейсу.
1124. Что такое Optional?
Optional является классом в Java, который может содержать значение или отсутствовать (быть null). Это предназначено для борьбы с NullPointerException, что может произойти, когда вы пытаетесь использовать значение null. Вместо этого вы можете использовать Optional, чтобы проверить, содержит ли объект значение, и если это так, получить это значение. Например, вы можете использовать Optional для получения значения из HashMap, при условии, что ключ существует в карте. Пример использования Java Optional:
Optional<String> fullName = Optional.ofNullable(null);
System.out.println("Full Name is set? " + fullName.isPresent());
System.out.println("Full Name: " + fullName.orElseGet(() -> "[none]"));
System.out.println(fullName.map(s -> "Hey " + s + "!").orElse("Hey Stranger!"));
Этот пример проверяет, есть ли значение в Optional fullName, и если нет, выводит "none" с помощью orElseGet(). Затем он использует map(), чтобы добавить "Hey" к имени, если значение существует, и затем выводит приветствие.
1125. Что такое Stream?
В Java 8 был добавлен новый интерфейс java.util.stream.Stream, который представляет собой поток элементов с возможностью выполнения составных операций над ними. Java Stream API позволяет использовать функциональное программирование для обработки коллекций, массивов и других источников данных.
Java Stream API включает в себя множество методов для выполнения различных операций над элементами потока, таких как фильтрация, сортировка, сведение, группировка и т.д. Также API поддерживает параллельную обработку элементов потоков, что позволяет эффективно использовать многоядерные процессоры.
Пример использования Stream API для фильтрации списка строк по длине:
List<String> list = Arrays.asList("apple", "orange", "banana", "pear");
List<String> filteredList = list.stream()
.filter(s -> s.length() > 5)
.collect(Collectors.toList());
В данном примере создается поток элементов из исходного списка, после чего выполняется операция фильтрации по длине строки, чтобы оставить только те элементы, которые содержат более 5 символов. Результат операции коллекционируется в новый список filteredList.
Одна из особенностей Stream API - ленивые вычисления: код, описывающий операции над потоком, не выполняется сразу, а только при вызове терминальной операции, например, метода collect(). Это позволяет минимизировать накладные расходы при выполнении операций, поскольку фактические вычисления выполняются только в тот момент, когда они действительно необходимы.
1126. Какие существуют способы создания стрима?
Для создания Stream в Java 8 и выше есть несколько способов:
Создание стрима из коллекции с помощью метода stream():
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
Создание стрима из массива с помощью Arrays.stream():
String[] array = { "a", "b", "c" };
Stream<String> stream = Arrays.stream(array);
Создание пустого стрима с помощью метода Stream.empty():
Stream<String> stream = Stream.empty();
Создание стрима из заданных значений с помощью Stream.of():
Stream<String> stream = Stream.of("a", "b", "c");
Создание стрима с помощью IntStream.range() для последовательности чисел:
IntStream stream = IntStream.range(0, 10);
Создание стрима с помощью методов Stream.generate() или Stream.iterate(), чтобы генерировать бесконечные потоки:
Stream<Integer> stream = Stream.generate(() -> 1);
Stream<Integer> stream = Stream.iterate(0, n -> n + 2);
Из значений: можно создать стрим из явно заданных элементов используя метод
Stream.of(value1, value2, ...)
Stream<String> stream = Stream.of("one", "two", "three");
Из файла: можно создать стрим из строк в файле используя метод Files.lines(Path path):
Stream<String> stream = Files.lines(Paths.get("file.txt"));
Это не полный список методов для создания Stream. В зависимости от задачи, можно выбрать подходящий метод для создания Stream.
1127. В чем разница между Collection и Stream?
Коллекции (Collection) и потоки (Stream) являются частями Java Collections Framework и используются для хранения и манипулирования набором элементов.
Коллекции используются для хранения элементов в памяти и предоставляют различные методы для добавления, удаления, поиска и т.д. Коллекции в Java могут быть реализованы в виде списков (List), множеств (Set) и списков ключей-значений (Map), а также других типов.
Потоки (Stream) используются для выполнения операций на элементах коллекций и других типов данных, например, на массивах. Потоки позволяют осуществлять операции над элементами в функциональном стиле, включая фильтрацию, отображение, сортировку, группировку и т.д. Каждая операция создает новый поток, который можно использовать для выполнения следующей операции.
Основное отличие между коллекциями и потоками заключается в том, что коллекции используются для хранения элементов в памяти, а потоки выполняют операции над элементами на лету.
Кроме того, потоки могут использоваться для выполнения операций параллельно, в то время как коллекции выполняют операции только последовательно.
1128. Для чего нужен метод collect() в стримах?
Метод collect() в Stream API используется для преобразования элементов потока в какую-то коллекцию или другой объект, например, массив или строку. Метод collect() принимает в себя объект класса Collector, который описывает, как элементы потока должны быть собраны в коллекцию. Класс Collector предоставляет ряд фабричных методов, таких как toList(), toSet(), toMap() и многие другие, которые позволяют создать различные типы коллекций.
Пример использования метода collect():
List<String> resultList = names.stream()
.filter(s -> s.startsWith("A"))
.collect(Collectors.toList());
В этом примере мы фильтруем имена, начинающиеся с буквы "A", из потока и используем метод collect() для сбора отфильтрованных элементов в новый список resultList.
Также метод collect() может использоваться для сбора элементов потока в объект другого типа. Например, вы можете использовать метод collect() для сбора элементов потока в строку, используя фабричный метод Collectors.joining():
String resultString = names.stream()
.collect(Collectors.joining(", "));
В этом примере мы используем метод collect() для сбора всех строк из потока в одну строку с разделителем ", ".
Например, если нам нужно преобразовать список строк в Set строк, мы можем использовать метод collect() следующим образом:
List<String> list = Arrays.asList("a", "b", "c");
Set<String> set = list.stream().collect(Collectors.toSet());
Метод collect() также может быть использован для агрегации элементов стрима в один объект. Например, мы можем использовать его для нахождения суммы элементов числового стрима:
IntStream stream = IntStream.of(1, 2, 3, 4, 5);
int sum = stream.collect(Collectors.summingInt(i -> i));
1129. Для чего в стримах применяются методы forEach() и forEachOrdered()?
Методы forEach() и forEachOrdered() применяются для выполнения некоторой операции для каждого элемента в потоке. Оба метода принимают в качестве аргумента объект типа Consumer, который представляет собой операцию, которая будет выполнена для каждого элемента потока. Однако, есть разница в том, как эти методы обрабатывают элементы потока.
Метод forEach() может обрабатывать элементы параллельно, что может привести к неопределенному порядку обработки элементов. То есть порядок обработки элементов может отличаться каждый раз при запуске программы. Этот метод хорошо подходит, если порядок обработки не имеет значения.
Метод forEachOrdered() гарантирует, что элементы будут обработаны в том порядке, в котором они находятся в потоке. Он также может быть использован в параллельных потоках, но в таком случае потеряется преимущество параллельной обработки.
Например, следующий код применяет метод forEach() к потоку списка строк, который выводит каждую строку на консоль:
List<String> strings = Arrays.asList("a", "b", "c");
strings.stream().forEach(System.out::println);
А следующий код применяет метод forEachOrdered() к тому же потоку:
List<String> strings = Arrays.asList("a", "b", "c");
strings.stream().forEachOrdered(System.out::println);
Оба примера должны вывести строку "a", затем "b", затем "c", но в первом примере порядок может быть случайным.
1130. Для чего в стримах предназначены методы map() и mapToInt(), mapToDouble(), mapToLong()?
Методы map() и mapToInt(), mapToDouble(), mapToLong() в Java Stream API предназначены для трансформации элементов потока в другие значения. map() позволяет применить заданную функцию к каждому элементу потока и получить новый поток с результатами этой функции. Например, можно использовать map() для преобразования списка строк в список длин этих строк.
mapToInt(), mapToDouble() и mapToLong() используются для выполнения той же функции, но к элементам потока применяются специализированные функции, которые возвращают значения соответствующего примитивного типа данных. Эти методы могут быть полезны, если вы хотите произвести операции, которые работают только с конкретным типом данных.
Пример использования метода map() для преобразования списка строк в список длин этих строк:
List<String> myList = Arrays.asList("Java", "Stream", "API", "example");
List<Integer> result = myList.stream()
.map(x -> x.length())
.collect(Collectors.toList());
В результате получим список длин строк:
[4, 6, 3, 7]
Пример использования метода mapToInt() для преобразования списка чисел с плавающей точкой в список целых чисел:
List<Double> myList = Arrays.asList(3.14, 2.7, 1.618, 0.0);
List<Integer> result = myList.stream()
.mapToInt(Double::intValue)
.boxed()
.collect(Collectors.toList());
В результате получим список целых чисел:
[3, 2, 1, 0]
1131. Какова цель метода filter() в стримах
Метод filter() в Java Stream API используется для фильтрации элементов в стриме. Он принимает в качестве аргумента предикат, который определяет, оставлять элемент в стриме или удалить его. Предикат - это функция, которая принимает элемент стрима в качестве аргумента и возвращает булево значение, указывающее, оставлять элемент или удалить его.
Например, если у нас есть стрим целых чисел и мы хотим оставить только четные числа, мы можем использовать метод filter() следующим образом:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
Stream<Integer> stream = numbers.stream();
// Оставляем только четные числа
Stream<Integer> evenNumbersStream = stream.filter(n -> n % 2 == 0);
// Собираем результат в список
List<Integer> evenNumbersList = evenNumbersStream.collect(Collectors.toList());
System.out.println(evenNumbersList); // Выводит: [2, 4, 6]
Как видно из примера, метод filter() возвращает новый стрим, содержащий только элементы, для которых предикат возвращает true. Этот новый стрим можно использовать для дальнейшей обработки данных.
Например, в следующем коде мы создаем список чисел и фильтруем его, чтобы оставить только нечетные числа:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
List<Integer> oddNumbers = numbers.stream()
.filter(n -> n % 2 != 0)
.collect(Collectors.toList());
System.out.println(oddNumbers); // Выводит: [1, 3, 5, 7, 9]
В этом примере мы используем метод stream(), чтобы получить стрим из списка чисел, затем используем метод filter() для отбора только нечетных чисел, и наконец используем метод collect() для преобразования результата обратно в список.
1132. Для чего в стримах предназначен метод limit()?
Метод limit() в Java Stream API используется для ограничения количества элементов в стриме. Он принимает целочисленный аргумент, который задает максимальное количество элементов, которые должны быть доступны в стриме. Например, если вы хотите получить только первые 10 элементов из стрима, вы можете использовать следующий код:
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12);
List<Integer> limitedList = list.stream()
.limit(10)
.collect(Collectors.toList());
Здесь list - это список чисел, а limitedList - это список, содержащий только первые 10 элементов из исходного списка.
Этот метод может быть очень полезен, если вам не нужны все элементы в стриме, а только небольшое подмножество из него. Он также может увеличить производительность вашего кода, поскольку не нужно обрабатывать все элементы из стрима.
1133. Для чего в стримах предназначен метод sorted()?
Метод sorted() в потоках (streams) Java предназначен для сортировки элементов потока. Этот метод может принимать один аргумент - компаратор (comparator), который определяет порядок сортировки. Если компаратор не указан, то элементы сортируются в естественном порядке исходного типа элементов.
Например, если у нас есть поток целых чисел, мы можем отсортировать его таким образом:
List<Integer> list = Arrays.asList(3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5);
list.stream()
.sorted()
.forEach(System.out::println);
Это выведет отсортированный список чисел.
Также, если у нас есть поток объектов, мы можем использовать компаратор для сортировки по нескольким полям объекта:
List<Person> people = Arrays.asList(
new Person("John", 20),
new Person("Jane", 23),
new Person("John", 40),
new Person("Jane", 30)
);
people.stream()
.sorted(Comparator.comparing(Person::getName).thenComparing(Person::getAge))
.forEach(System.out::println);
Это отсортирует список людей сначала по имени, а затем по возрасту.
1134. Для чего в стримах предназначены методы flatMap(), flatMapToInt(), flatMapToDouble(), flatMapToLong()?
Методы flatMap(), flatMapToInt(), flatMapToDouble(), flatMapToLong() в Java Stream API используются для выполнения операций преобразования элементов стрима в новый стрим и объединения результатов в один выходной стрим.
В частности, метод flatMap() может быть использован для преобразования каждого элемента стрима в другой стрим, после чего результаты объединяются в единый выходной стрим. Это может быть полезно, когда у вас есть коллекция объектов, каждый из которых может содержать несколько элементов, и вы хотите обрабатывать все элементы, независимо от количества элементов в каждом объекте.
Например, предположим, что у вас есть коллекция списков чисел, и вы хотите получить новый стрим, содержащий все числа из всех списков. Вы можете сделать это, используя метод flatMap() следующим образом:
List<List<Integer>> numbers = Arrays.asList(
Arrays.asList(1, 2, 3),
Arrays.asList(4, 5, 6),
Arrays.asList(7, 8, 9)
);
List<Integer> allNumbers = numbers.stream()
.flatMap(List::stream)
.collect(Collectors.toList());
// allNumbers now contains [1, 2, 3, 4, 5, 6, 7, 8, 9]
Методы flatMapToInt(), flatMapToDouble(), и flatMapToLong() работают аналогично, но возвращают специализированные стримы для каждого типа данных соответственно: IntStream, DoubleStream, и LongStream.
1135.Расскажите о параллельной обработке в Java 8.
В Java 8 была введена возможность использовать параллельную обработку в Stream API. Это означает, что различные операции с элементами потока могут быть выполнены параллельно, что может привести к более быстрой обработке данных, особенно на больших наборах данных.
Например, чтобы обработать большой поток данных в несколько потоков, вы можете использовать метод parallelStream() вместо stream() для получения параллельного потока. Затем вы можете использовать методы, такие как map() и filter(), чтобы обработать каждый элемент потока параллельно.
Вот простой пример, показывающий, как использовать параллельную обработку в Java 8:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
long sum = numbers.parallelStream()
.filter(n -> n % 2 == 0)
.mapToInt(Integer::intValue)
.sum();
System.out.println("Sum of even numbers: " + sum);
Этот код создает список целых чисел, а затем использует параллельный поток для фильтрации только четных чисел и подсчета их суммы.
Например, можно создать поток из списка строк и выполнить фильтрацию элементов, оставив только те строки, которые содержат определенный символ, параллельно следующим образом:
List<String> strings = ...;
strings.parallelStream()
.filter(s -> s.contains("a"))
.forEach(System.out::println);
Важно заметить, что использование параллельной обработки подходит только тогда, когда операции над элементами достаточно сложные и их выполнение занимает много времени. В противном случае, использование параллельной обработки может только замедлить выполнение программы из-за дополнительных затрат на создание и управление потоками.
1136. Какие конечные методы работы со стримами вы знаете?
На Java 8, Stream API предоставляет много конечных методов, таких как:
forEach(): применяет заданное действие к каждому элементу стрима.count(): возвращает количество элементов в стриме.min(): возвращает наименьший элемент в стриме с использованием заданного компаратора, если он задан.max(): возвращает наибольший элемент в стриме с использованием заданного компаратора, если он задан.reduce(): выполняет последовательное сокращение стрима с помощью заданной функции.collect(): выполняет накопление элементов стрима в некоторый контейнер или объект.findFirst(): возвращает первый элемент в стриме.findAny(): возвращает любой элемент в стриме, если он существует.toArray()- возвращает массив элементов стрима;anyMatch() / allMatch() / noneMatch()- проверяют, удовлетворяет ли хотя бы один / все / ни один из элементов стрима заданному предикату.
1137. Какие промежуточные методы работы со стримами вы знаете?
В Java 8 Stream API есть множество методов для промежуточной обработки данных в потоке. Некоторые из этих методов включают в себя:
filter(Predicate<T> predicate)- выбирает только те элементы потока , которые удовлетворяют предикатуmap(Function<T, R> mapper)- применяет функцию к каждому элементу потока и возвращает поток, состоящий из результатовflatMap(Function<T, Stream<R>> mapper)- применяет функцию к каждому элементу потока и получает поток из каждого результата, а затем объединяет все полученные потоки в один выходной потокdistinct()- удаляет дубликаты элементов в потокеsorted()- сортирует элементы потока по их естественному порядкуpeek(Consumer<T> action)- выполняет заданный action для каждого элемента потока, сохраняя при этом элементы в потокеskip(): пропускает первые n элементов стрима.
Вот пример с использованием некоторых промежуточных методов:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = numbers.stream()
.filter(n -> n % 2 == 0)
.map(n -> n * 2)
.distinct()
.collect(Collectors.toList());
Этот код создает список чисел, затем создает поток из списка чисел и фильтрует только четные числа, умножает их на 2, удаляет любые дубликаты и сохраняет результаты в новом списке.
Вот пример чтобы отфильтровать элементы списка list по условию, можно использовать метод filter() следующим образом:
List<Integer> filteredList = list.stream()
.filter(num -> num > 5)
.collect(Collectors.toList());
Этот код создает стрим элементов списка list, фильтрует элементы, оставляя только те, которые больше 5, и сохраняет результат в новый список filteredList.
1138. Как вывести на экран 10 случайных чисел, используя forEach()?
Чтобы сгенерировать 10 случайных чисел с помощью потоков Java и forEach(), вы можете сначала использовать класс IntStream из пакета java.util.stream для генерации потока случайных целых чисел. Затем вы можете использовать метод limit(), чтобы указать, что вам нужны только 10 случайных чисел, и, наконец, использовать forEach() для вывода каждого из случайных чисел на консоль. Вот пример фрагмента кода, который демонстрирует, как это сделать:
import java.util.Random;
import java.util.stream.IntStream;
public class RandomNumbers {
public static void main(String[] args) {
Random random = new Random();
IntStream randomNumbers = random.ints().limit(10);
randomNumbers.forEach(System.out::println);
}
}
Этот код сгенерирует 10 случайных целых чисел и выведет их на консоль с помощью метода forEach(). Обратите внимание, что мы используем ссылку на метод System.out::println в качестве аргумента для метода forEach(). Это эквивалентно x -> System.out.println(x) и позволяет нам писать более лаконичный код.
1139. Как можно вывести на экран уникальные квадраты чисел используя метод map()?
Чтобы напечатать уникальные квадраты чисел с помощью метода map() в потоках Java, вы можете сначала использовать метод map() для получения квадратов чисел, а затем использовать метод distinct() для получения только уникальных квадратов. Вот пример фрагмента кода:
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 3, 3);
numbers.stream()
.map(n -> n * n)
.distinct()
.forEach(System.out::println);
Этот код выведет уникальные квадраты чисел в списке чисел: 1, 4, 9. Обратите внимание, что необходимо вызвать метод distinct() для фильтрации дубликатов, чтобы получить только уникальные квадраты.
1140. Как вывести на экран количество пустых строк с помощью метода filter()?
Чтобы вывести количество пустых строк с помощью метода filter() в Java Stream, вы можете сделать что-то вроде этого:
List<String> stringList = Arrays.asList("a", "", "b", "", "", "c");
long count = stringList.stream()
.filter(str -> str.isEmpty())
.count();
System.out.println("Number of empty strings: " + count);
В этом примере у меня есть список строк, и я использую метод stream() класса List для создания потока. Затем я использую метод filter() для фильтрации всех пустых строк в списке. str -> str.isEmpty() — это лямбда-выражение, которое возвращает true, если строка пуста. Метод count() возвращает количество элементов в потоке после операции фильтрации. Наконец, я вывожу счет на консоль. Этот код выведет: Количество пустых строк: 3.
1141. Как вывести на экран 10 случайных чисел в порядке возрастания?
Чтобы вывести 10 случайных чисел в порядке возрастания с использованием потоков Java, вы можете использовать метод sorted() после генерации чисел с использованием метода limit() и Random.ints(). Вот пример фрагмента кода:
import java.util.Random;
public class Main {
public static void main(String[] args) {
Random random = new Random();
random.ints(10)
.limit(10)
.sorted()
.forEach(System.out::println);
}
}
Этот код использует метод ints() класса Random для генерации потока случайных целых чисел, а затем применяет limit(10) для ограничения размера потока до 10 элементов и sorted() для сортировки оставшихся элементов в порядке возрастания. Наконец, forEach() используется для печати элементов.
Чтобы сгенерировать 10 случайных чисел и распечатать их в порядке убывания с помощью Java Stream API, вы можете использовать следующий код:
import java.util.stream.*;
import java.util.*;
public class RandomNumbers {
public static void main(String[] args) {
Random random = new Random();
IntStream.generate(random::nextInt)
.limit(10)
.boxed()
.sorted(Comparator.reverseOrder())
.forEach(System.out::println);
}
}
1142. Как найти максимальное число в наборе?
Для поиска максимального числа в наборе с помощью Stream API в Java 8 можно использовать метод max() с помощью оператора lambda, который сравнивает элементы. Пример:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] nums = {2, 8, 1, 6, 10};
int maxNum = Arrays.stream(nums)
.max()
.getAsInt();
System.out.println("Максимальное число: " + maxNum);
}
}
Результат выполнения программы будет следующим:
Максимальное число: 10
1143. Как найти минимальное число в наборе?
Для того, чтобы найти минимальное число в наборе с помощью Stream API в Java, можно использовать метод min():
int[] numbers = {5, 8, 3, 12, 9};
int min = Arrays.stream(numbers).min().getAsInt();
System.out.println(min);
В этом примере мы создаем массив numbers, затем используем метод Arrays.stream() для создания потока чисел из массива. Метод min() возвращает минимальное значение в потоке, а метод getAsInt() преобразует результат в примитивный тип int. Метод println() выводит результат на экран.
Если элементы в потоке являются объектами, а не примитивами, то можно также использовать метод Comparator.comparing() для указания функции сравнения, по которой будет определяться порядок. Например:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Dave");
String shortestName = names.stream()
.min(Comparator.comparing(String::length))
.orElse("");
System.out.println(shortestName);
В этом примере мы создаем список names, затем используем метод stream() для создания потока строк из списка. Метод min() принимает функцию сравнения, которая сравнивает длину строк, а метод orElse() возвращает пустую строку в случае, если поток пустой. Метод println() выводит результат на экран.
Можно использовать также метод .reduce() чтобы получить минимальное значение в потоке. Например:
int[] numbers = {5, 8, 3, 12, 9};
int min = Arrays.stream(numbers).reduce(Integer.MAX_VALUE, (a, b) -> Integer.min(a, b));
System.out.println(min);
В этом примере мы используем метод reduce() для свертки потока в единое значение. Метод Integer.min() используется для сравнения двух чисел и возврата минимального из них.
1144. Как получить сумму всех чисел в наборе?
Для получения суммы всех чисел в наборе при использовании Java Stream API можно использовать метод sum() после промежуточной операции mapToInt().
Вот пример кода:
int sum = IntStream.of(1, 2, 3, 4, 5)
.sum();
System.out.println(sum); // Вывод: 15
Если количество элементов в потоке больше, то можно использовать метод reduce() вместе с оператором суммирования +, как показано ниже:
int sum = IntStream.rangeClosed(1, 10)
.reduce(0, Integer::sum);
System.out.println(sum); // Вывод: 55
Здесь метод rangeClosed() создает поток целых чисел от 1 до 10 включительно, а метод reduce() выполняет операцию суммирования начиная с элемента нейтрального значения 0.
Эти же методы могут быть использованы и с другими типами данных, например, LongStream или DoubleStream, в зависимости от требований вашего кода.
1145. Как получить среднее значение всех чисел?
Для получения среднего значения всех чисел в Java Stream можно использовать метод average() после вызова stream() на коллекции чисел. Например:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
double average = numbers.stream()
.mapToDouble(val -> val) // преобразуем Integer в double
.average()
.orElse(Double.NaN);
System.out.println("Среднее значение: " + average);
Этот код выведет:
Среднее значение: 3.0
Обратите внимание на использование orElse(Double.NaN) после вызова average() . Это нужно для того, чтобы получить значение среднего, даже если коллекция пуста. Если коллекция пуста, метод average() вернет пустой OptionalDouble, и мы используем orElse для получения значения NaN.
1146. Какие дополнительные методы для работы с ассоциативными массивами (maps) появились в Java 8
В Java 8 для работы с ассоциативными массивами (maps) был добавлен ряд дополнительных методов:
forEach()- позволяет выполнять заданное действие для каждой пары ключ-значение в мапе.replace(key, oldValue, newValue)- заменяет значение oldValue на newValue для заданного ключа key, только если oldValue соответствует текущему значению ключа.replaceAll()- заменяет каждое значение в мапе используя определенную функцию.compute()- позволяет вычислить новое значение для заданного ключа, и заменить старое значением новым вычисленным значением.computeIfAbsent()- позволяет вычислить новое значение для заданного ключа, только если заданный ключ отсутствует в мапе.computeIfPresent()- позволяет вычислить новое значение для заданного ключа, только если заданный ключ присутствует в мапе.merge()- выполняет объединение двух мап с определенной функцией, когда ключ встречается в двух мапах.
Пример использования методов для Map в Java 8:
Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
// forEach method
map.forEach((key, value) -> System.out.println(key + " " + value));
// replace method
map.replace("key1", 1, 100);
// replaceAll method
map.replaceAll((key, oldValue) -> oldValue + 10);
// compute method
map.compute("key2", (key, value) -> value * 2);
// computeIfAbsent method
map.computeIfAbsent("key3", key -> 3);
// computeIfPresent method
map.computeIfPresent("key2", (key, value) -> value * 2);
1147. Что такое LocalDateTime?
LocalDateTime — это класс в пакете java.time, представленный в Java 8, который представляет дату и время без часового пояса, например 2023-05-17T09:24:13. Он сочетает в себе дату и время суток. Это наиболее часто используемый класс для представления и управления значениями даты и времени в Java.
Вот пример того, как использовать LocalDateTime для создания нового экземпляра, представляющего текущую дату и время:
import java.time.LocalDateTime;
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
Это выведет текущую дату и время, как в примере, упомянутом ранее: 2023-05-17T09:24:13. Кроме того, вы можете использовать метод of() для создания объекта LocalDateTime, передавая значения года, месяца, дня, часа, минуты и секунды. Например:
LocalDateTime dateTime = LocalDateTime.of(2023, 5, 17, 9, 30, 0);
Это создаст объект LocalDateTime, представляющий 17 мая 2023 года в 9:30. Имейте в виду, что LocalDateTime представляет только дату и время без часового пояса. Если вам нужно работать с часовыми поясами, вы можете использовать класс ZonedDateTime.
1148. Что такое ZonedDateTime?
ZonedDateTime — это класс в пакете java.time, представленный в Java 8 для представления даты и времени с часовым поясом в календарной системе ISO-8601, например «2007-12-03T10:15:30+01:00[ Европа/Париж].
Он представляет собой точку на временной шкале, обычно представляемую как год-месяц-день-час-минута-секунда-наносекунда, с часовым поясом. Часовой пояс имеет решающее значение для определения фактической точки на глобальной временной шкале. DateTimeKind также поддерживается для совместимости с другими системами.
Этот класс обеспечивает неизменное представление даты и времени с часовым поясом. Он похож на OffsetDateTime, но включает часовой пояс. Его можно использовать для представления определенного момента времени или для преобразования между часовыми поясами.
Вот пример того, как создать экземпляр ZonedDateTime в Java, используя текущее системное время и класс ZoneId для указания идентификатора зоны:
import java.time.ZonedDateTime;
import java.time.ZoneId;
ZonedDateTime zonedDateTime = ZonedDateTime.now(ZoneId.of("Europe/Paris"));
Это создает ZonedDateTime, представляющий текущую дату и время в часовом поясе Европы/Парижа.
1149. Как получить текущую дату с использованием Date Time API из Java 8?
В Java 8 можно использовать класс java.time.LocalDateTime для получения текущей даты и времени. Метод now() этого класса возвращает текущую дату и временные значения. Например, так можно получить текущую дату и время в формате ISO:
import java.time.LocalDateTime;
...
LocalDateTime currentDateTime = LocalDateTime.now();
System.out.println(currentDateTime);
Этот код выведет текущую дату и время в формате ISO, например: 2023-05-17T10:58:20.804
1150. Как добавить 1 неделю, 1 месяц, 1 год, 10 лет к текущей дате с использованием Date Time API?
Для добавления определенного количества времени к текущей дате в Java с использованием Date Time API можно использовать методы класса LocalDate. Например, чтобы добавить 1 неделю, 1 месяц, 1 год и 10 лет, можно использовать следующий код:
import java.time.LocalDate;
public class Main {
public static void main(String[] args) {
// Получаем текущую дату
LocalDate currentDate = LocalDate.now();
// Добавляем 1 неделю
LocalDate nextWeek = currentDate.plusWeeks(1);
// Добавляем 1 месяц
LocalDate nextMonth = currentDate.plusMonths(1);
// Добавляем 1 год
LocalDate nextYear = currentDate.plusYears(1);
// Добавляем 10 лет
LocalDate tenYearsLater = currentDate.plusYears(10);
// Выводим результат
System.out.println("Текущая дата: " + currentDate);
System.out.println("Дата через 1 неделю: " + nextWeek);
System.out.println("Дата через 1 месяц: " + nextMonth);
System.out.println("Дата через 1 год: " + nextYear);
System.out.println("Дата через 10 лет: " + tenYearsLater);
}
}
Этот код создает объекты LocalDate, представляющие текущую дату, дату через 1 неделю, 1 месяц, 1 год и 10 лет. Метод plusWeeks(), plusMonths(), plusYears() используются здесь для добавления соответствующей временной единицы к дате.
1151. Как получить следующий вторник используя Date Time API?
В Java 8 и более поздних версиях вы можете использовать классы java.time для работы с датами и временем. Чтобы получить следующий вторник, можно использовать метод with(TemporalAdjuster), передавая экземпляр класса TemporalAdjusters.next(DayOfWeek.TUESDAY) в качестве параметра. Вот пример кода:
import java.time.DayOfWeek;
import java.time.LocalDate;
import java.time.temporal.TemporalAdjusters;
public class Main {
public static void main(String[] args) {
LocalDate date = LocalDate.now();
LocalDate nextTuesday = date.with(TemporalAdjusters.next(DayOfWeek.TUESDAY));
System.out.println("Next Tuesday is: " + nextTuesday);
}
}
Этот код создает объект LocalDate, который представляет сегодняшнюю дату, а затем использует метод with(TemporalAdjuster), чтобы получить следующий вторник. Затем он просто выводит эту дату на экран.
1152. Как получить вторую субботу текущего месяца используя Date Time API?
1153. Как получить текущее время с точностью до миллисекунд используя Date Time API?
В Java 8 и более поздних версиях можно использовать класс Instant и метод now() для получения текущего момента времени с точностью до миллисекунд. Вот пример:
import java.time.Instant;
Instant now = Instant.now();
System.out.println(now);
Это выведет на экран текущий момент времени в формате ISO-8601, включая день, время и миллисекунды в формате UTC.
Если вам нужно представить время в другом формате, например, в часах, минутах и секундах, вы можете использовать класс LocalDateTime и метод now():
import java.time.LocalDateTime;
LocalDateTime now = LocalDateTime.now();
System.out.println(now);
Это выведет на экран текущее время в формате 2023-05-20T12:30:45.123.
Обратите внимание, что в Java 8 и более поздних версиях классы Date и Calendar считаются устаревшими, и рекомендуется использовать новые классы из пакета java.time для работы с датами и временем.
1154. Как получить текущее время по местному времени с точностью до миллисекунд используя Date Time API?
В Java 8 и выше для получения текущего времени с точностью до миллисекунд рекомендуется использовать класс LocalDateTime из java.time пакета (Date Time API):
import java.time.LocalDateTime;
LocalDateTime time = LocalDateTime.now();
System.out.println(time);
Это выведет текущее локальное время в формате по умолчанию, например: 2023-05-18T09:16:37.124.
Вы также можете использовать DateTimeFormatter для форматирования времени в строку с нужным форматом. Например, чтобы получить время в формате "HH:mm:ss.SSS", вы можете сделать так:
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
LocalDateTime time = LocalDateTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss.SSS");
String formattedTime = time.format(formatter);
System.out.println(formattedTime);
Это выведет текущее время в формате "часы:минуты:секунды.миллисекунды", например: 09:16:37.124.
Обратите внимание, что для установки часового пояса используйте метод atZone или atOffset.
1155. Как определить повторяемую аннотацию?
Для того чтобы создать повторяемую аннотацию в Java, необходимо использовать аннотацию @Repeatable, которая в качестве параметра принимает класс-контейнер, содержащий одну или несколько аннотаций необходимого типа.
Пример объявления повторяемой аннотации:
@Repeatable(MyAnnotations.class)
public @interface MyAnnotation {
String value();
}
где MyAnnotations - это класс-контейнер, содержащий одну или несколько аннотаций @MyAnnotation.
Пример использования повторяемой аннотации:
@MyAnnotation("value1")
@MyAnnotation("value2")
public class MyClass {
// Код класса
}
где аннотации @MyAnnotation("value1") и @MyAnnotation("value2") могут быть сгруппированы в одну аннотацию-контейнер @MyAnnotations.
Для получения всех аннотаций-контейнеров необходимо использовать метод getAnnotationsByType(Class annotationClass) класса Class. Например:
MyAnnotation[] annotations = MyClass.class.getAnnotationsByType(MyAnnotation.class);
Кроме того, в Java 8 был добавлен интерфейс java.lang.annotation.Repeatable, который позволяет объявлять повторяемые аннотации без явного использования класса-контейнера. Пример использования данного интерфейса аналогичен примеру выше.
1156. Что такое jjs?
jjs — это инструмент командной строки, входящий в комплект Java Development Kit (JDK), начиная с версии 8. Он позволяет выполнять код JavaScript из командной строки с доступом к классам и методам Java. Инструмент jjs основан на движке Nashorn JavaScript. Его можно использовать для тестирования, автоматизации и других целей, требующих интеграции JavaScript и Java. С помощью jjs вы можете выполнять код JavaScript из файла или непосредственно из командной строки. Вы также можете интерактивно запускать код JavaScript с помощью оболочки jjs.
1157. Какой класс появился в Java 8 для кодирования/декодирования данных?
В Java 8 был добавлен класс Base64 в пакет java.util для кодирования и декодирования данных в формате Base64. Этот класс содержит два статических класса - Encoder для кодирования данных и Decoder для декодирования данных. Для использования необходимо импортировать класс Base64 использованием директивы импорта: import java.util.Base64;.
Пример кодирования и декодирования данных в Base64 в Java 8 с использованием класса Base64:
import java.util.Base64;
public class Main {
public static void main(String[] args) {
String originalString = "Hello, world!";
// Encoding a string to Base64
String encodedString = Base64.getEncoder().encodeToString(originalString.getBytes());
System.out.println("Encoded string: " + encodedString);
// Decoding a Base64 string
byte[] decodedBytes = Base64.getDecoder().decode(encodedString);
String decodedString = new String(decodedBytes);
System.out.println("Decoded string: " + decodedString);
}
}
Вывод программы:
Encoded string: SGVsbG8sIHdvcmxkIQ==
Decoded string: Hello, world!
Например, чтобы закодировать массив байтов в строку Base64, можно использовать следующий код:
byte[] byteArray = {1, 2, 3};
Base64.Encoder encoder = Base64.getEncoder();
String encodedString = encoder.encodeToString(byteArray);
А чтобы декодировать строку Base64 обратно в массив байтов, можно использовать следующий код:
Base64.Decoder decoder = Base64.getDecoder();
byte[] decodedByteArray = decoder.decode(encodedString);
Для этих операций также можно использовать статические методы класса java.util.Base64, например, для кодирования:
byte[] byteArray = {1, 2, 3};
String encodedString = Base64.getEncoder().encodeToString(byteArray);
и для декодирования:
byte[] decodedByteArray = Base64.getDecoder().decode(encodedString);
1158. Как создать Base64 кодировщик и декодировщик?
Для создания кодировщика и декодировщика Base64 на Java, можно использовать классы Base64 и Base64.Decoder / Base64.Encoder, доступные в Java 8 и выше. Вот примеры:
Кодировщик:
import java.util.Base64;
String originalInput = "hello world";
String encodedString = Base64.getEncoder().encodeToString(originalInput.getBytes());
System.out.println("Encoded string: " + encodedString);
Это создаст закодированную строку "hello world" в Base64.
Декодировщик:
import java.util.Base64;
String encodedString = "aGVsbG8gd29ybGQ=";
byte[] decodedBytes = Base64.getDecoder().decode(encodedString);
String decodedString = new String(decodedBytes);
System.out.println("Decoded string: " + decodedString);
Это декодирует закодированную строку "aGVsbG8gd29ybGQ=" обратно в исходную строку "hello world".
Обратите внимание, что классы Base64 и Base64.Decoder / Base64.Encoder доступны только в Java 8 и выше.
к оглавлению
10. Java Core (перейти в раздел)
1159. Чем различаются JRE, JVM и JDK?
В языке программирования Java JRE, JVM и JDK - это различные компоненты, которые предоставляют среду выполнения, в которой работают Java-приложения.
JRE (Java Runtime Environment) - это среда выполнения Java , которая включает в себя Java Virtual Machine (JVM) и библиотеки классов Java. JRE нужна для запуска уже скомпилированных Java-приложений. JRE не включает в себя никаких инструментов разработки.
JVM (Java Virtual Machine) - это виртуальная машина , которая запускает Java-приложения, представленные в виде байт-кода. Байт-код - это машинно-независимый код, который может быть скомпилирован на любой платформе. JVM интерпретирует байт-код и выполняет Java-приложения.
JDK (Java Development Kit) - это комплект разработчика Java , который включает в себя JRE, компилятор Java (javac), различные инструменты разработки (например, дебаггер) и библиотеки классов Java. JDK используется, когда вы хотите разрабатывать Java-приложения.
Итак, JRE используется для запуска Java-приложений, JVM - для выполнения Java-приложений, а JDK - для разработки Java-приложений.
1160. Какие существуют модификаторы доступа?
В Java есть четыре модификатора доступа, которые определяют, как другие классы и модули могут получить доступ к полям и методам класса:
public - поля и методы, помеченные как public, могут быть доступны из любого класса или модуля.
private - поля и методы, помеченные как private, могут быть использованы только внутри класса, в котором они были определены.
protected - поля и методы, помеченные как protected, могут быть использованы внутри класса, в котором они были определены, и в подклассах этого класса.
По умолчанию - поля и методы, которые не помечены явным модификатором доступа, могут быть использованы только внутри того же класса и пакета, в котором они были определены.
Пример использования модификаторов доступа в Java:
public class MyClass {
public int publicField;
private int privateField;
protected int protectedField;
int defaultField;
public void publicMethod() {
// Код метода
}
private void privateMethod() {
// Код метода
}
protected void protectedMethod() {
// Код метода
}
void defaultMethod() {
// Код метода
}
}
1161. О чем говорит ключевое слово final?
Ключевое слово final в Java используется для обозначения, что значение переменной или ссылки на объект не может быть изменено после инициализации.
Если переменная объявлена с ключевым словом final, она должна быть проинициализирована при объявлении или в конструкторе объекта, и ее значение не может быть изменено. Кроме того, ключевое слово final может быть использовано для объявления констант класса.
Ключевое слово final также может использоваться для стабилизации поведения методов, так что они не могут быть переопределены в подклассах.
В целом, ключевое слово final позволяет заблокировать позицию в памяти, которую занимает переменная или константа, и гарантировать, что ее значение не изменится.
Некоторые из возможных использований ключевого слова final:
- Декларация констант
- Декларация локальных переменных
- Аргументы методов
- Декларация полей классов
- Декларация классов
например:
public class Example {
public static final int CONSTANT_VALUE = 100;
private final String immutableField;
public Example(String value) {
this.immutableField = value;
}
public final void finalMethod() {
// method logic here
}
}
В этом примере, CONSTANT_VALUE является константой (final static field), immutableField является изменяемым final полем (final instance field), finalMethod является final методом и не может быть переопределен в подклассах.
1162. Какими значениями инициализируются переменные по умолчанию?
В Java переменные класса (статические переменные) и переменные экземпляра (не статические переменные) инициализируются автоматически значениями по умолчанию, если им не присвоено явное начальное значение. Значения по умолчанию зависят от типа переменной. Вот некоторые замечания о значениях по умолчанию в Java:
- Целочисленные типы (byte, short, int, long) инициализируются нулём (0).
- Числа с плавающей точкой (float, double) инициализируются нулём, но это специфично для Java 8 и выше.
- Логические типы (boolean) инициализируются значением false.
- Ссылочные типы (Object, массивы, строки и т. д.) инициализируются значением null.
Например, такие переменные без явно заданного начального значения будут иметь значения по умолчанию:
public class MyClass {
// Переменные экземпляра
int myInt;
String myString;
// Переменные класса
static boolean myBoolean;
public static void main(String[] args) {
MyClass obj = new MyClass();
System.out.println(obj.myInt); // Выводит 0
System.out.println(obj.myString); // Выводит null
System.out.println(MyClass.myBoolean); // Выводит false
}
}
1163. Что вы знаете о функции main()?
Функция main() является точкой входа в программу на языке Java. Это означает, что код внутри функции main() начинает выполняться при запуске программы.
Функция main() должна быть объявлена в классе, который определяет основную логику приложения. Обычно этот класс называется Main или App, например:
public class Main {
public static void main(String[] args) {
// your code here
}
}
Функция main() принимает аргументы командной строки в виде массива строк . Эти аргументы используются для передачи входных данных в программу при ее запуске. Например, чтобы передать аргументы arg1 и arg2 при запуске программы, нужно ввести следующую команду в консоли:
java Main arg1 arg2
Функция main() возвращает тип void, то есть ничего не возвращает. Она просто выполняет код внутри себя и завершает программу.
Наличие функции main() является обязательным для запуска программы на языке Java.
1164. Какие логические операции и операторы вы знаете?
В Java есть несколько логических операций и операторов:
&& (логическое И)- возвращает true, если оба операнда являются true|| (логическое ИЛИ)- возвращает true, если хотя бы один операнд является true! (логическое НЕ)- инвертирует значение операнда (если значение true, то результат будет false, и наоборот)
Этот список не является исчерпывающим, и также могут быть использованы операторы сравнения (>, <, ==, != и т.д.) вместе с логическими операциями.
Примеры использования:
boolean a = true;
boolean b = false;
System.out.println(a && b); // false
System.out.println(a || b); // true
System.out.println(!a); // false
Этот код выводит результаты логических операций между переменными a и b, а также результат инвертирования значения переменной a.
1165. Что такое тернарный оператор выбора?
Тернарный оператор выбора (Ternary Operator) в Java - это сокращенная форма записи оператора if-else. Он позволяет записывать условную операцию в одну строку, что может сделать код более читабельным и экономить место.
Синтаксис тернарного оператора выбора:
variable = (condition) ? expressionTrue : expressionFalse;
Если condition является истиной, то expressionTrue будет возвращено, иначе expressionFalse.
Пример использования тернарного оператора выбора:
int age = 20;
String message = age >= 18 ? "Взрослый" : "Ребенок";
System.out.println(message);
Этот код проверяет, является ли age больше или равным 18, и в зависимости от результата присваивает переменной message значение "Взрослый" или "Ребенок". Если age равен 20, то будет выведено "Взрослый".
Но следует использовать тернарный оператор выбора с умом, так как его чрезмерное использование может сделать код сложным и трудным для понимания, особенно при использовании вложенных тернарных операторов выбора.
1166. Какие побитовые операции вы знаете?
В Java доступны следующие побитовые операции:
- Побитовое "и" - &
- Побитовое "или" - |
- Побитовое "исключающее или" - ^
- Побитовый сдвиг вправо - >>
- Побитовый сдвиг вправо с заполнением старших бит нулями - >>>
- Побитовый сдвиг влево - <<
- Побитовое отрицание - ~
Примеры использования:
int a = 5; // 101 в двоичной системе
int b = 3; // 011 в двоичной системе
int c = a & b; // побитовое "и" - 001 в двоичной системе (1 в десятичной системе)
int d = a | b; // побитовое "или" - 111 в двоичной системе (7 в десятичной системе)
int e = a ^ b; // побитовое "исключающее или" - 110 в двоичной системе (6 в десятичной системе)
int f = a >> 1; // побитовый сдвиг вправо на 1 бит - 010 в двоичной системе (2 в десятичной системе)
int g = a << 2; // побитовый сдвиг влево на 2 бита - 10100 в двоичной системе (20 в десятичной системе)
int h = ~a; // побитовое отрицание - 111...111010 в двоичной системе (-6 в десятичной системе)
1167. Где и для чего используется модификатор abstract?
Модификатор abstract в Java применяется для создания абстрактных классов и методов. Абстрактный класс - это класс, который не может быть создан напрямую, а должен быть унаследован другим классом, который реализует все его абстрактные методы. Абстрактный метод не имеет реализации, но обычно содержит только объявление метода, указывающее тип возвращаемого значения, имя метода и список параметров.
Использование abstract является частью концепции наследования в ООП, позволяя создавать классы с общими методами, которые могут быть дополнены и переопределены в дочерних классах. Абстрактные классы и методы также могут быть использованы для определения интерфейсов и даже применения полиморфизма.
Пример создания абстрактного класса в Java:
abstract class MyAbstractClass {
// абстрактный метод
public abstract void myAbstractMethod();
// обычный метод
public void myMethod() {
System.out.println("Это обычный метод в абстрактном классе.");
}
}
Обратите внимание, что абстрактный класс содержит один абстрактный метод и один обычный метод. Дочерние классы, которые наследуются от этого класса, должны реализовать абстрактный метод.
1168. Дайте определение понятию «интерфейс». Какие модификаторы по умолчанию имеют поля и методы интерфейсов?
В Java интерфейс - это абстрактный тип, который содержит только абстрактные методы или константы (final static поля). Он описывает набор методов, которые должен реализовать любой класс, который реализует этот интерфейс.
Модификаторы доступа по умолчанию для полей и методов в интерфейсах - это public. Это означает, что методы и поля доступны из любого места в программе. Константы в интерфейсах являются неизменяемыми (immutable).
Пример определения интерфейса в Java:
public interface MyInterface {
// объявление константы
int MAX_COUNT = 100;
// объявление абстрактного метода
void doSomething();
// объявление метода с реализацией по умолчанию
default void doSomethingElse() {
// реализация метода
}
}
Этот интерфейс определяет два абстрактных метода, которые должен реализовать любой класс, который реализует этот интерфейс. Методы имеют модификатор доступа public по умолчанию.
1169. Чем абстрактный класс отличается от интерфейса? В каких случаях следует использовать абстрактный класс, а в каких интерфейс?
Абстрактный класс и интерфейс - это два механизма, которые позволяют определять абстрактные типы данных и описывать методы, которые должны быть доступны в классах, реализующих эти интерфейсы или расширяющих эти абстрактные классы.
Абстрактный класс - это класс, который определяет хотя бы один абстрактный метод. Абстрактные методы - это методы без тела, которые должны быть переопределены в подклассах, чтобы дать им конкретную реализацию. Кроме того, абстрактный класс может иметь и конкретные методы с телом.
Интерфейс - это коллекция абстрактных методов, которая определяет действия (методы), которые реализующий класс обязуется поддерживать. В интерфейсах все методы по умолчанию абстрактные и не имеют тела. Кроме того, интерфейс может определять константы.
Основное отличие между абстрактным классом и интерфейсом заключается в том, что абстрактный класс может содержать реализацию методов, а интерфейс может иметь только абстрактные методы - т.е. методы без тела. Кроме того, класс может расширять только один абстрактный класс, но он может реализовывать несколько интерфейсов.
Когда следует использовать абстрактный класс, а когда интерфейс, зависит от конкретной ситуации. Если вы хотите определить классы с общей функциональностью, используйте абстрактный класс. Если же вам нужно определить только набор методов, которые должны быть реализованы, используйте интерфейс. Кроме того, если вам нужно добавить общую функциональность в существующие классы, лучше использовать абстрактный класс, а если вам нужно добавить новые методы, лучше использовать интерфейс.
Когда использовать абстрактный класс:
- Когда требуется предоставить базовую реализацию для нескольких классов.
- Когда требуется определить общие поля и методы для нескольких классов.
- Когда требуется использовать модификаторы доступа, отличные от public, для методов и полей.
Когда использовать интерфейс:
- Когда требуется определить только сигнатуры методов без их реализации.
- Когда требуется реализовать множество несвязанных классов с общими методами.
- Когда требуется достичь множественного наследования.
1170. Почему в некоторых интерфейсах вообще не определяют методов?
В Java есть такой концепт как "маркерный интерфейс" (marker interface). Это интерфейс, который не имеет методов. Его основное предназначение - помечать классы, чтобы это имело какой-то эффект на уровне компиляции или рантайма.
Например, маркерный интерфейс java.io.Serializable не определяет методов, он просто указывает компилятору и JVM, что класс, который его реализует, может быть сериализован (т.е. его объекты могут быть преобразованы в поток байтов и обратно), и нужно выполнить некоторые действия в рантайме, чтобы это было возможно.
Это может быть полезным для некоторых шаблонов проектирования, например, паттерн "Наблюдатель" может использовать маркерный интерфейс для определения, что классы подписчиков могут быть уведомлены об изменениях в издателе.
В целом, использование маркерных интерфейсов - это выбор дизайнера API, и они не обязательны для всех случаев. Маркерный интерфейс может быть полезен, если вам нужно указать наличие некоторого свойства или функции у класса или объекта, не давая им реальной реализации.
1171. Почему нельзя объявить метод интерфейса с модификатором final?
Модификатор final означает, что значение переменной не может изменяться после инициализации. В интерфейсах все поля неявно являются public, static и final. Таким образом, в интерфейсах все переменные уже являются константами и не могут изменять свои значения после инициализации.
Методы интерфейсов, с другой стороны, не могут иметь тела и не могут содержать код. Они просто определяют сигнатуру метода, который должен быть реализован в классе, который реализует интерфейс. Не имеет смысла объявлять методы интерфейса с модификатором final потому, что они не могут быть реализованы в интерфейсе и должны быть реализованы в классе, который реализует этот интерфейс.
Итак, объявление метода интерфейса как final не имеет смысла и не разрешено в Java.
1172. Что имеет более высокий уровень абстракции - класс, абстрактный класс или интерфейс?
Интерфейс имеет более высокий уровень абстракции, чем абстрактный класс и класс в Java. В интерфейсе нет реализации методов, только их объявления, тогда как абстрактный класс может иметь как абстрактные методы, так и методы с реализацией. Обычный класс в Java имеет полную реализацию методов и может создавать объекты, тогда как интерфейс и абстрактный класс не могут. Интерфейс также может наследовать от других интерфейсов и классов, что делает его еще более гибким в использовании.
1173. Может ли объект получить доступ к члену класса, объявленному как private? Если да, то каким образом?
В Java объект не имеет доступа к члену класса, объявленному как private. Только члены класса могут иметь доступ к такому приватному члену, кроме случаев, когда метод класса делает его общедоступным (public) или доступным в рамках пакета (package-private).
Однако, можно создать public метод в классе, который будет использовать приватный член класса в своей реализации, и тогда объекты этого класса будут иметь доступ к приватному члену через этот public метод. Например:
public class MyClass {
private int privateField;
public void setPrivateField(int value) {
this.privateField = value;
}
public int getPrivateField() {
return this.privateField;
}
}
В этом примере поле privateField объявлено как private, но есть два public метода setPrivateField и getPrivateField, которые работают с этим приватным полем и позволяют устанавливать и получать его значение извне.
Также следует отметить, что внутри класса можно создавать объект другого класса, у которого есть приватные поля и методы, и работать с ними. Однако доступ к таким членам класса будет закрыт при попытке вызова их извне, вне класса, где они объявлены.
1174. Каков порядок вызова конструкторов и блоков инициализации с учётом иерархии классов?
При создании экземпляра объекта в Java, конструкторы и блоки инициализации выполняются в определенном порядке, который зависит от иерархии классов и типа блока инициализации.
Порядок инициализации объекта следующий:
Статические блоки инициализации базового классаСтатические блоки инициализации производного классаНе статические блоки инициализации базового классаКонструктор базового классаНе статические блоки инициализации производного классаКонструктор производного класса
Пример иерархии классов и порядка инициализации:
class Base {
static {
System.out.println("Static initialization block of Base");
}
{
System.out.println("Instance initialization block of Base");
}
Base() {
System.out.println("Constructor of Base");
}
}
class Derived extends Base {
static {
System.out.println("Static initialization block of Derived");
}
{
System.out.println("Instance initialization block of Derived");
}
Derived() {
System.out.println("Constructor of Derived");
}
}
public class Main {
public static void main(String[] args) {
new Derived();
}
}
Результат выполнения кода:
Static initialization block of Base
Static initialization block of Derived
Instance initialization block of Base
Constructor of Base
Instance initialization block of Derived
Constructor of Derived
Таким образом, статические блоки инициализации выполняются первыми, затем не статические блоки инициализации, а затем конструкторы. При этом порядок выполнения блоков инициализации и конструкторов определяется иерархией классов.
1175. Зачем нужны и какие бывают блоки инициализации?
Блоки инициализации (initialization blocks) в Java используются для инициализации переменных класса и других статических компонентов, в том числе для установки значений по умолчанию, создания экземпляров класса, вызова методов и работы с исключениями. Бывают два типа блоков инициализации: статические (static) и нестатические (instance).
Статические блоки инициализации выполняются при загрузке класса в JVM (Java Virtual Machine), до создания его объектов. Они используются для инициализации статических полей класса.
Нестатические блоки инициализации выполняются при создании объекта класса, перед выполнением конструктора. Они используются для присваивания начальных значений полей объекта, которые не могут быть установлены при объявлении поля.
Вот пример, демонстрирующий использование статических и нестатических блоков инициализации в Java:
public class MyClass {
static int staticVar;
int instanceVar;
static {
// статический блок инициализации
staticVar = 10;
System.out.println("Static initialization block");
}
{
// нестатический блок инициализации
instanceVar = 20;
System.out.println("Instance initialization block");
}
public MyClass() {
// конструктор
System.out.println("Constructor");
}
}
// создание объекта класса
MyClass obj = new MyClass();
При выполнении этого кода будет выведено:
Static initialization block
Instance initialization block
Constructor
Это означает, что сначала был выполнен статический блок инициализации для инициализации статической переменной staticVar, затем нестатический блок инициализации для и
1176. К каким конструкциям Java применим модификатор static?
Модификатор static в Java можно применять к полям (переменным класса), методам и вложенным классам. Когда static применяется к полю класса, это означает, что это поле общее для всех экземпляров этого класса, и оно существует независимо от конкретного экземпляра. Когда static применяется к методу, это означает, что метод принадлежит классу, а не экземпляру класса, и поэтому вызывается через имя класса, а не через экземпляр класса. При использовании static для вложенного класса он становится static-вложенным классом.
Например:
public class MyClass {
public static int myStaticField;
public int myInstanceField;
public static void myStaticMethod() {
// ...
}
public void myInstanceMethod() {
// ...
}
public static class MyStaticNestedClass {
// ...
}
}
Здесь мы имеем статическое поле myStaticField, статический метод myStaticMethod, нестатическое (экземплярное) поле myInstanceField, нестатический метод myInstanceMethod и статический вложенный класс MyStaticNestedClass.
Модификатор static в Java может быть применен к переменным, методам и блокам кода внутри класса, чтобы указать, что они являются статическими. Статические переменные и методы связаны с классом, а не с экземплярами класса, и могут быть вызваны без создания экземпляра.
Пример использования модификатора static в Java для переменной:
public class MyClass {
static int x = 5;
public static void main(String[] args) {
System.out.println(x); // output: 5
}
}
Пример использования модификатора static в Java для метода:
public class MyClass {
static void myStaticMethod() {
System.out.println("Static methods can be called without creating objects");
}
public static void main(String[] args) {
myStaticMethod(); // Call the static method
}
}
Пример использования модификатора static в Java для блока кода:
public class MyClass {
static {
System.out.println("This is a static block");
}
public static void main(String[] args) {
// The static block is executed when the class is loaded
}
}
1177. Для чего в Java используются статические блоки инициализации?
В Java статические блоки инициализации используются для выполнения каких-либо действий при загрузке класса в память. Эти блоки выполняются только один раз и до вызова любых методов класса или создания экземпляров класса. Таким образом, они могут использоваться для инициализации статических переменных или выполнения сложных вычислений при загрузке класса в память.
Вот пример использования статического блока инициализации в Java:
public class Example {
static int x;
static {
x = 42;
// выполняем другие действия при загрузке класса
}
}
В этом примере статический блок инициализации устанавливает значение переменной x равным 42 при загрузке класса Example в память. Это гарантирует, что переменная x будет инициализирована до использования в каких-либо методах класса Example.
Одним из преимуществ использования статических блоков инициализации является то, что они позволяют создавать классы со сложной логикой инициализации без необходимости создавать отдельный метод и вызывать его при создании экземпляра класса.
1178. Что произойдёт, если в блоке инициализации возникнет исключительная ситуация?
Если в блоке инициализации возникнет исключительная ситуация, то объект не будет создан, и исключение будет выброшено. Блок инициализации выполняется перед конструктором объекта, и если в нем возникнет исключительная ситуация, конструктор не будет вызван, и объект не будет создан.
Например, рассмотрим следующий код:
public class MyClass {
static {
// Блок инициализации, в котором возникает исключение
int a = 1 / 0; // Арифметическая ошибка: деление на ноль
}
public MyClass() {
// Конструктор объекта
}
}
В этом примере при создании объекта класса MyClass первым делом будет выполнен статический блок инициализации. Однако, в этом блоке возникает исключительная ситуация из-за деления на ноль, и конструктор объекта не будет вызван, так как объект не будет создан.
1179. Какое исключение выбрасывается при возникновении ошибки в блоке инициализации класса?
В Java, если происходит ошибка в блоке инициализации класса (static блок), выбрасывается исключение ExceptionInInitializerError. Это исключение генерируется, когда инициализация класса невозможна, потому что произошла необработанная исключительная ситуация во время выполнения блока инициализации. Если в блоке инициализации было брошено исключение, оно будет вложено в этот ExceptionInInitializerError.
1180. Может ли статический метод быть переопределён или перегружен?
Статический метод не может быть переопределен, поскольку переопределение предполагает изменение метода в классе-наследнике. В Java статические методы принадлежат классу, а не объекту, поэтому методы не могут быть переопределены. Однако статический метод может быть перегружен, то есть в классе могут быть определены другие статические методы с тем же именем, но с разными параметрами. Перегрузка методов - это одна из особенностей полиморфизма в Java.
Пример перегрузки статического метода:
public class Example {
public static void print(String str) {
System.out.println(str);
}
public static void print(int num) {
System.out.println(num);
}
}
В этом примере класс Example содержит два статических метода print, один для строковых значений и один для целых чисел. Оба метода имеют одно и то же имя, но разные параметры.
1181. Могут ли нестатические методы перегрузить статические?
Нестатические методы не могут перегрузить статические методы в Java. Это происходит потому, что статические методы принадлежат классу, а не объекту, в то время как нестатические методы принадлежат объекту. В Java перегрузка методов определяется на основе имени метода и списка его параметров. Поскольку статические методы и нестатические методы имеют разные области видимости и не могут быть вызваны с использованием одного и того же синтаксиса, они не могут быть перегружены друг другом.
1182. Можно ли сузить уровень доступа/тип возвращаемого значения при переопределении метода?
Да, в Java при переопределении метода можно сузить доступ. Это означает, что тип возвращаемого значения может быть сужен до типа, производного от типа возвращаемого значения в методе, объявленном в суперклассе.
Например, пусть у нас есть суперкласс A и подкласс B, который наследуется от A. Суперкласс A имеет метод foo(), который возвращает объект типа A. Если в подклассе B переопределить метод foo() и изменить тип возвращаемого значения на B, то это будет допустимо, так как B является производным от типа, который возвращается в суперклассе.
class A {
public A foo() {
return new A();
}
}
class B extends A {
@Override
public B foo() {
return new B();
}
}
Таким образом, в классе B, метод foo() возвращает объект типа B, который является производным от типа, возвращаемого в методе foo() класса A.
Отметим, что при этом уровень доступа не должен быть сужен (к примеру, с public на protected или private).
1183. Возможно ли при переопределении метода изменить: модификатор доступа, возвращаемый тип, тип аргумента или их количество, имена аргументов или их порядок; убирать, добавлять, изменять порядок следования элементов секции throws?
При переопределении метода в Java нельзя уменьшать уровень доступа, этот метод должен быть как минимум такого же уровня, что и в родительском классе. Однако вы можете увеличивать уровень доступа. Вы также можете изменять возвращаемый тип, тип аргумента и количество аргументов, но вы должны сохранить сигнатуру метода, чтобы переопределение работало правильно. Вы не можете изменять имена аргументов или их порядок. Что касается секции throws, то при переопределении вы можете добавлять новые исключения, относящиеся к секции throws, но вы не можете убирать их или изменять порядок.
Вот пример переопределения метода с изменением возвращаемого типа:
class Animal {
public void makeSound() {
System.out.println("The animal makes a sound");
}
}
class Dog extends Animal {
public String makeSound() {
return "Woof";
}
}
public class Main {
public static void main(String[] args) {
Animal myDog = new Dog();
String sound = myDog.makeSound();
System.out.println(sound); // Outputs "Woof"
}
}
В этом примере метод makeSound переопределен в классе Dog, и возвращаемый тип изменен на String. Однако, важно помнить, что вызывая makeSound на объекте Animal, мы все равно получим ожидаемый результат.
1184. Как получить доступ к переопределенным методам родительского класса?
В Java, чтобы получить доступ к переопределенным методам родительского класса из дочернего класса, можно использовать ключевое слово "super". Вы можете использовать синтаксис "super.method()" для вызова переопределенного метода родительского класса.
Например, если у вас есть класс "Родитель" с методом "print()", который затем переопределяется в дочернем классе "Дочерний", то вы можете вызвать родительский метод "print()" из дочернего класса вот так:
class Родитель {
public void print() {
System.out.println("Родительский метод print()");
}
}
class Дочерний extends Родитель {
@Override
public void print() {
super.print(); // вызов родительского метода print()
System.out.println("Дочерний метод print()");
}
}
Дочерний d = new Дочерний();
d.print();
// Output:
// Родительский метод print()
// Дочерний метод print()
В этом примере, когда мы вызываем метод print() у объекта класса Дочерний, переопределенный метод print() класса Дочерний вызывает родительский метод print() с помощью super.print(). Затем делает что-то свое. Как результат, оба метода выводивша строки на экран.
1185. Можно ли объявить метод абстрактным и статическим одновременно?
Нет, в Java нельзя объявить метод как абстрактный и статический одновременно. Модификатор abstract указывает на то, что метод должен быть реализован в подклассах, тогда как static указывает на то, что метод принадлежит классу, а не экземпляру.
Если вы попытаетесь объявить метод абстрактным и статическим, вы получите ошибку компиляции: Illegal combination of modifiers: 'abstract' and 'static'.
Заметьте , что абстрактный метод не может быть привязан к какому-либо экземпляру класса, и поэтому не может быть объявлен статическим.
1186. В чем разница между членом экземпляра класса и статическим членом класса?
Член экземпляра класса и статический член класса - это два разных типа членов класса в Java.
Член экземпляра класса относится к конкретному экземпляру класса. Это означает, что каждый экземпляр класса имеет свой собственный набор членов экземпляра класса. Член экземпляра класса доступен только через экземпляр класса и не может быть использован без него.
Статический член класса, напротив, относится к классу в целом, а не к конкретному экземпляру класса. Это означает, что только одна копия статического члена класса существует независимо от количества созданных экземпляров класса. Статический член класса может быть использован без создания экземпляра класса.
Использование статического члена класса может иногда приводить к проблемам с потокобезопасностью, так как статический член класса доступен для всех экземпляров класса. Однако, если вам нужно, чтобы метод или переменная принадлежали всем экземплярам класса, статические члены класса могут предоставить лучший способ реализации этого функционала.
Таким образом, разница между членом экземпляра класса и статическим членом класса заключается в том, что члены экземпляра ассоциируются с конкретными экземплярами класса и доступны только через ссылки на них, тогда как статические члены ассоциируются с классом в целом и доступны через имя класса.
1187. Где разрешена инициализация статических/нестатических полей?
Инициализацию как статических, так и нестатических полей в Java можно выполнять внутри конструктора, блока инициализации и при объявлении переменной.
Инициализация статических полей также может быть выполнена в блоке статической инициализации класса.
Примеры:
Инициализация нестатического поля в конструкторе:
public class MyClass {
private int myField;
public MyClass(int myField) {
this.myField = myField;
}
}
Инициализация статического поля в блоке статической инициализации класса:
public class MyClass {
private static final String MY_CONSTANT;
static {
MY_CONSTANT = "Hello, world!";
}
}
Инициализация нестатического поля при объявлении переменной:
public class MyClass {
private int myField = 10;
}
Инициализация нестатического поля в блоке инициализации:
public class MyClass {
private int myField;
{
myField = 10;
}
}
Это лишь несколько примеров инициализации полей в Java.
1188.` Какие типы классов бывают в java?
В Java существует несколько типов классов:
Обычные классы (Regular classes)- это классы, которые не имеют никаких особых ключевых слов или модификаторов. Они просто содержат переменные и методы, и могут быть использованы для описания любой сущности в вашей программе.Абстрактные классы (Abstract classes)- это классы, которые имеют ключевое слово abstract в своем определении. Они не могут быть использованы для создания объектов напрямую, но могут содержать абстрактные методы (методы без тела), которые должны быть реализованы в любом классе-наследнике.Интерфейсы (Interfaces)- это классы, которые описывают только подписи методов, но не содержат саму реализацию. Они используются для определения общего контракта между классами и часто используются для создания полиморфных конструкций в программе.Финальные классы (Final classes)- это классы, которые не могут быть наследованы. Они могут использоваться для создания безопасных или неизменяемых классов, которые не могут быть изменены в процессе выполнения программы.Вложенные классы (Nested classes)- это классы, которые определены внутри другого класса. В Java существует четыре типа вложенных классов: статические вложенные классы (Static nested classes), нестатические вложенные классы (Inner classes), локальные классы (Local classes) и анонимные классы (Anonymous classes).Энумерация- специальный тип класса, который используется для представления конечного списка значений.Локальный класс- класс, который объявлен внутри метода или блока кода и имеет доступ к локальным переменным и параметрам внешнего метода или блока.Anonymous inner class (анонимный класс). Объявляется без имени как подкласс другого класса или реализация интерфейса.
1189. Расскажите про вложенные классы. В каких случаях они применяются?
В Java есть 4 типа вложенных классов: статические вложенные классы, нестатические вложенные классы (обычные inner class), анонимные классы и локальные классы.
Статические вложенные классы, или статические вложения, это классы, которые определены внутри другого класса как статические члены. Они могут быть использованы без создания объекта внешнего класса, что позволяет обернуть связанный класс в другой класс для более логического разделения кода.Нестатические вложенные классы, или обычные inner class, это классы, которые определены внутри другого класса без ключевого слова static. Они имеют доступ к полям и методам внешнего класса и могут быть использованы только после создания объекта внешнего класса.Анонимные классысоздаются без определения имени класса и используются только для одного экземпляра. Они могут быть использованы для реализации интерфейсов или абстрактных классов, а также для простой реализации обработчиков событий.Локальные классыопределены внутри блока кода, такого как метод, и могут иметь доступ к локальным переменным этого блока.
Использование вложенных классов обычно осуществляется для логического группирование классов и контроля доступа к полям и методам внешнего класса. Они также могут быть использованы для улучшения чтения/понимания кода, ограничения области видимости и создания анонимных классов, например для реализации обработчиков событий.
1190. Что такое «статический класс»?
Статический класс в Java - это класс, который объявлен с модификатором static. Он может использоваться без создания экземпляра внешнего класса и имеет доступ к статическим полям и методам этого внешнего класса. Также статический класс может быть вложенным в другой класс.
Статические классы обычно используются в тех случаях, когда нужно создать утилиты или вспомогательные классы, которые не связаны напрямую с другими классами в приложении.
Пример объявления статического вложенного класса в Java:
public class MainClass {
// статический вложенный класс
static class StaticNestedClass {
public void printMessage() {
System.out.println("This is a static nested class");
}
}
public static void main(String[] args) {
StaticNestedClass nestedObj = new StaticNestedClass();
nestedObj.printMessage();
}
}
Здесь StaticNestedClass - это статический вложенный класс, который может быть использован без создания экземпляра MainClass. Метод printMessage() в этом классе печатает строку на консоль. В методе main() создается объект StaticNestedClass и вызывается его метод printMessage().
1191. Какие существуют особенности использования вложенных классов: статических и внутренних? В чем заключается разница между ними?
В Java существуют два типа вложенных классов: статические и внутренние.
Статические вложенные классы являются статическими членами внешнего класса и могут быть созданы без создания экземпляра внешнего класса. Они обычно используются для связывания классов, которые связаны, но не зависят от состояния экземпляров внешнего класса. Статические вложенные классы не могут использовать нестатические члены внешнего класса.
Внутренние классы – это нестатические классы, создаваемые внутри другого класса. Они могут использовать любые члены внешнего класса, включая частные, и могут обращаться к ним напрямую. Они могут быть использованы для реализации сложных структур данных или для решения проблем с областью видимости и доступом к данным.
Разница между статическими и внутренними вложенными классами в том, что статические классы не имеют доступа к нестатическим членам внешнего класса, а внутренние классы могут использовать любые члены внешнего класса. Выбор того, какой тип вложенного класса использовать, зависит от того, какой функционал требуется для данного класса.
1192. Что такое «локальный класс»? Каковы его особенности?
"Локальный класс" в Java - это класс, объявленный внутри метода, конструктора или блока. Он доступен только в пределах области видимости, в которой был объявлен. Локальный класс имеет доступ ко всем полям и методам внешнего класса, в том числе к закрытым и защищенным (protected). Кроме того, локальный класс может реализовывать интерфейсы и наследоваться от классов, как и обычные классы.
Особенностью локальных классов является то, что они позволяют создавать классы, специализированные для определенных задач внутри метода. Это может упростить код и улучшить его читаемость. Локальный класс также может использоваться для реализации простых интерфейсов или абстрактных классов на месте.
Вот пример объявления и использования локального класса:
public class Outer {
private int outerField = 100;
public void someMethod() {
int localVariable = 42;
class LocalInner {
public void innerMethod() {
System.out.println("Outer field value: " + outerField);
System.out.println("Local variable value: " + localVariable);
}
}
LocalInner li = new LocalInner();
li.innerMethod();
}
}
В этом примере создается локальный класс LocalInner, который имеет доступ к полю outerField внешнего класса Outer и локальной переменной localVariable в методе someMethod(). Затем создается экземпляр LocalInner и вызывается его метод innerMethod().
Нужно учесть, что локальный класс не должен использовать локальные переменные, если они объявлены без модификатора final.
1193. Что такое «анонимные классы»? Где они применяются?
Иногда, в процессе написания кода, возникает потребность в создании класса, который будет использоваться только в одном месте и не будет иметь имени. Для таких случаев в языке Java есть так называемые анонимные классы.
Анонимный класс представляет собой класс, созданный без указания имени класса. Он объявляется и создается одновременно в месте, где он используется. Внешне анонимный класс выглядит как обычный класс, но без имени.
Анонимные классы обычно используются для создания объектов, которые реализуют какой-то интерфейс или унаследованы от какого-то класса. Они позволяют писать компактный и выразительный код, так как не требуют создания отдельного класса только для одного использования.
Вот пример анонимного класса, который реализует интерфейс Runnable и запускает побочный поток:
new Thread(new Runnable() {
public void run() {
System.out.println("Running in a new thread");
}
}).start();
В этом примере создается анонимный класс, который реализует интерфейс Runnable и переопределяет метод run(). Класс передается в конструктор класса Thread, который запускает побочный поток. Обратите внимание на фигурные скобки вокруг определения класса - они нужны для создания анонимного класса.
Анонимные классы также могут использоваться для создания обработчиков событий в Swing-приложениях, а также в различных фреймворках и библиотеках Java.
1194. Каким образом из вложенного класса получить доступ к полю внешнего класса?
Для доступа к полю внешнего класса из вложенного класса в Java используйте имя внешнего класса, за которым следует ключевое слово this и имя поля. Например, если внешний класс называется OuterClass, и вы хотите получить доступ к полю outerField, то вы можете использовать следующий код во вложенном классе:
class InnerClass {
void someMethod() {
// получаем доступ к outerField из вложенного класса
int fieldValue = OuterClass.this.outerField;
}
}
Здесь мы используем ключевое слово this для получения экземпляра внешнего класса, а затем доступным становится его поле outerField. Обратите внимание, что OuterClass.this - это способ указать на экземпляр внешнего класса, к которому принадлежит вложенный класс.
1195. Для чего используется оператор assert?
Оператор assert в Java используется для проверки инвариантов в коде. Это позволяет убедиться в правильности предположений, которые сделал программист при написании кода, и помогает предотвратить ошибки во время выполнения. Оператор assert будет проверять заданное булевое выражение и, если оно равно false, выбросит исключение AssertionError.
Пример использования оператора assert:
public double calculateAverage(int[] numbers) {
assert numbers.length > 0 : "The provided array must not be empty";
int sum = 0;
for (int number : numbers) {
sum += number;
}
return sum / (double) numbers.length;
}
В этом примере оператор assert проверяет, что длина массива numbers больше нуля, иначе вызывает AssertionError с сообщением "The provided array must not be empty".
Важно отметить, что по умолчанию оператор assert отключен в Java. Чтобы включить его, нужно запустить программу с флагом -ea или -enableassertions.
1196. Что такое Heap и Stack память в Java? Какая разница между ними?
В Java есть два основных типа памяти: stack и heap. Stack используется для хранения локальных переменных и временных параметров, которые создаются при вызове методов, а heap используется для хранения объектов и массивов.
Разница между ними заключается в том, что данные, хранящиеся на stack, удаляются автоматически после окончания работы метода, который их создал, в то время как данные, хранящиеся на heap, сохраняются до тех пор, пока на них есть ссылки. Кроме того, размер стека часто ограничен, в то время как размер heap ограничен только ресурсами, доступными в системе.
Как правило, примитивные типы данных, такие как int или boolean, хранятся на stack, а объекты и массивы хранятся на heap. Однако ссылки на объекты и массивы также могут храниться на stack.
Разница между stack и heap памятью имеет важное значение при проектировании и оптимизации Java-приложений. Важно понимать, как работать с памятью, чтобы избежать утечек памяти и обеспечить эффективную работу приложения.
1197. Верно ли утверждение, что примитивные типы данных всегда хранятся в стеке, а экземпляры ссылочных типов данных в куче?
Да, верно. В Java примитивные типы данных (int, double, boolean и т.д.) всегда хранятся в стеке, а экземпляры объектов - в куче. При объявлении переменной примитивного типа в стеке выделяется место под значение самой переменной, а при создании объекта в куче выделяется место под сам объект и ссылка на него сохраняется в стеке. Другие переменные, которые ссылаются на этот объект, также содержат ссылки на этот же объект в куче.
1198. Каким образом передаются переменные в методы, по значению или по ссылке?
В Java переменные могут передаваться в методы как по значению (pass-by-value), так и по ссылке (pass-by-reference).
При передаче переменных примитивных типов данных (таких как int, double, boolean и т.д.) в методы, они передаются по значению, то есть копия значения переменной (без самой переменной) передается в метод. Изменения значения внутри метода не влияют на значение переменной, переданной при вызове метода.
При передаче объектов в методы, передается ссылка (адрес объекта в памяти), а не сам объект. Следовательно, при изменении объекта внутри метода, изменения будут отражены на самом объекте.
Если нужно передать копию объекта в метод, то следует создать новый объект с такими же полями и передать его в метод.
Например, если у нас есть метод, который изменяет значение поля объекта класса:
public void incrementCounter(Counter c) {
c.setValue(c.getValue() + 1);
}
Чтобы воспользоваться методом, мы можем создать объект Counter и вызвать метод:
Counter myCounter = new Counter();
myCounter.setValue(0);
incrementCounter(myCounter);
System.out.println(myCounter.getValue()); // Выводит 1
Здесь при вызове метода передается ссылка на myCounter, и метод изменяет значение поля в этом объекте, отражая изменения на переменной myCounter в методе, где он был вызван.
Но если переменная является ссылкой на объект, то копия этой ссылки передается в метод, что позволяет изменять состояние объекта, на который ссылается переменная. Но сама ссылка на объект не меняется.
Вот пример передачи аргументов по значению в Java:
public class Example {
public static void main(String[] args) {
int x = 5;
changeValue(x);
System.out.println(x); // Output: 5
}
public static void changeValue(int num) {
num = 10;
}
}
В этом примере переменная x передается методу changeValue по значению. Когда изменяется значение num, это не влияет на значение переменной x.
А вот пример передачи ссылки на объект в Java:
public class Example {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("Hello");
changeValue(sb);
System.out.println(sb.toString()); // Output: "Hello World"
}
public static void changeValue(StringBuilder str) {
str.append(" World");
}
}
В этом примере переменная sb является ссылкой на объект StringBuilder, и эта ссылка передается методу changeValue. Когда вызывается метод append для объекта str, который ссылается на тот же самый объект StringBuilder, на который ссылается sb, это изменяет состояние объекта, и значение, возвращаемое методом toString, становится "Hello World".
1199. Для чего нужен сборщик мусора?
В Java сборщик мусора - это механизм автоматического освобождения памяти от объектов, которые больше не используются программой. Сборщик мусора следит за тем, какие объекты создаются в программе и удаляет те, которые больше не нужны. Это здесь для удобства программиста и чтобы избежать необходимости вручную управлять памятью для каждого объекта.
Большинство современных JVM (в том числе HotSpot JVM, которая входит в состав OpenJDK и является стандартной виртуальной машиной Java) используют сборщики мусора, которые используют алгоритмы, основанные на определенных паттернах использования памяти и не блокирующие выполнение программы для проведения сборки мусора.
Есть несколько различных типов сборщиков мусора в Java, каждый со своими преимуществами и недостатками. Некоторые из наиболее распространенных, доступных в JDK, включают следующие:
- Serial Collector
- Parallel Collector
- Concurrent Mark Sweep (CMS) Collector
- Garbage First (G1) Collector
Каждый тип сборщика мусора работает по-разному и имеет свои собственные параметры настройки, которые могут быть использованы для оптимизации производительности приложения в различных сценариях использования.
1200. Как работает сборщик мусора?
В Java есть сборщик мусора (garbage collector), который автоматически освобождает память, занятую объектами, которые больше не используются вашим приложением. Сборка мусора происходит периодически и зависит от того, сколько памяти используется вашим приложением.
Виртуальная машина Java (JVM) отслеживает все объекты, которые создаются в вашем приложении, и отслеживает, когда они больше не используются. Когда JVM обнаруживает, что объект больше не нужен, он помечает его как "кандидат на удаление". Затем сборщик мусора освобождает память, занятую объектом, когда он больше не нужен вашему приложению.
JVM использует различные алгоритмы сборки мусора, такие как:
Алгоритм Mark-and-Sweep, который проходится по всем объектам в памяти и отмечает те, которые ещё нужны, а затем освобождает память, занятую неотмеченными объектами.Алгоритм Copying, который разделяет всю память на две равные части и перемещает все живые объекты из одной части памяти в другую, оставляя за собой только живые объекты в одной части памяти.Алгоритм Generational, который разделяет память на несколько поколений и делает предположение, что большая часть объектов удаляется сразу после создания, что позволяет сократить количество объектов, которые нужно проходить при каждой сборке мусора.
Каждый алгоритм имеет свои преимущества и недостатки, и используется в зависимости от конкретных условий.
1201. Какие разновидности сборщиков мусора реализованы в виртуальной машине HotSpot?
Виртуальная машина HotSpot реализует несколько разновидностей сборщиков мусора, включая:
Сборщик мусора CMS (Concurrent Mark Sweep)- это сборщик, который выполняет сборку мусора параллельно с приложением и имеет целью максимально сократить паузы приложения, вызванные сборкой мусора.Сборщик мусора G1 (Garbage First)- это сборщик мусора нового поколения, который предназначен для приложений с большим объемом памяти и высокой степенью параллельности. Он пытается уменьшить паузы приложения, вызванные сборкой мусора.Сборщик мусора Serial- это сборщик мусора, который выполняет сборку мусора последовательно, поэтому он не подходит для больших приложений с высокой степенью параллельности.Сборщик мусора Parallel- это сборщик мусора, который выполняет сборку мусора параллельно на нескольких ядрах процессора, что может увеличить производительность в определенных случаях.Z Garbage Collector- это сборщик мусора, который поставляется с JDK 11 и предназначен для работоспособности с большим объемом памяти. Он также использует алгоритмы, которые позволяют ему уменьшить длительность пауз приложения, вызванных сборкой мусора.
1202. Опишите алгоритм работы какого-нибудь сборщика мусора, реализованного в виртуальной машине HotSpot.
Сборщик мусора в виртуальной машине HotSpot реализован с использованием алгоритма под названием "Garbage-First" (G1). Этот алгоритм является современным и эффективным методом сборки мусора, который был введен в Java SE 6.
Алгоритм работы сборщика мусора G1 включает следующие шаги:
Инициализация: В начале работы сборщика мусора G1, ему выделяется определенное количество памяти для хранения объектов и метаданных.
Фаза маркировки: В этой фазе сборщик мусора G1 определяет, какие объекты в памяти являются доступными и какие можно удалить. Для этого он выполняет обход всех корневых объектов и маркирует их как доступные. Затем он рекурсивно маркирует все объекты, которые достижимы из корневых объектов.
Фаза эвакуации: В этой фазе сборщик мусора G1 перемещает доступные объекты в другие регионы памяти, освобождая тем самым регионы, которые содержат неиспользуемые объекты. Это позволяет эффективно использовать память и избежать фрагментации.
Фаза очистки: В этой фазе сборщик мусора G1 освобождает память, занимаемую неиспользуемыми объектами. Он сканирует регионы памяти и освобождает те, которые не содержат доступных объектов.
Фаза завершения: После выполнения всех предыдущих шагов, сборщик мусора G1 завершает свою работу и готов к следующему циклу сборки мусора.
Алгоритм G1 обладает рядом преимуществ, таких как:
Инкрементальная обработка: G1 выполняет сборку мусора поэтапно, что позволяет избежать длительных пауз в работе приложения.
Адаптивная работа: G1 адаптируется к изменяющимся условиям работы приложения и может динамически регулировать свои параметры для достижения оптимальной производительности.
Предсказуемая производительность: G1 стремится к предсказуемой производительности, контролируя длительность пауз сборки мусора и удерживая их на низком уровне.
Это лишь краткое описание алгоритма работы сборщика мусора G1 в виртуальной машине HotSpot. Более подробную информацию можно найти в официальной документации Java или на сайте Oracle.
1203. Что такое «пул строк»?
"Пул строк" (String Pool) в Java - это механизм оптимизации памяти, где строки, созданные в коде, хранятся в специальном "пуле" строк в памяти, чтобы можно было повторно использовать одну и ту же строку в разных частях программы, вместо создания новой каждый раз.
Когда мы создаем строку в Java через литерал (например, "hello"), JVM ищет эту строку в "пуле строк". Если строка уже находится в "пуле", JVM возвращает ссылку на существующую строку, если нет, то создает новую строку и помещает ее в "пул".
Использование "пула строк" позволяет избежать создания множества ненужных копий строк, что может привести к неэффективному использованию памяти. Однако, создание большого количества строк с помощью литералов может также привести к переполнению "пула строк" и утечкам памяти. Чтобы избежать этого, можно использовать конструкторы строк или метод intern(), чтобы явно поместить строки в "пул".
1204. Что такое finalize()? Зачем он нужен?
В Java finalize() - это метод, который вызывается при удалении объекта из памяти. Он может быть переопределен в классе, чтобы выполнить некоторые операции по очистке памяти или освобождению ресурсов, например, закрытие открытого файла или соединения с базой данных.
Метод finalize() вызывается автоматически сборщиком мусора (Garbage Collector), который удаляет объекты, которые больше не используются в программе. Однако, не рекомендуется полагаться на finalize() для освобождения ресурсов, так как время вызова может быть неопределенным и не гарантированно.
Вместо этого лучше использовать конструкцию try-finally или блок try-with-resources для явного освобождения ресурсов после использования.
Важно помнить, что метод finalize() может быть вызван только один раз для каждого объекта, поэтому любые дополнительные операции, которые он выполняет, должны быть корректно реализованы и не должны вызывать ошибки или исключения.
Начиная с JDK 9, этот метод помечен как устаревший и может быть удален в будущем.
Пример переопределения метода finalize() в классе:
class MyClass {
// ...
@Override
protected void finalize() throws Throwable {
try {
// освобождение ресурсов, например, закрытие файла или соединения с базой данных
} finally {
super.finalize();
}
}
}
1205. Что произойдет со сборщиком мусора, если выполнение метода finalize() требует ощутимо много времени, или в процессе выполнения будет выброшено исключение?
Когда объект в Java становится недостижимым и подлежит сборке мусора, сборщик мусора вызывает метод finalize() у этого объекта перед его фактическим удалением из памяти. Метод finalize() предоставляет возможность объекту выполнить некоторые завершающие действия перед удалением.
Если выполнение метода finalize() занимает ощутимо много времени или выбрасывает исключение, это может привести к задержкам в работе сборщика мусора и, в конечном итоге, к проблемам с памятью. Если время выполнения finalize() слишком долгое, сборщик мусора может не успеть освободить память вовремя, что может привести к исчерпанию ресурсов памяти и снижению производительности приложения.
Кроме того, если метод finalize() выбрасывает исключение, это исключение будет игнорироваться сборщиком мусора. Это означает, что исключение не будет передано обработчику и не будет влиять на выполнение программы. Однако, если метод finalize() выбрасывает исключение, оно может быть зарегистрировано и использовано для отладки или логирования.
В целом, рекомендуется быть осторожным при использовании метода finalize(), так как его выполнение может оказывать негативное влияние на производительность и стабильность приложения. Вместо этого, рекомендуется использовать другие механизмы, такие как блоки try-finally или использование интерфейса AutoCloseable, для выполнения завершающих действий перед удалением объекта.
1206. Чем отличаются final, finally и finalize()?
Kлючевое слово final используется для объявления переменной, которая не может быть изменена, класса, который не может быть наследован, или метода, который не может быть переопределен.
Ключевое слово finally используется в блоке обработки исключений и позволяет выполнить код после блока try/catch, независимо от того, было ли исключение выброшено или нет.
Метод finalize() является методом, который вызывается сборщиком мусора при удалении объекта. Он позволяет определенным объектам освободить системные ресурсы или выполнить другие действия перед удалением.
Таким образом, ключевое слово final ограничивает изменяемость переменных, классов и методов, finally используется в блоке обработки исключений для выполнения кода после блока try/catch, а finalize() используется в методе объекта для выполнения определенных действий перед удалением объекта.
1207. Расскажите про приведение типов. Что такое понижение и повышение типа?
В Java приведение типов (type casting) означает преобразование значения переменной из одного типа в другой тип. Оно может быть понижающим и повышающим.
Понижающее приведение (narrowing conversion) используется, когда переменной присваивается значение, которое не может поместиться в текущий тип переменной. Например, при присваивании числа с плавающей точкой типа double целочисленной переменной типа int, происходит отбрасывание дробной части числа. Понижающее приведение может привести к потере точности или внесению ошибок в значения переменных.
Пример понижающего приведения:
double d = 3.14159;
int i = (int) d; // i будет равно 3
Повышающее приведение (widening conversion) используется, когда переменной присваивается значение меньшего типа, чем ее текущий тип. Например, при присваивании целочисленного значения переменной типа с плавающей точкой, вещественная переменная будет автоматически продлена до типа double. Повышающее приведение не приводит к потере точности или ошибкам в значениях переменных.
Пример повышающего приведения:
int i = 42;
double d = i; // d будет равно 42.0
1208. Когда в приложении может быть выброшено исключение ClassCastException
ClassCastException - это исключение, которое может быть выброшено в Java, когда происходит попытка привести объект к типу, который он фактически не является. Это означает, что во время выполнения кода произошла ошибка приведения типов.
Когда в приложении может быть выброшено исключение ClassCastException? Исключение ClassCastException может быть выброшено в следующих случаях:
При попытке привести объект к типу, который он не является. Например, если у вас есть объект типа A, и вы пытаетесь привести его к типу B, но объект на самом деле не является экземпляром класса B, то будет выброшено исключение ClassCastException.
A objA = new A();
B objB = (B) objA; // ClassCastException будет выброшено здесь
При использовании обобщенных типов и неправильном приведении типов. Например, если у вас есть обобщенный класс MyClass, и вы пытаетесь привести его к типу MyClass, но фактический тип T не является String, то будет выброшено исключение ClassCastException.
MyClass<Integer> obj = new MyClass<>();
MyClass<String> strObj = (MyClass<String>) obj; // ClassCastException будет выброшено здесь
При использовании массивов и неправильном приведении типов. Например, если у вас есть массив объектов типа A[], и вы пытаетесь привести его к массиву объектов типа B[], но фактические объекты в массиве не являются экземплярами класса B, то будет выброшено исключение ClassCastException.
A[] arrayA = new A[5];
B[] arrayB = (B[]) arrayA; // ClassCastException будет выброшено здесь
Важно отметить, что ClassCastException является unchecked exception (непроверяемым исключением), поэтому его не обязательно объявлять в сигнатуре метода или обрабатывать с помощью блока try-catch. Однако, если вы ожидаете возникновение исключения ClassCastException, то рекомендуется обрабатывать его, чтобы предотвратить непредсказуемое поведение вашего приложения.
1209. Что такое литералы?
Литералы в Java - это способ записи значений констант в исходном коде программы. Литералы могут быть использованы для представления чисел, строк, символов, логических значений и т.д.
Например, следующие строки являются примерами литералов в Java:
int number = 42; // литерал целочисленного типа
double value = 3.14; // литерал числа с плавающей точкой
String message = "Hello, world!"; // литерал строки
char ch = 'a'; // литерал символа
boolean flag = true; // литерал логического значения
Кроме того, в Java существуют специальные символы для представления особых значений, например, null для обозначения отсутствующего значения и '\n' для обозначения символа перевода строки.
1210. Что такое autoboxing («автоупаковка») в Java и каковы правила упаковки примитивных типов в классы-обертки?
Autoboxing («автоупаковка») в Java - это процесс автоматического преобразования примитивных типов данных в соответствующие классы-обертки, и наоборот, в процессе компиляции или выполнения программы.
В Java примитивные типы данных, такие как int, char, float и другие, не являются объектами, и поэтому не могут использовать методы и свойства объектов. Однако в некоторых случаях требуется использовать объекты, например, когда нужно сохранить значение примитивного типа в коллекцию или передать его в метод, который принимает только объекты.
В этом случае Java автоматически преобразует значение примитивного типа в соответствующий объект класса-обертки. Например, следующий код демонстрирует автоупаковку для типа int:
Integer i = 42; // автоупаковка
int j = i; // автораспаковка
В первой строке переменной i автоматически присваивается объект Integer, созданный из значения 42. А во второй строке переменной j автоматически присваивается значение типа int, полученное из объекта Integer.
При этом автоупаковка и автораспаковка могут происходить как при компиляции, так и при выполнении программы, что может привести к некоторым неожиданным результатам и производительностным проблемам. Поэтому в некоторых случаях рекомендуется явно выполнять упаковку и распаковку значений, используя классы-обертки и методы преобразования типов, такие как Integer.valueOf() и Integer.parseInt().
1211. Какие есть особенности класса String?
Класс String - это класс в Java, который представляет последовательность символов. Он имеет несколько особенностей:
String - это неизменяемый класс. Это означает, что после создания объекта String, его значение не может быть изменено. Если вы, например, хотите изменить строку, необходимо создать новый объект String.
Метод String intern() используется для возвращения канонического представления для строк. При вызове метода intern() для строки он всегда возвращает ссылку на строку в пуле строк. Это может быть полезно, если вам нужно сравнить две строки на равенство.
Объект String может быть создан несколькими способами, например, можно создать объект String из массива символов или из массива байтов, используя заданную кодировку.
String - это класс, который наследуется от класса Object. Он имеет множество методов, таких как length(), substring(), indexOf(), которые позволяют работать со строками.
Класс String в Java имеет несколько способов сравнения строк, включая equals(), equalsIgnoreCase(), compareTo() и compareToIgnoreCase(). Эти методы могут использоваться для сравнения строк и проверки на равенство.
Класс String в Java также предоставляет множество методов для манипулирования строками, включая методы split(), replace(), substring(), toLowerCase() и toUpperCase(). Эти методы могут использоваться для менее простых преобразований и манипуляций со строками.
Некоторые из особенностей класса String в Java включают:
- Неизменяемость: объекты класса String не могут быть изменены после создания. Когда создается новая строка, она занимает новое место в памяти, а не изменяет существующую строку.
- Возможность создания строк из массивов символов: Вы можете создавать строки в Java из массивов символов с помощью конструктора класса String.
- Конкатенация строк: Вы можете объединять строки в Java с помощью оператора "+" или метода concat ().
- Проверка на пустую строку: Вы можете проверить, содержит ли строка какой-либо текст, с помощью метода isEmpty ().
- Поиск в строке: Вы можете искать подстроки в строке с помощью метода indexOf ().
- Разделение строки на подстроки: Вы можете разбить строку на подстроки с помощью метода split ().
- Форматирование строк: Вы можете форматировать строки в Java с помощью метода format ().
- Сравнение строк: Вы можете сравнивать строки в Java с помощью операторов "==" или "equals ()".
1212. Почему String неизменяемый и финализированный класс?
Строки в Java являются неизменяемыми и финализированными классами. Это означает, что после создания экземпляр строки не может быть изменен. Когда вы изменяете строку, Java создает новый экземпляр строки, вместо того, чтобы менять текущий экземпляр строки. Эта особенность обеспечивает безопасность и предотвращает необходимость создания дополнительных копий объектов строки. Также, поскольку строки финализированы, то они не могут быть расширены или подвергнуты наследованию. Эта особенность строк в Java обеспечивает безопасность, поскольку не позволяет изменять данные, когда они однажды созданы, что может привести к ошибкам и неожиданному поведению программы. Также это позволяет сократить количество неиспользуемых объектов в памяти и способствует повышению производительности при работе с большим количеством строк.
1213. Почему char[] предпочтительнее String для хранения пароля?
Хранение пароля в виде массива символов (char[]) предпочтительнее, чем в виде строки (String), поскольку массив символов является изменяемым и может быть очищен после использования. Вот несколько причин, почему char[] предпочтительнее String для хранения пароля:
Немутабельность String: В Java объекты класса String являются неизменяемыми, что означает, что после создания строки ее значение не может быть изменено. Это может привести к уязвимостям безопасности, поскольку пароль, хранящийся в виде строки, может быть доступен в памяти в течение длительного времени, даже после того, как он был использован. Это может быть опасно, если злоумышленник получит доступ к памяти и сможет прочитать пароль.
Изменяемость char[]: В отличие от строк, массивы символов (char[]) являются изменяемыми. Это означает, что после использования пароля его можно очистить, перезаписав его значения случайными символами или нулями. Это помогает предотвратить возможность чтения пароля из памяти.
Управление памятью: При использовании массива символов для хранения пароля вы имеете больший контроль над управлением памятью. Вы можете явно очистить массив символов после использования, чтобы убедиться, что пароль не остается в памяти.
Безопасность: Хранение пароля в виде массива символов может помочь предотвратить утечку пароля в случае, если память, содержащая пароль, будет скомпрометирована. Поскольку массив символов является изменяемым, его значения могут быть перезаписаны или очищены после использования, что делает пароль менее доступным для злоумышленников.
В целом, использование массива символов (char[]) для хранения пароля предпочтительнее, чем использование строки (String), поскольку это обеспечивает большую безопасность и контроль над паролем.
1214. Почему строка является популярным ключом в HashMap в Java?
-
Уникальность и неизменяемость: Строки в Java являются неизменяемыми объектами, что означает, что их значение не может быть изменено после создания. Это делает строки идеальным выбором для использования в качестве ключей в HashMap, так как они гарантированно уникальны и не могут быть изменены после добавления в карту. -
Хэширование и быстрый доступ: HashMap в Java использует хэш-функции для определения индекса, по которому будет храниться значение. Строки в Java имеют свою собственную реализацию метода hashCode(), который генерирует уникальный хэш-код для каждой строки. Это позволяет HashMap быстро находить и получать значения по ключу, используя хэш-код строки. -
Эффективное сравнение: При поиске значения в HashMap по ключу, происходит сравнение хэш-кодов ключей. Если хэш-коды совпадают, то происходит сравнение самих ключей с помощью метода equals(). Строки в Java имеют эффективную реализацию метода equals(), что делает сравнение строк быстрым и эффективным. -
Гибкость и удобство использования:Строки в Java имеют множество методов и операций, которые делают их удобными для работы с текстовыми данными. В качестве ключей в HashMap, строки могут быть использованы для ассоциации с определенными значениями и обеспечения быстрого доступа к этим значениям.
В целом, использование строк в качестве ключей в HashMap в Java является популярным выбором благодаря их уникальности, неизменяемости, эффективности хэширования и сравнения, а также гибкости и удобству использования.
1215. Что делает метод intern() в классе String?.
Метод intern() в классе String позволяет добавить строку в пул строк и вернуть ссылку на эквивалентную строку из пула. Если в пуле уже содержится строка эквивалентная текущей, то метод intern() возвращает ссылку на эту строку из пула вместо создания новой строки. Это позволяет эффективно использовать память и сравнивать строки с помощью оператора ==, потому что для эквивалентных строк == возвращает true. Вот простой пример использования метода intern():
String s1 = "hello";
String s2 = new String("hello");
if (s1 == s2) {
// Этот блок кода не будет выполнен, потому что s1 и s2 имеют разные ссылки
}
String s3 = s2.intern();
if (s1 == s3) {
// Этот блок кода будет выполнен, потому что s3 содержит ссылку на строку "hello" из пула строк
}
В этом примере s1 и s2 содержат эквивалентные строки, но имеют разные ссылки, поэтому оператор == не сработает для сравнения этих строк. Однако, после вызова intern() для s2, s3 содержит ссылку на ту же самую строку "hello" из пула строк, что и s1, поэтому оператор == будет возвращать true для этих переменных.
1216. Можно ли использовать строки в конструкции switch?
Да, в Java можно использовать строки в конструкции switch. Вот пример кода:
String color = "green";
switch(color) {
case "red":
System.out.println("Color is red");
break;
case "green":
System.out.println("Color is green");
break;
case "blue":
System.out.println("Color is blue");
break;
default:
System.out.println("Color is not red, green or blue");
break;
}
Этот код будет выводить "Color is green", так как значение переменной color равно "green". Важно помнить, что при сравнении строк в конструкции switch используется метод equals(), а не оператор ==. Это связано с тем, что строки в Java - это объекты, а не примитивные типы данных.
1217. Какая основная разница между String, StringBuffer, StringBuilder?
Основная разница между String, StringBuffer и StringBuilder заключается в их поведении и использовании в Java.
String - это неизменяемый класс, что означает, что после создания экземпляра строки его значение не может быть изменено. Когда вы выполняете операции над строками, такие как конкатенация или замена символов, создается новый объект строки. Это может привести к неэффективному использованию памяти, особенно при выполнении множественных операций над строками в цикле.
StringBuffer и StringBuilder - это изменяемые классы, которые предоставляют более эффективные способы работы с изменяемыми строками. Они позволяют изменять содержимое строки без создания новых объектов. Основное отличие между StringBuffer и StringBuilder заключается в их потокобезопасности: StringBuffer является потокобезопасным, что означает, что его методы синхронизированы и могут быть использованы в многопоточной среде безопасно, в то время как StringBuilder не является потокобезопасным.
StringBuffer обычно используется в многопоточных приложениях или в случаях, когда требуется безопасность потоков. Он имеет некоторые дополнительные методы, такие как insert(), delete() и reverse(), которые позволяют более гибко изменять содержимое строки.
StringBuilder обычно используется в однопоточных приложениях, где требуется более высокая производительность. Он не обеспечивает потокобезопасность, но в то же время работает быстрее, чем StringBuffer.
В общем, если вам нужна изменяемая строка в многопоточной среде, используйте StringBuffer. Если вам нужна изменяемая строка в однопоточной среде, используйте StringBuilder. Если вам не требуется изменять строку, используйте String для обеспечения безопасности и неизменности.
Пример использования StringBuilder:
StringBuilder sb = new StringBuilder();
sb.append("Hello");
sb.append(" World");
String result = sb.toString(); // "Hello World"
Пример использования StringBuffer:
StringBuffer sb = new StringBuffer();
sb.append("Hello");
sb.append(" World");
String result = sb.toString(); // "Hello World"
Пример использования String:
String str = "Hello World";
1218. Что такое класс Object? Какие в нем есть методы?
Класс Object является корневым классом в иерархии классов Java. Все классы в языке Java наследуются от него напрямую или косвенно. В классе Object определены следующие методы:
equals(Object obj) – позволяет сравнивать текущий объект с другим объектом на равенство;
toString()– возвращает строковое представление объекта;hashCode()– возвращает хеш-код объекта;getClass()– возвращает объект класса, к которому принадлежит текущий объект;finalize()– вызывается перед тем, как сборщик мусора уничтожит объект;clone()– создает копию объекта;wait()– заставляет текущий поток ожидать до тех пор, пока другой поток не уведомит его о том, что произошло определенное событие;notify()– разблокирует один из потоков, ожидающих на текущем объекте;notifyAll()– разблокирует все потоки, ожидающие на текущем объекте.
Эти методы могут быть переопределены в классах-наследниках для более конкретного их поведения в соответствии с нуждами программы.
1219. Дайте определение понятию «конструктор».
Конструктор - это метод класса в Java, который вызывается при создании нового объекта этого класса. Он используется для инициализации полей объекта и может принимать параметры. Конструктор имеет тот же имя, что и класс, и не имеет возвращаемого значения. Например, вот пример класса Person с конструктором:
public class Person {
private String name;
private int age;
// Конструктор класса Person
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// Геттеры и сеттеры для полей name и age
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Конструктор Person принимает два параметра - name и age, и устанавливает их значения для нового объекта Person. Можно создать новый объект Person следующим образом:
Person person = new Person("Alice", 25);
В этом примере вызывается конструктор Person с параметрами "Alice" и 25, и создается новый объект типа Person с именем Alice и возрастом 25 лет.
1220. Что такое «конструктор по умолчанию»?
"Конструктор по умолчанию" (default constructor) - это конструктор, который имеет набор параметров по умолчанию. В Java, если вы не определяете никаких конструкторов, компилятор автоматически создаст такой конструктор без параметров. Этот конструктор пустой и не выполняет никаких действий при создании нового объекта. Например, следующий код создает экземпляр класса "Person" с использованием конструктора по умолчанию:
public class Person {
private String name;
private int age;
// Конструктор по умолчанию
public Person() {
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
Person person = new Person();
В данном случае, конструктор по умолчанию создается автоматически, и никаких дополнительных параметров не требуется.
1220. Чем отличаются конструктор по-умолчанию, конструктор копирования и конструктор с параметрами?
В Java конструктор по умолчанию создается автоматически, если не определять явно конструктор класса. Он используется для создания объекта класса со значениями по умолчанию или без параметров.
Конструктор копирования создает новый объект, который является точной копией существующего объекта. Он используется для создания нового объекта, который имеет те же значения полей, что и старый объект.
Конструктор с параметрами предназначен для инициализации полей объекта при его создании. Он определяется пользователем и принимает параметры, значения которых используются для инициализации соответствующих полей объекта.
Важно отметить, что если в классе определен конструктор, то конструктор по умолчанию автоматически не создается. Конструктор по умолчанию не передает никаких параметров и может не выполнять никаких действий. Если класс определяет только конструкторы с параметрами, то в этом классе создание объекта без передачи параметров будет вызывать ошибку компиляции.
Пример создания конструкторов:
public class MyClass {
private int num;
private String str;
// конструктор по умолчанию
public MyClass() {
num = 0;
str = "";
}
// конструктор с параметрами
public MyClass(int num, String str) {
this.num = num;
this.str = str;
}
// конструктор копирования
public MyClass(MyClass obj) {
num = obj.num;
str = obj.str;
}
}
В примере выше класс MyClass определяет три конструктора: конструктор по умолчанию, конструктор с параметрами и конструктор копирования. Конструктор с параметрами инициализирует поля объекта переданными параметрами при создании объекта, а конструктор копирования создает новый объект, который является точ ной копией существующего объекта.
1221. Где и как вы можете использовать приватный конструктор?
В Java приватный конструктор может быть использован для различных целей, например:
- Создание утилитного класса, который не предполагает создание экземпляров объектов, а содержит только статические методы. Приватный конструктор делает невозможным создание новых экземпляров класса снаружи.
- Работа с шаблонами проектирования, такими как синглтон, фабрика и т. д. В таких случаях приватный конструктор используется для того, чтобы предотвратить создание экземпляров класса снаружи, а создание объектов происходит только внутри класса.
- Работа с классом, который не должен иметь наследников. Приватный конструкторделает наследование невозможным, так как производный класс не сможет вызвать конструктор родительского класса.
- Работа с классом, который должен быть доступен только внутри своего пакета. Приватный конструктор делает невозможным создание экземпляров класса в других пакетах.
В Java вы можете использовать приватный конструктор для создания синглтона (singleton) или для создания утилитарного класса (utility class), который не должен иметь экземпляров, но может содержать только статические методы. Утилитарные классы часто используются для группировки связанных методов в одном месте без необходимости создания экземпляров. Синглтоны, с другой стороны, ограничивают количество экземпляров класса до одного и обеспечивают глобальный доступ к экземпляру. В обоих случаях приватный конструктор предотвращает создание экземпляров класса извне.
Пример утилитарного класса с приватным конструктором:
public final class StringUtils {
private StringUtils() { // приватный конструктор
throw new AssertionError(); // предотвращает создание экземпляров класса извне
}
public static boolean isNullOrEmpty(String str) {
return str == null || str.isEmpty();
}
// другие статические методы
}
Использование этого класса:
if (StringUtils.isNullOrEmpty(myString)) {
// делайте что-то, если myString пустая или равна null
}
Пример синглтона с приватным конструктором:
public class Singleton {
private static final Singleton INSTANCE = new Singleton(); // создание единственного экземпляра
private Singleton() { // приватный конструктор
}
public static Singleton getInstance() { // метод, для получения единственного экземпляра
return INSTANCE;
}
// другие методы и переменные экземпляра
}
Использование синглтона:
Singleton singleton = Singleton.getInstance(); // получение экземпляра
1222. Расскажите про классы-загрузчики и про динамическую загрузку классов.
В Java классы-загрузчики используются для загрузки классов в память JVM (Java Virtual Machine) при выполнении программы. Классы-загрузчики взаимодействуют с классами JVM и загружают только те классы, которые нужны в текущий момент. Это позволяет программам экономить на использовании памяти и ускорять загрузку программы.
Существует три типа классов-загрузчиков:
Bootstrap ClassLoader: загружает системные классы JDK, такие как java.lang.Object и java.util.ArrayList.Extension ClassLoader: загружает расширения Java, находящиеся в $JAVA_HOME/lib/ext.System ClassLoader: загружает классы пользователя, указанные в переменной CLASSPATH.
Динамическая загрузка классов позволяет программисту загружать новые классы в программу во время выполнения. Это может быть полезно в тех случаях, когда часть программы должна быть загружена только по мере необходимости, или когда пользователь может выбрать, какую часть программы загрузить.
В Java динамическую загрузку классов можно осуществить с помощью Class.forName() или ClassLoader.loadClass(). Пример:
ClassLoader classLoader = MyClassLoader.getInstance();
Class myClass = classLoader.loadClass("com.example.MyClass");
Здесь MyClassLoader - это пользовательский класс-загрузчик, который загружает класс MyClass. Это может быть полезно, если вы хотите загрузить классы из файла или другого источника, который не поддерживается стандартными методами Java загрузки классов.
1223. Что такое Reflection?
Reflection это возможность в языке Java, которая позволяет программе получать информацию о себе во время выполнения. Она дает возможность изучать классы, интерфейсы, объекты и их параметры во время выполнения программы.
Reflection API позволяет создавать классы, объекты, вызывать методы и получать информацию о классах и их свойствах, даже если это скрытая информация. Reflection API предоставляет некоторые классы, такие как Class, Method, Constructor и Field, которые можно использовать для получения информации о классе и его свойствах.
Reflection может использоваться в различных ситуациях, например, в библиотеках, которые должны быть написаны для работы с любыми классами, в инструментах для отладки, где можно исследовать состояние приложения во время выполнения, и во многих других задачах.
Пример использования Reflection API:
import java.lang.reflect.*;
public class MyClass {
private String name;
public MyClass(String name) {
this.name = name;
}
public void printName() {
System.out.println("Name: " + name);
}
public static void main(String[] args) throws Exception {
Class<MyClass> clazz = MyClass.class;
Constructor<MyClass> constructor = clazz.getConstructor(String.class);
MyClass obj = constructor.newInstance("John Doe");
Method method = clazz.getMethod("printName");
method.invoke(obj);
}
}
В этом примере мы используем Reflection API, чтобы получить класс MyClass, создать объект этого класса, вызвать его метод и вывести его имя на консоль.
1224. Зачем нужен equals(). Чем он отличается от операции ==?
В Java операция == используется для сравнения примитивных типов данных (int, float, boolean и т. д.) и для сравнения ссылок на объекты. Операция equals() же используется для сравнения содержимого (значений) объектов.
По умолчанию метод equals() в Java также выполняет сравнение ссылок на объекты, но этот метод можно переопределить в своем собственном классе, чтобы определить, каким образом должно производиться сравнение двух экземпляров этого класса (например, по полям класса).
Важно знать, что если вы переопределили метод equals(), то также рекомендуется переопределить метод hashCode(), чтобы обеспечить корректное поведение объектов в хеш-таблицах.
Вот пример того, как мог бы выглядеть переопределенный метод equals() и hashCode() в классе Person:
public class Person {
private String name;
private int age;
// constructors, getters, setters, etc.
@Override
public boolean equals(Object obj) {
if (obj == null || getClass() != obj.getClass()) {
return false;
}
Person person = (Person) obj;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
В этом примере метод equals() сравнивает объекты Person по полям name и age. Метод hashCode() использует метод Objects.hash(), чтобы вычислить хеш-код на основе тех же полей. Переопределение hashCode() гарантирует, что два экземпляра класса, которые равны с помощью equals(), также будут иметь одинаковые хеш-коды.
1225. Если вы хотите переопределить equals(), какие условия должны выполняться?
Если вы хотите переопределить метод equals() в Java, то должны выполняться следующие условия:
Рефлексивность: a.equals(a) всегда должно возвращать true, где a - это объект любого класса.Симметричность: Если a.equals(b) возвращает true, то b.equals(a) также должно возвращать true.Транзитивность: Если a.equals(b) и b.equals(c) возвращают true, то a.equals(c) также должно возвращать true.Консистентность: Повторный вызов a.equals(b) должен возвращать один и тот же результат, при условии, что ни a ни b не изменяются.Неудовлетворение null: a.equals(null) должен всегда возвращать false, где a - это объект любого класса.
Пример переопределения метода equals() для класса Person:
public class Person {
private String name;
private int age;
// Constructors, getters, setters
@Override
public boolean equals(Object obj) {
if (obj == this) return true;
if (!(obj instanceof Person)) return false;
Person other = (Person) obj;
return this.name.equals(other.getName()) && this.age == other.getAge();
}
}
Этот метод проверяет, являются ли два объекта Person равными, сравнивая их имя и возраст.
1226. Какими свойствами обладает порождаемое equals() отношение эквивалентности?
В Java метод equals() является отношением эквивалентности и обладает следующими свойствами:
Рефлексивность: объект должен быть равен самому себе. То есть a.equals(a) должно вернуть true.Симметричность: если объект a равен объекту b, то объект b должен быть равен объекту a. То есть если a.equals(b) возвращает true, то и b.equals(a) должен вернуть true.Транзитивность: если объект a равен объекту b, и объект b равен объекту c, то объект a должен быть равен объекту c. То есть если a.equals(b) и b.equals(c) возвращают true, то и a.equals(c) должно вернуть true.Согласованность: если объект a не изменился, то вызов a.equals(b) должен всегда возвращать одинаковый результат, пока объект b не изменился.Не равенство с null: метод equals() должен возвращать false, если объект b равен null.
Кроме того, для правильной реализации метода equals() требуется переопределить метод hashCode(). Метод hashCode() возвращает целочисленное значение, которое является "хэш-кодом" объекта и используется внутри HashMap и HashSet для оптимизации поиска и обеспечения уникальности элементов.
1227. Правила переопределения метода Object.equals().
Правила переопределения метода equals() из класса Object в Java:
- Метод должен принимать на вход объект типа Object.
- Метод должен проверить, является ли переданный объект ссылкой на тот же объект, что и текущий объект, и если да, вернуть true.
- Метод должен проверить, является ли переданный объект экземпляром того же класса, что и текущий объект.
- Метод должен проверить, что все поля текущего объекта и переданного объекта совпадают.
- Если все условия проверки выполнились успешно, метод должен вернуть true, иначе - false.
Пример переопределения метода equals() в классе User:
public class User {
private String name;
private int age;
//конструктор класса
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof User)) return false;
User user = (User) o;
if (age != user.age) return false;
return name.equals(user.name);
}
//геттеры и сеттеры
}
В этом примере мы проверяем , что переданный объект является экземпляром класса User, и сравниваем все поля класса в соответствии с логикой нашей программы. Если поля совпадают, метод возвращает true, иначе - false.
Не забывайте, что если переопределение метода equals() требуется в вашем классе, то, вероятно, вам также нужно переопределить метод hashCode(). Это связано с тем, что при использовании объектов в качестве ключей для хеш-таблиц необходимо, чтобы у двух объектов, которые были бы равными по equals(), был одинаковый hashCode().
1228. Какая связь между hashCode() и equals()?
В Java hashCode() и equals() — это два метода, которые связаны со сравнением объектов и часто используются вместе. Метод equals() используется для проверки того, логически ли два объекта равны друг другу, а метод hashCode() используется для получения уникального целочисленного значения для объекта, которое можно использовать для идентификации объекта в HashMap или другом коллекции. В общем, при реализации метода equals() рекомендуется также реализовать метод hashCode(), чтобы два логически равных объекта имели одинаковый хеш-код. Причина этого в том, что метод equals() используется для проверки равенства двух объектов, а коллекции Java, такие как HashMap, используют хэш-код объекта для определения места его хранения.
Таким образом, если два объекта равны, они должны иметь одинаковый хеш-код, а если они не равны, они могут иметь одинаковые или разные хеш-коды.
Если вы переопределяете метод equals(), вы также должны переопределить метод hashCode(), чтобы гарантировать правильное поведение объектов. правильно в сборниках. Вот пример того, как реализовать эти методы в Java:
public class Person {
private String name;
private int age;
// constructor
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// equals() method
public boolean equals(Object obj) {
if (obj == this) return true;
if (!(obj instanceof Person)) return false;
Person person = (Person) obj;
return person.name.equals(name) && person.age == age;
}
// hashCode() method
public int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
result = 31 * result + age;
return result;
}
}
В этом примере метод equals() проверяет, имеют ли два объекта Person одинаковое имя и возраст. Метод hashCode() вычисляет хеш-код на основе имени и возраста человека по формуле 31 * результат + field.hashCode(). Обратите внимание, что в этой формуле часто используется простое число 31, поскольку оно обеспечивает хорошее распределение хэш-кодов.
1229. Если equals() переопределен, есть ли какие-либо другие методы, которые следует переопределить?
Когда вы переопределяете метод equals() в Java, часто вам также нужно переопределить метод hashCode(). Оба метода связаны друг с другом и работают вместе во многих алгоритмах, таких, например, как использование объектов в качестве ключей в HashMap.
Также вам может потребоваться переопределить метод toString(), чтобы удобно выводить информацию о вашем объекте при отладке или логгировании.
Кроме того, зависит от вашего класса и того, какие дополнительные методы и функциональность он предоставляет. Однако обычно переопределение equals(), hashCode() и toString() достаточно для большинства классов.
Однако, если вы реализуете интерфейс Comparable, переопределение метода compareTo() тоже может понадобиться. Это позволит вашему классу сортироваться по умолчанию, например, при использовании метода Collections.sort().
Также, если ваш класс имеет подклассы, вы можете захотеть сделать его методы equals(), hashCode() и toString() доступными для перекрытия в подклассах, сделав их protected.
В целом, следует рассмотреть все методы вашего класса и решить, какие из них должны быть переопределены для достижения нужного поведения и функциональности.
1230. Что будет, если переопределить equals() не переопределяя hashCode()? Какие могут возникнуть проблемы?
Если переопределить метод equals() без переопределения метода hashCode() в классе Java, то это может привести к проблемам при использовании объектов этого класса в коллекциях, основанных на хеш-функциях, таких как HashSet, HashMap и Hashtable.
Это связано с тем, что метод hashCode() возвращает целочисленное значение, которое используется хеш-таблицами для быстрого поиска элементов. Если hashCode() не переопределен, то хеш-значение объекта будет вычислено на основании его адреса в памяти, что может привести к проблемам с производительностью и корректностью работы хеш-таблиц.
Когда equals() переопределен, объекты, которые равны друг другу, должны иметь одинаковый хеш-код, чтобы хеш-функция могла правильно сгруппировать их в хеш-таблице. Если hashCode() не переопределен и не соответствует реализации equals(), то объекты могут иметь разные хеш-коды, что может привести к неправильной работе хеш-таблиц.
Поэтому при переопределении метода equals() обязательно следует также переопределить метод hashCode(), чтобы обеспечить корректную работу хеш-таблиц. Кроме того, реализация хорошего метода hashCode() помогает уменьшить количество коллизий в хеш-таблицах и повысить их эффективность.
1231. Каким образом реализованы методы hashCode() и equals() в классе Object?
Методы hashCode() и equals() в классе Object определены таким образом:
-
equals(): Этот метод принимает в качестве аргумента ссылку на другой объект. Он проверяет, равен ли текущий объект переданному объекту, и возвращает true, если они равны, и false в противном случае. По умолчанию, метод equals() реализует сравнение ссылок на объекты; он возвращает true только в том случае, если обе ссылки указывают на один и тот же объект. -
hashCode(): Этот метод возвращает хэш-код для объекта. Хэш-код это целое число, представляющее собой сокращенное описание объекта. Хэш-коды обычно используются для оптимизации работы с коллекциями, такими как HashMap и HashSet. Хэш-код является уникальным для каждого объекта в пределах текущего запуска программы.
По умолчанию, метод hashCode() возвращает уникальное целое число для каждого объекта, а метод equals() возвращает true, только если ссылки указывают на один и тот же объект. Если вы создаете собственный класс, то вы можете переопределить эти методы в соответствии с вашими потребностями. Если вы переопределяете метод equals(), то обычно вам нужно также переопределить метод hashCode(), чтобы он возвращал одно и то же значение для объектов, которые равны с точки зрения equals().
1232. Для чего нужен метод hashCode()?
В Java метод hashCode() используется для получения числового значения, которое можно использовать в качестве индекса в хэш-таблицах и других структурах данных. Метод hashCode() определен в классе Object, от которого наследуются все остальные классы в Java.
Классы, которые переопределяют метод equals(), также должны переопределить метод hashCode(), чтобы гарантировать, что два объекта, которые считаются равными согласно методу equals(), будут иметь одинаковое значение hashCode(). Это необходимо для того, чтобы объекты можно было использовать в качестве ключей в хэш-таблицах и других коллекциях, где производится поиск по хэш-коду объекта.
Например, если вы хотите использовать объект вашего собственного класса в качестве ключа в хэш-таблице, вам нужно будет переопределить методы equals() и hashCode(), чтобы гарантировать, что они работают должным образом. В противном случае, вы можете получить непредсказуемые результаты при поиске и извлечении элементов из коллекции.
Некоторые классы в стандартной библиотеке Java, такие как HashMap и HashSet, используют хэш-коды объектов для эффективного поиска, добавления и удаления элементов. Поэтому переопределение методов equals() и hashCode() особенно важно при работе со стандартными коллекциями в Java.
Метод hashCode() в Java используется для получения числового значения (хэш-кода) объекта. Хэш-код может быть использован для быстрого определения равенства двух объектов, а также для хранения объектов в хэш-таблицах. Чтобы гарантировать корректную работу хэш-таблиц, необходимо переопределить и метод equals(), чтобы он проверял только те поля объекта, которые также используются в вычислении хэш-кода.
Например, если вы создаете класс Person с полями name, age и id, то для корректной работы хэш-таблиц необходимо переопределить методы hashCode() и equals() следующим образом:
public class Person {
String name;
int age;
int id;
public int hashCode() {
return Objects.hash(name, age, id);
}
public boolean equals(Object obj) {
if (obj == this) {
return true;
}
if (!(obj instanceof Person)) {
return false;
}
Person other = (Person) obj;
return Objects.equals(name, other.name) &&
age == other.age &&
id == other.id;
}
}
Внутренний метод Objects.hash() вычисляет хэш-код объекта на основе переданных ему значений, а метод Objects.equals() сравнивает объекты на равенство, проверяя равенство их полей name, age и id.
1233. Каковы правила переопределения метода Object.hashCode()?
Когда вы создаете свой собственный класс в Java, вам может потребоваться определить метод hashCode() для этого класса. Метод hashCode() используется для вычисления хеш-кода (некоторого уникального числового значения) объекта, который может быть использован, например, в качестве ключа в хеш-таблице.
Правила переопределения метода hashCode() следующие:
- Если метод equals() возвращает true для двух объектов, то у них должны быть одинаковые хеш-коды.
- Если вы переопределяете метод hashCode(), то вы должны переопределить метод equals().
- Если два объекта равны (equals() возвращает true), то их хеш-коды также должны быть равны.
- Хеш-код должен быть вычисляемым за константное время и не изменяться в течение жизненного цикла объекта, если только какое-либо из его полей не изменится.
Кроме того, для уменьшения коллизий хеш-код должен быть равномерно распределен в пределах диапазона возможных значений (обычно int).
Пример корректного переопределения методов hashCode() и equals():
public class MyClass {
private int id;
private String name;
// constructors, getters, setters, etc.
@Override
public int hashCode() {
int result = 17;
result = 31 * result + id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
@Override
public boolean equals(Object o) {
if (o == this) return true;
if (!(o instanceof MyClass)) return false;
MyClass c = (MyClass) o;
return id == c.id && (name == null ? c.name == null : name.equals(c.name));
}
}
1234. Есть ли какие-либо рекомендации о том, какие поля следует использовать при подсчете hashCode()?
В Java есть несколько правил, которые полезно учитывать при написании метода hashCode() для своих объектов:
- Если два объекта равны (в соответствии с методом equals()), то их hashCode() должен возвращать одинаковое значение.
- Следует использовать те же поля объекта при вычислении hashCode(), которые используются в методе equals().
- Если изменяемое поле объекта влияет на результат работы метода equals(), то его также следует использовать при вычислении hashCode().
- При вычислении hashCode() лучше использовать числа простые.
Вот пример реализации метода hashCode() для простого класса Person, у которого есть поля name, age и id:
public class Person {
private String name;
private int age;
private long id;
@Override
public int hashCode() {
int result = 17; // начальное значение
result = 31 * result + name.hashCode(); // умножаем на простое число, чтобы получить более случайное число
result = 31 * result + age;
result = 31 * result + (int) (id ^ (id >>> 32)); // для long используем такой способ, чтобы отчасти сохранить случайность
return result;
}
// реализация equals() здесь
}
В этом примере мы используем простые числа 17 и 31, чтобы получить более "случайный" результат, а также включаем в вычисление идентификатор объекта типа long с помощью применения к нему побитовых операций.
1235. Могут ли у разных объектов быть одинаковые hashCode()?
Да, у разных объектов могут быть одинаковые значения hashCode(). Это называется коллизией хеша. Метод hashCode() в Java предназначен для создания хеш-кода объектов, который используется в хеш-таблицах и других структурах данных для обеспечения быстрого доступа к данным. Использование метода hashCode() обычно не гарантирует уникальность значений, поэтому для уравновешивания коллизий и обеспечения корректного функционирования структуры данных требуется переопределить метод equals(). Обычно, если два объекта считаются равными с помощью метода equals(), они должны иметь одинаковые хеш-коды, но не наоборот. Из-за этого можно реализовать метод hashCode() таким образом, чтобы он выдавал одинаковый результат для всех объектов, что иногда используется для упрощения кода.
Да, у разных объектов могут быть одинаковые значения hashCode() в Java. Однако, в идеале хорошо бы, чтобы коллизии, то есть ситуации, когда у разных объектов совпадает hashCode(), были бы минимальными, так как это может повлиять на производительность многих структур данных, например HashMap или HashSet. Чтобы уменьшить количество коллизий, можно переопределить метод hashCode() в вашем классе. Хэш-функция должна быть реализована таким образом, чтобы с большой вероятностью различные объекты давали разные хэш-коды. Кроме того, если два объекта имеют одинаковый хэш-код, то необходимо переопределить еще метод equals() для корректного сравнения объектов по значениям их полей.
Вот пример переопределения метода hashCode() в классе Person:
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
}
Здесь мы используем метод hashCode() из класса String для получения хэш-кода поля name и добавляем его к результату. Поле age просто складываем с сдвинутой на 5 позиций налево константой 31. Примечание, что использовать слишком простые хэш-функции может приводить к увеличению количества коллизий, а избыточно сложные могут земедлять вычисления hashCode.
Хорошая хэш-функция должна обеспечивать равномерное распределение значений хэшей для различных входных данных, чтобы минимизировать количество коллизий.
Использование слишком простых хэш-функций, таких как простое деление или умножение на константу, может привести к большому количеству коллизий. Это происходит потому, что такие функции не учитывают особенности входных данных и могут приводить к сосредоточению значений хэшей в определенных областях.
С другой стороны, избыточно сложные хэш-функции могут замедлить процесс хэширования. Если хэш-функция требует большого количества вычислений или использует сложные алгоритмы, это может увеличить время выполнения операций хэширования. В некоторых случаях, когда производительность критически важна, может быть целесообразно использовать более простые хэш-функции, даже если это приводит к некоторому увеличению количества коллизий.
В идеале, хорошая хэш-функция должна обеспечивать равномерное распределение значений хэшей для различных входных данных и иметь низкую вероятность коллизий. Она должна быть эффективной с точки зрения времени выполнения и должна учитывать особенности конкретной задачи или набора данных, с которыми она будет использоваться.
Важно выбирать хэш-функцию, которая соответствует требованиям конкретной задачи и обеспечивает баланс между производительностью и минимизацией коллизий.
1236. Если у класса Point{int x, y;} реализовать метод equals(Object that) {(return this.x == that.x && this.y == that.y)}, но сделать хэш код в виде int hashCode() {return x;}, то будут ли корректно такие точки помещаться и извлекаться из HashSet?
Если реализовать метод equals(Object that) таким образом: (return this.x == that.x && this.y == that.y) , а метод hashCode() вернуть только одно значение x, то вероятность коллизий в HashSet будет высокой. Это потому, что HashSet использует метод hashCode() для размещения элементов в таблице. При такой реализации две точки (x1, y1) и (x2, y2) будут помещаться в таблицу HashSet в одно и то же место (в одну и ту же ячейку), если их координаты по оси X совпадают:
new Point(1, 2).hashCode() == new Point(1, 5).hashCode() // true
Таким образом, необходимо обеспечить уникальный хэш для каждой точки, чтобы избежать коллизий. Один из способов сделать это - использовать хэш-функцию, которая учитывает обе координаты точки:
public int hashCode() {
return Objects.hash(x, y);
}
Такая реализация гарантирует уникальный хэш для каждой точки и позволит корректно помещать и извлекать точки из HashSet.
1237. Могут ли у разных объектов (ref0 != ref1) быть ref0.equals(ref1) == true?
Да, это возможно. Метод equals() определяет, равен ли один объект другому, и он может быть переопределен в Java классах пользовательского интерфейса. Если два объекта равны, их хэш-коды должны быть равными. Однако, если хэш-коды равны, объекты могут не быть равными.
Итак, (ref0 != ref1) является проверкой на несоответствие ссылок на два разных объекта, а ref0.equals(ref1) == true означает, что содержимое этих объектов равны друг другу по сравнению методом equals().
1238. Могут ли у разных ссылок на один объект (ref0 == ref1) быть ref0.equals(ref1) == false?
Да, у разных ссылок на один объект (ref0 == ref1) может быть ref0.equals(ref1) == false. Метод equals() определяет, равны ли два объекта с точки зрения их значений. Однако == сравнивает ссылки на объекты. Если у двух ссылок разные адреса, то при сравнении с помощью equals() они будут считаться неравными. Например, для двух разных объектов String с одинаковыми значениями "hello" и "hello", метод equals() вернет true, но при сравнении ссылок с помощью оператора ==, они будут не равными.
1239. Можно ли так реализовать метод equals(Object that) {return this.hashCode() == that.hashCode()}?
Хотя технически возможно реализовать метод equals(Object that) путем сравнения хэш-кодов, обычно не рекомендуется полагаться на хэш-коды для сравнения объектов на равенство. Это связано с тем, что хэш-коды не обязательно будут уникальными и могут конфликтовать между разными объектами.
Лучшим подходом является сравнение фактических полей или атрибутов двух объектов, чтобы определить, равны ли они. Это можно сделать, переопределив метод equals и затем сравнив соответствующие поля или атрибуты двух объектов.
Вот пример того, как переопределить метод equals с помощью оператора instanceof, чтобы проверить, относится ли другой объект к тому же классу, а затем сравнить соответствующие поля или атрибуты:
public class MyClass {
private int value;
@Override
public boolean equals(Object other) {
if (other == this) {
return true;
}
if (!(other instanceof MyClass)) {
return false;
}
MyClass that = (MyClass) other;
return this.value == that.value;
}
// other methods and constructors...
}
В этом примере метод equals сначала проверяет, является ли другой объект тем же самым объектом, что и this, используя ссылочное равенство (other == this). Если это правда, то объекты равны, поэтому возвращается true. В противном случае он проверяет, является ли другой объект экземпляром MyClass, используя оператор instanceof. Если это не экземпляр MyClass, он возвращает false. Если это экземпляр MyClass, он приводит другой объект к MyClass, а затем сравнивает поле значения, чтобы определить равенство.
Обратите внимание, что при переопределении равенства вы также должны переопределить метод hashCode, чтобы гарантировать, что одинаковые объекты имеют одинаковый хэш-код. Это важно при использовании объектов в качестве ключей в структурах данных на основе хэшей, таких как HashMap.
В общем, рекомендуется определять равенство таким образом, который согласуется с поведением идентификатора объекта (==). Например, два объекта, которые равны по своим полям, также должны быть равны при сравнении с использованием ==.
1240. В equals() требуется проверять, что аргумент equals(Object that) такого же типа что и сам объект. В чем разница между this.getClass() == that.getClass() и that instanceof MyClass?
В методе equals(Object that) требуется проверять, что аргумент that является объектом того же класса, что и сам объект. Это делается для того, чтобы убедиться, что сравниваемые объекты имеют одинаковые поля и свойства, и могут быть считаны эквивалентными.
Существуют два способа проверки, что аргумент that является объектом того же класса. Первый способ - это сравнение классов объекта и аргумента сравнения с помощью оператора ==. Код для этого выглядит так: this.getClass() == that.getClass(). Второй способ - это использование оператора instanceof, что позволяет проверить, является ли аргумент объектом того же класса или производного класса, что и сам объект. Код для этого выглядит так: that instanceof MyClass.
Оба способа можно использовать в качестве проверки на соответствие типа сравниваемых объектов. Однако, предпочтительнее использовать оператор instanceof, так как он охватывает более широкий диапазон объектов. Также, оператор instanceof используется, когда требуется проверить, является ли аргумент членом определенного класса или его наследника.
1241. Можно ли реализовать метод equals() класса MyClass вот так: class MyClass {public boolean equals(MyClass that) {return this == that;}}?
Да, метод equals() класса MyClass можно реализовать следующим образом:
class MyClass {
public boolean equals(MyClass that) {
return this == that;
}
}
Однако эта реализация проверяет только, являются ли оба объекта идентичными экземплярами, а это означает, что два объекта должны занимать одну и ту же ячейку памяти. Эта реализация не проверяет, совпадают ли значения свойств двух объектов.
В большинстве случаев метод equals() используется для определения того, имеют ли два объекта одинаковое состояние, а не для того, чтобы определить, являются ли объекты одним и тем же экземпляром. Для проверки равного состояния обычно переопределяют метод equals() и проверяют свойства двух объектов.
1242. Есть класс Point{int x, y;}. Почему хэш код в виде 31 * x + y предпочтительнее чем x + y?
Причина, по которой хеш-код для класса вроде Point реализован как 31 * x + y, заключается в том, что он помогает уменьшить количество коллизий между объектами при их хэшировании.
Умножение на 31 — обычная практика в Java для вычисления хэш-кодов, потому что 31 — нечетное простое число, а умножение на нечетное простое число помогает более равномерно распределить хэш-коды по хеш-таблице. Формула 31*x+y — лишь одна из многих возможных формул для вычисления хеш-кодов, и ее эффективность может зависеть от конкретного варианта использования и характеристик хэшируемых объектов.
1243. Расскажите про клонирование объектов.
Клонирование объектов в Java происходит с помощью метода Object.clone(). Этот метод создаёт и возвращает копию объекта. Класс объекта, который мы хотим клонировать, должен реализовать интерфейс Cloneable и переопределить метод clone().
Но есть некоторые особенности процесса клонирования в Java:
- Метод clone() не является public, поэтому его нельзя вызвать из другого класса. Для клонирования объекта, необходимо создать публичный метод, вызывающий метод clone() для соответствующего объекта.
- Если класс объекта не реализует интерфейс Cloneable, то его клонирование приведёт к исключению CloneNotSupportedException.
- Клонирование объектов в Java происходит по значению, а не по ссылке, поэтому изменения в клонированном объекте не повлияют на исходный объект.
Например, если у нас есть класс Person, то мы можем клонировать его так:
public class Person implements Cloneable {
private String name;
private int age;
// конструкторы, геттеры и сеттеры
public Person clone() throws CloneNotSupportedException {
return (Person) super.clone();
}
}
И затем создаем новый объект примерно так:
Person person1 = new Person("John", 35);
Person person2 = person1.clone();
Person person2 — это клон объекта person1, который сохраняет его состояние в момент клонирования. Python также имеет подобный механизм клонирования.
1244. В чем отличие между поверхностным и глубоким клонированием?
В Java есть два способа клонирования объектов - поверхностное клонирование (shallow cloning) и глубокое клонирование (deep cloning).
При поверхностном клонировании новый объект создается, и его поля заполняются ссылками на те же самые объекты, на которые ссылается клонируемый объект. В результате изменение этих объектов может отразиться как на клонированном объекте, так и на исходном объекте.
При глубоком клонировании создается новый объект, и его поля заполняются копиями объектов, на которые ссылается клонируемый объект. Таким образом, изменение этих объектов не отразится на клонированных объектах и на исходном объекте.
Для реализации глубокого клонирования в Java можно использовать интерфейс Cloneable и метод clone(). Однако, для корректной реализации глубокого клонирования необходимо обеспечить правильную работу clone() для всех полей, включая поля ссылочного типа.
Например, реализация глубокого клонирования может выглядеть следующим образом:
public class MyClass implements Cloneable {
private int myField;
private MyOtherClass myOtherField;
@Override
public Object clone() throws CloneNotSupportedException {
// Вызываем метод clone() у суперкласса для клонирования объекта
MyClass clone = (MyClass) super.clone();
// Клонируем поле myOtherField
clone.myOtherField = (MyOtherClass) myOtherField.clone();
return clone;
}
}
1245. Какой способ клонирования предпочтительней?
Преимущества каждого из способов клонирования зависят от конкретной ситуации, в которой он используется. При поверхностном клонировании копируются только ссылки на объекты, а не сами объекты, что может привести к тому, что изменения в одном объекте могут повлиять на другой. При глубоком клонировании копируются также и сам объект, что делает каждую копию отдельной и не зависящей от оригинала.
Чаще всего в Java для клонирования используют метод clone(), который выполняет поверхностное клонирование. Однако при необходимости провести глубокое клонирование, необходимо реализовывать интерфейс Cloneable и переопределять метод clone(), чтобы скопировать все поля объекта и объекты, на которые ссылаются поля. Для простых объектов, глубокое клонирование может быть не таким сложным, но для сложных объектов может потребоваться дополнительное управление, что может затруднить реализацию.
1246. Почему метод clone() объявлен в классе Object, а не в интерфейсе Cloneable?
В Java метод clone() объявлен в классе Object, а не в интерфейсе Cloneable, потому что он позволяет создать и вернуть новый объект, который является копией исходного объекта. Таким образом, метод clone() относится к функционалу языка, предоставляемому всем объектам в Java Runtime, а не только тем, которые реализуют интерфейс Cloneable.
Интерфейс Cloneable в Java не имеет методов, он является "маркерным интерфейсом", показывающим, что класс, реализующий этот интерфейс, поддерживает клонирование. Если класс не реализует интерфейс Cloneable, то при вызове метода clone() у него возникнет исключение CloneNotSupportedException.
Таким образом, метод clone() предназначен для создания копии объекта, что может потребоваться при многопоточном программировании, где разные потоки могут использовать один и тот же объект.
1247. Опишите иерархию исключений.
В Java иерархия исключений представлена классом Throwable, который имеет два основных наследника: классы Error и Exception.
Класс Error описывает ошибки, которые вызываются внутренними проблемами виртуальной машины Java, такие как ошибки выделения памяти (OutOfMemoryError). Обрабатывать исключения класса Error не следует, так как они не подлежат исправлению программными средствами.
Класс Exception описывает исключения, которые вызываются проблемами в работе программы. Этот класс имеет несколько наследников, например RuntimeException, IOException и другие. RuntimeException описывает исключения, которые могут быть предотвращены программистом и имеют отношение к ошибкам программы во время выполнения.
Для обработки исключений в Java используют оператор try-catch. В операторе try записывается блок кода, в котором может возникнуть исключение. Далее в блоке catch указывается исключение, которое необходимо обработать. Если исключение возникает в блоке try, программа переходит в блок catch, где выполняется обработка ошибки.
Например, следующий код демонстрирует использование оператора try-catch:
try {
// Блок кода, в котором может возникнуть исключение
} catch(Exception e) {
// Обработка исключения, вывод сообщения об ошибке и т.п.
}
Также можно определить собственное исключение, которое будет наследоваться от класса Exception, и использовать его в своей программе. Для этого необходимо создать класс исключения и указать, что он наследуется от класса Exception.
1248. Какие виды исключений в Java вы знаете, чем они отличаются?
В Java есть два вида исключений: проверяемые (checked) и непроверяемые (unchecked).
Проверяемые исключения - это исключения, которые должны быть обработаны или перехвачены в блоке try-catch, иначе компилятор не позволит скомпилировать код.
Непроверяемые исключения, также известные как RuntimeException, не обязательно должны быть обработаны или перехвачены, и их можно не указывать в сигнатуре методов.
Некоторые примеры проверяемых исключений в Java: IOException, SQLException, ClassNotFoundException.
Примеры непроверяемых исключений: NullPointerException, ArrayIndexOutOfBoundsException, ArithmeticException.
Непроверяемые исключения обычно возникают из-за ошибок программиста, таких как доступ к null ссылке или деление на ноль, в то время как проверяемые исключения могут возникнуть по разным причинам, таким как проблемы с вводом-выводом, базы данных и т.д.
Учитывайте, что некоторые исключения наследуются от Error, а не от Exception и не являются ни проверяемыми, ни непроверяемыми исключениями. Например, StackOverflowError и OutOfMemoryError.
1249. Что такое checked и unchecked exception?
В Java checked и unchecked exceptions - это два типа исключений. Checked исключения должны быть обрабатываны или объявлены в заголовке метода с помощью слова ключевого слова throws, в то время как unchecked исключения не обязаны быть обработаны или объявлены. Компилятор Java гарантирует, что программа предоставляет обработку checked исключений, но не гарантирует это для unchecked исключений.
Примеры checked exception:
- IOException
- ClassNotFoundExceptio
- SQLException
Примеры unchecked exception:
- NullPointerException
- ArrayIndexOutOfBoundsException
- IllegalArgumentException
Как именно обрабатывать исключения в вашем коде зависит от конкретных требований вашей программы, но в общих чертах, checked исключения обычно следует обрабатывать в коде, а unchecked исключения следует использовать для ошибок, которые маловероятно произойдут, и которые обычно указывают на ошибки программиста.
1250. Какой оператор позволяет принудительно выбросить исключение?
В Java, оператор, который позволяет явно выбросить исключение, называется throw. Он используется для выброса исключения из блока try в случае возникновения ошибки. Например:
if (x < 0) {
throw new IllegalArgumentException("x must be non-negative");
}
Этот код выбросит исключение IllegalArgumentException в случае, если значение переменной x меньше нуля. Конструктору IllegalArgumentException передается сообщение, которое будет содержаться в исключении.
Кроме того, оператор throw можно использовать для перехвата исключения в одном методе и выброса его в вызывающий метод. Например:
public void doSomething() throws SomeException {
try {
// some code that might throw SomeException
} catch (SomeException e) {
// handle the exception
throw e; // re-throw the same exception to the caller
}
}
Здесь метод doSomething() может выбросить исключение SomeException. Если это происходит, оно перехватывается в блоке catch и обрабатывается. Затем исключение снова выбрасывается с помощью оператора throw для передачи его в вызывающий метод.
1251. О чем говорит ключевое слово throws?
В Java ключевое слово throws используется в объявлении метода, чтобы указать, что метод может бросать исключение определенного типа. Это означает, что при вызове этого метода в коде, вызывающий код должен либо также бросить это исключение, либо обработать его с помощью блока try-catch. Например, следующий метод бросает исключение типа MyException:
public void doSomething() throws MyException {
// code here
}
Если метод вызывается в другом методе, который также не обрабатывает это исключение, то исключение будет передано выше по стеку вызовов, наконец будет передано в вызывающий метод, который должен обработать исключение.
Использование ключевого слова throws является хорошей практикой программирования, которая позволяет обработать исключения и сделать код более предсказуемым и надежным.
1252. Как написать собственное («пользовательское») исключение?
В Java можно создавать пользовательские исключения с помощью создания нового класса, который наследуется от класса Exception или его подклассов. Для создания пользовательского исключения необходимо определить конструктор, который вызывает конструктор родительского класса, и добавить необходимые поля, методы и свойства.
Вот пример простого пользовательского исключения в Java:
public class MyException extends Exception {
public MyException() {
super("This is my custom exception.");
}
}
Вы можете заменить "This is my custom exception." на сообщение об ошибке, которое вы хотите отобразить при возникновении этого исключения.
Чтобы использовать этот пользовательский класс исключения, вы можете создать экземпляр этого класса и вызвать метод throw с помощью ключевого слова throw. Например:
try {
throw new MyException();
} catch (MyException e) {
System.err.println(e.getMessage());
}
В этом примере при возникновении исключения MyException будет выведено сообщение "This is my custom exception.".
1253. Какие существуют unchecked exception?
В Java существует несколько типов непроверяемых (unchecked) исключений, включая:
-
RuntimeException и его подклассы (например, NullPointerException, IllegalArgumentException, IndexOutOfBoundsException, ClassCastException, ArithmeticException)
-
Error и его подклассы (например, OutOfMemoryError, StackOverflowError)
Непроверяемые исключения отличаются от проверяемых (checked) исключений тем, что компилятор не требует их обработки или объявления в блоке throws. При возникновении непроверяемого исключения, оно может быть перехвачено в блоке try-catch или может передаться на уровень выше в стеке вызовов вызывающих методов. Если исключение не перехватывается на всех уровнях вызова и достигает верхнего уровня, программа может завершиться с сообщением об ошибке.
1254. Что представляет из себя ошибки класса Error?
Ошибка класса Error в Java является подклассом класса Throwable. Как и у всех классов-исключений в Java, есть множество подклассов у Error. Эти подклассы позволяют разработчикам более точно определять ошибку, которая произошла в программе.
Error является необрабатываемым исключением, то есть он является ошибкой в работе Java Virtual Machine, которая свидетельствует о том, что приложение не может продолжить нормально работать. Некоторые примеры известных подклассов Error в Java включают StackOverflowError, OutOfMemoryError, AssertionError и LinkageError.
Поскольку Error является необрабатываемым исключением, он не должен ловиться и обрабатываться в программе. Вместо этого, если возникает ошибка Error, лучше просто попробовать исправить ее и перезапустить приложение.
1255. Что вы знаете о OutOfMemoryError?
OutOfMemoryError — это исключение времени выполнения в языке программирования Java, которое возникает, когда больше не остается памяти для выделения программой. Эта ошибка обычно возникает, когда память кучи, выделенная для программы, исчерпана, что может быть вызвано различными факторами, такими как создание слишком большого количества объектов, неправильная сборка мусора или загрузка больших объектов в память.
Существует несколько стратегий обработки OutOfMemoryError, в том числе увеличение размера кучи с помощью параметра JVM -Xmx или оптимизация программы для более эффективного использования памяти за счет уменьшения количества создаваемых объектов, повторного использования существующих объектов и надлежащего удаления объектов, которые больше не требуются. .
OutOfMemoryError — это распространенная проблема в программах Java, и разработчикам важно знать о возможных причинах и решениях этой ошибки.
1256. Опишите работу блока try-catch-finally.
Блок try-catch-finally - это механизм обработки исключений в Java.
В блоке try содержится код, который нужно выполнить. Если в процессе выполнения этого кода возникает исключение, то выполняется блок catch с соответствующим типом исключения, в котором можно обработать это исключение или выполнить соответствующие действия. Если исключение не было обработано в блоке catch, оно продолжает распространяться по методам, пока не будет обработано или программа не завершится.
Блок finally содержит код, который должен выполниться в любом случае, независимо от того, было ли выкинуто исключение или нет. В этом блоке можно выполнить необходимые действия по очистке ресурсов, закрытию потоков и т.д.
Пример использования блока try-catch-finally:
try {
// выполнение кода, который может выкинуть исключение
} catch (SomeException e) {
// обработка исключения
} finally {
// выполнение кода, который должен выполниться в любом случае
}
1257. Что такое механизм try-with-resources?
Механизм try-with-resources - это нововведение в Java 7, которое предоставляет более простой и безопасный способ управления ресурсами, такими как файлы и сетевые соединения, в блоках try-catch. Когда вы используете try-with-resources, вы можете определить один или несколько ресурсов в заголовке блока try, после чего он будет автоматически закрыт при завершении блока try. Это особенно удобно при работе с ресурсами, которые могут поломаться или неожиданно закрыться, например, при работе с файлами или сетевыми соединениями.
Вот пример использования try-with-resources для чтения строк из файла:
try (BufferedReader br = new BufferedReader(new FileReader("myfile.txt"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
System.err.println("Failed to read file: " + e.getMessage());
}
Здесь BufferedReader и FileReader оба являются ресурсами, которые будут автоматически закрыты при завершении блока try. Это гарантирует, что ресурсы будут корректно закрыты, даже если произойдет исключение в блоке try.
1258. Возможно ли использование блока try-finally (без catch)?
Да, блок try-finally можно использовать без catch. Блок finally содержит код, который всегда исполняется, независимо от того, было исключение в блоке try или нет. Он часто используется для того, чтобы выполнить какие-то заключительные действия, например, закрыть файл или соединение с базой данных, которые необходимо выполнить независимо от того, были ошибки или нет. Вот пример использования блока try-finally без catch:
try {
// выполнение кода
} finally {
// код, который должен быть выполнен независимо от наличия исключения
}
1258. Может ли один блок catch отлавливать сразу несколько исключений?
Да, в Java блок catch может отлавливать сразу несколько исключений. Для этого необходимо перечислить их через символ |:
try {
// some code that might throw exceptions
} catch (IOException | ParseException e) {
// handle IOException or ParseException
}
В этом примерe блок catch может обработать как IOException, так и ParseException. Обратите внимание, что типы исключений должны быть связаны отношением "is-a" (наследование в Java). Если типы не связаны, то необходимо использовать несколько блоков catch для каждого типа исключений.
1259. Всегда ли исполняется блок finally?
В Java блок finally будет выполнен всегда, даже если было возбуждено исключение в try блоке и это исключение не было перехвачено в соответствующем catch блоке. Код в блоке finally предназначен для выполнения затратных операций, таких как закрытие файла или соединения, независимо от того, было ли выполнено нормальное завершение блока try или произошло исключение. Вот пример, который демонстрирует это поведение:
try {
// Какой-то код, который может вызвать исключение
} catch (Exception e) {
// Обработка исключения
} finally {
// Блок finally, который будет выполнен независимо от того, было или нет исключение
// например, закрытие открытого ресурса
}
1260. Существуют ли ситуации, когда блок finally не будет выполнен?
В основном блок finally в Java выполняется всегда, кроме нескольких случаев:
-
Если выполнение JVM прерывается или происходит выход по ошибке системы, например, с помощью вызова System.exit() в блоке try или catch.
-
Если возникает бесконечный цикл, или программа зависает.
-
Если выполняется неконтролируемый блок кода, такой как бесконечный цикл.
Однако, если в блоке try или catch встречается оператор return, try или catch сразу же завершается и управление передается в вызывающую функцию, и только потом блок finally выполняется.
Также блок finally не будет выполнен, если в блоке try или catch возникает ошибку OutOfMemoryError, которая связана с нехваткой памяти.
Во всех других случаях блок finally будет выполнен.
1261. Может ли метод main() выбросить исключение во вне и если да, то где будет происходить обработка данного исключения?
Да, метод main() в Java может генерировать исключение, и если это произойдет, исключение будет распространено на JVM. Если исключение не обрабатывается программой, JVM напечатает трассировку стека и завершит программу. Если исключение перехватывается и обрабатывается в main() (или любом другом методе, вызываемом main()), то программа может продолжить выполнение.
Однако, если исключение перехватывается и не выбрасывается повторно или не распространяется дальше, программа также завершится.
Вот пример метода main(), который генерирует исключение:
public class Main {
public static void main(String[] args) throws Exception {
throw new Exception("An error occurred");
}
}
В этом примере метод main() создает новый объект Exception с сообщением об ошибке. Предложение «throws Exception» в сигнатуре метода указывает, что этот метод может генерировать исключение типа Exception.
Обратите внимание, что в приведенном выше примере исключение не перехватывается и не обрабатывается, поэтому программа завершает работу и печатает трассировку стека исключения.
Если вы хотите перехватить и обработать исключение, вы можете окружить код, выбрасывающий исключение, блоком try-catch:
public class Main {
public static void main(String[] args) {
try {
throw new Exception("An error occurred");
} catch (Exception e) {
System.out.println("Caught an exception: " + e.getMessage());
}
}
}
В этом примере блок try содержит код, вызывающий исключение, а блок catch перехватывает исключение и выводит сообщение на консоль.
Обратите внимание, что нам не нужно указывать «выбрасывает исключение» в сигнатуре метода, так как теперь мы перехватываем исключение и обрабатываем его в методе main().
1262. Предположим, есть метод, который может выбросить IOException и FileNotFoundException в какой последовательности должны идти блоки catch? Сколько блоков catch будет выполнено?
Когда метод может выбросить IOException и FileNotFoundException, настоятельно рекомендуется обработать каждое исключение в отдельном блоке catch. Если мы решим поместить оба исключения в один блок catch, то нам придется добавить дополнительный код для определения, какое исключение было выброшено. Проще всего разместить два блока catch, которые следуют друг за другом:
try {
// Код, который может выбросить IOException
} catch (IOException e) {
// Обработка IOException
}
try {
// Код, который может выбросить FileNotFoundException
} catch (FileNotFoundException e) {
// Обработка FileNotFoundException
}
В этом случае каждое исключение будет обработано отдельно, и такой подход упрощает код обработки исключений и делает его более понятным. Если оба блока catch были задействованы, то оба будут выполнены.
Пример кода для обработки этих исключений:
try {
// some code that may throw IOException or FileNotFoundException
} catch (IOException e) {
// handle IOException
} catch (FileNotFoundException e) {
// handle FileNotFoundException
}
1263. Что такое generics?
Generics - это механизм в Java, который позволяет создавать классы, интерфейсы и методы, которые работают с параметризованными типами данных. Использование Generics позволяет писать более безопасные и переиспользуемые программы, поскольку компилятор Java может проверять типы данных во время компиляции.
К примеру, если вы хотите иметь класс, который может работать с любым типом данных (например, LinkedList), используя Generics, вы можете написать его так:
public class LinkedList<T> {
private Node<T> head;
public void add(T value) {
// добавляем элемент в связанный список
}
private class Node<T> {
T value;
Node<T> next;
}
}
Теперь, когда вы создаете экземпляр LinkedList, вы можете указать тип данных, с которым он будет работать, например:
LinkedList<String> list = new LinkedList<String>();
list.add("hello");
Здесь тип T заменен на String. Это означает, что LinkedList будет работать только с объектами типа String, и компилятор Java будет проверять типы для вас.
Generics также позволяют создавать обобщенные интерфейсы и методы, что дает еще больше возможностей для переиспользования кода в Java.
1264. Что такое «интернационализация», «локализация»?
"Интернационализация" и "локализация" - это две связанные между собой концепции, которые важны для разработчиков программного обеспечения, особенно для тех, кто работает с приложениями, предназначенными для использования в разных языковых и региональных настройках.
"Интернационализация", также известная как "i18n" (где "18" обозначает количество букв между "i" и "n" в слове "internationalization"), означает разработку приложения таким образом, чтобы оно было легко адаптируемо для использования в различных языках и регионах. Это может включать в себя использование мультиязычных текстовых строк, поддержку разных форматов даты и времени, форматирование чисел и валют в соответствии с настройками локали и т.д.
"Локализация", известная как "l10n" (где "10" обозначает количество букв между "l" и "n" в слове "localization"), это процесс адаптации приложения для конкретной локали, включая перевод текстовых строк на местный язык, адаптацию форматов даты и времени, чисел и валют, а также учёт местных традиций и обычаев.
В Java есть множество классов и инструментов для работы с "i18n" и "l10n", такие как Locale, ResourceBundle, ListResourceBundle, NumberFormat, DateFormat, MessageFormat и многие другие, которые могут помочь разработчикам создавать приложения.
4 Блок вопросов
1265. Что мы знаем о методе main
Метод main, который находится внутри класса, является входной точкой программы на Java. Он выполняется при запуске приложения виртуальной машины Java (JVM) и предоставляет ей необходимые для запуска приложения параметры.
Сигнатура метода main обязательно должна иметь вид public static void main(String[] args) , где public - модификатор доступа, static - ключевое слово означающее что данный метод является методом класса, void - указывает на то, что метод не возвращает значения, main - имя метода, String[] args - аргументы (параметры) командной строки, которые могут быть переданы программе при запуске.
Пример вызова метода main:
public class MyProgram {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
Запуск программы:
$ javac MyProgram.java
$ java MyProgram
Этот код выведет "Hello World!" в консоль.
1266. Что такое массивы в Java
В Java массив это упорядоченная коллекция элементов определенного типа данных. Каждый элемент массива имеет индекс, начинающийся с нуля. Тип данных элементов массива должен быть одним из примитивных типов данных (например, int, float, char) или же объектом класса. Чтобы создать массив, нужно указать тип данных его элементов и количество элементов в квадратных скобках. Ниже приведен пример объявления и заполнения массива типа int в Java:
int[] myArray = new int[3]; // создание массива из трех элементов типа int
myArray[0] = 1; // присваивание первому элементу значения 1
myArray[1] = 2; // присваивание второму элементу значения 2
myArray[2] = 3; // присваивание третьему элементу значения 3
1267. Какой класс реализует динамический массив в Java, и что мы можем про него рассказать?
В Java динамический массив реализуется с помощью класса ArrayList. ArrayList является обобщенным классом, который позволяет создавать массивы переменного размера, автоматически изменяющие свой размер при добавлении или удалении элементов. Он реализует интерфейс List и позволяет выполнять множество операций, включая добавление, удаление и поиск элементов, а также доступ по индексу.
ArrayList в Java является реализацией динамического массива, который позволяет хранить элементы одного типа. ArrayList может расширяться по мере необходимости при добавлении элементов в список, и освобождаться при удалении элементов.
Важно помнить, что ArrayList может затратить больше памяти, чем обычный массив в Java, так как он динамически изменяет свой размер. Однако, в большинстве случаев ArrayList обеспечивает более удобный и гибкий способ работы с массивами, особенно когда нужно работать с изменяемыми массивами.
Пример использования ArrayList в Java:
import java.util.ArrayList;
ArrayList<String> list = new ArrayList<String>();
list.add("element 1");
list.add("element 2");
Здесь создается список строк, который можно заполнять добавлением новых элементов методом add()
Когда ArrayList создается, он имеет некоторую начальную емкость, которая по умолчанию равна 10. Если вы знаете, что вам понадобится больше места, чем это, вы можете указать начальную емкость при создании ArrayList, чтобы избежать ресайзинга массива и получить лучшую производительность.
Еще одна важная деталь - при увеличении размера массива происходит копирование всех элементов в новый массив, что может приводить к дополнительным затратам по производительности, если ArrayList содержит большое количество элементов.
1268. За счет чего NIO обеспечивает неблокируемый доступ к ресурсам?
Java NIO (расшифровывается как Non-blocking Input/Output) — это библиотека на Java, которая предоставляет альтернативу традиционному блокирующему API-интерфейсу ввода-вывода, предоставляемому пакетом java.io. Он был представлен в Java 1.4 и предлагает такие функции, как отображаемые в память файлы, масштабируемый ввод-вывод, блокировка файлов и неблокирующий ввод-вывод сокетов. NIO основан на концепции каналов и буферов, которые обеспечивают более эффективные и гибкие операции ввода-вывода по сравнению с потоковым вводом-выводом, предоставляемым java.io.
Одним из преимуществ NIO является возможность выполнять неблокирующий ввод-вывод, что позволяет одному потоку обрабатывать несколько операций ввода-вывода без блокировки и, таким образом, повышает масштабируемость и производительность в сценариях с высокой нагрузкой. Кроме того, NIO поддерживает использование селекторов для мультиплексирования операций ввода/вывода в нескольких сокетах, что позволяет одному потоку обрабатывать несколько каналов, дополнительно повышая производительность и использование ресурсов.
Java NIO (Non-blocking IO) обеспечивает неблокируемый доступ к ресурсам за счет асинхронности и использования буферов. В противоположность традиционным библиотекам ввода/вывода, которые являются блокирующими, Java NIO позволяет выполнять несколько операций ввода/вывода одновременно в одном потоке, используя меньше потоков и ресурсов. Это достигается за счет услуг, таких как каналы, селекторы и буферы, которые обеспечивают асинхронную, неблокируемую передачу данных между процессом и ядром операционной системы. Селекторы позволяют процессу мониторить несколько каналов для ввода/вывода, в то время как буферы обеспечивают быстрое чтение и запись данных.
1269. Как работает CopyOnWriteArrayList
CopyOnWriteArrayList — это потокобезопасный вариант ArrayList в Java. Основная идея заключается в том, что он создает новую копию базовой структуры данных для каждой операции записи (добавление, установка, удаление), и эта копия затем становится доступной для чтения всеми потоками, в то время как исходный массив остается неизменным. Это означает, что любые операции чтения всегда будут иметь согласованное представление данных, которые существовали во время последней операции записи, без необходимости использования блокировок для синхронизации. Хотя это обеспечивает преимущества потокобезопасности и параллелизма, это может привести к проблемам с производительностью, когда речь идет о приложениях с интенсивной записью, поскольку создание новой копии структуры данных для каждой операции записи может быть дорогостоящим с точки зрения использования памяти и ЦП. циклы. Важно отметить, что CopyOnWriteArrayList полезен только в определенных случаях, когда количество операций записи мало по сравнению с количеством операций чтения, иначе это может вызвать проблемы с памятью при большом объеме данных. копируется при каждой операции обновления. Вот пример использования CopyOnWriteArrayList в Java:
import java.util.concurrent.CopyOnWriteArrayList;
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("item1");
list.add("item2");
String firstItem = list.get(0);
list.remove(1);
Это создаст новый CopyOnWriteArrayList, добавит к нему два строковых элемента, извлечет первый элемент и удалит второй элемент из списка.
1270. Что такое Stream в контексте Stream API?
В контексте Stream API в Java, Stream - это последовательный поток элементов, которые можно получить из источника данных, например, коллекции, массива или файла. Stream можно фильтровать, преобразовывать и обрабатывать параллельно. Stream API был введен в Java 8 и облегчает обработку и анализ больших объемов данных, уменьшает количество кода и позволяет писать более читабельный и функциональный код. Например, вы можете использовать Stream API для фильтрации списка объектов по определенному критерию и получения нового списка, содержащего только отфильтрованные элементы. Работа со Stream API требует различных методов, таких как filter(), map(), reduce() и других, которые можно использовать для обработки данных.
Функция filter() отфильтровывает элементы, которые не соответствуют определенному условию:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> even = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
System.out.println(even); // [2, 4, 6]
Функция map() применяет функцию к каждому элементу потока и создает новый поток с преобразованными элементами:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
List<Integer> squares = numbers.stream()
.map(n -> n * n)
.collect(Collectors.toList());
System.out.println(squares); // [1, 4, 9, 16, 25, 36]
Функция reduce() используется для выполнения агрегирующих операций на элементах потока и возвращает единственный результат:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
int sum = numbers.stream()
.reduce(0, (a, b) -> a + b);
System.out.println(sum); // 21
1271. Какие отличия между методами map и flatMap?
В Java методы map() и flatMap() используются в контексте Stream API для обработки коллекций. Основное различие между двумя методами заключается в следующем:
- map(): этот метод применяет данную функцию к каждому элементу в потоке и возвращает новый поток, состоящий из результатов.
- flatMap(): этот метод похож на map(), но применяет функцию, которая возвращает поток для каждого элемента в исходном потоке. Затем результаты объединяются в единый поток.
Другими словами, map() преобразует каждый элемент потока в другой элемент, а flatMap() преобразует каждый элемент в поток элементов, а затем объединяет все потоки в один поток.
Вот пример использования map() для преобразования списка строк в список их длин:
List<String> strings = Arrays.asList("foo", "bar", "baz");
List<Integer> lengths = strings.stream().map(String::length).collect(Collectors.toList());
А вот пример использования flatMap() для извлечения отдельных слов из списка предложений:
List<String> sentences = Arrays.asList("hello world", "foo bar", "baz qux");
List<String> words = sentences.stream().flatMap(s -> Stream.of(s.split(" "))).distinct().collect(Collectors.toList());
В этом примере flatMap() используется для разделения каждого предложения на поток слов, которые затем объединяются в один поток. Метод Different() используется для удаления дубликатов из результирующего потока.
1272. Что такое функциональный интерфейс?
Функциональный интерфейс в Java - это интерфейс, который содержит только один абстрактный метод. Такой интерфейс может использоваться для создания лямбда-выражений, которые позволяют передавать функции в качестве параметров.
В Java 8 и новее в пакете java.util.function определены функциональные интерфейсы, такие как Predicate, Consumer, Supplier, Function, UnaryOperator и т.д. Они предназначены для использования в функциональном программировании и упрощают написание кода, который использует лямбда-выражения и методы ссылки.
Например, функциональный интерфейс Consumer определяет метод accept(T t), который принимает один параметр типа T и не возвращает значения. Это может быть использовано для выполнения каких-либо действий над объектом типа T. Пример:
Consumer<String> printer = str -> System.out.println(str);
printer.accept("Hello, world!");
Этот код создает объект printer, который принимает строку в качестве параметра и выводит ее на консоль. Затем он вызывает метод accept с аргументом "Hello, world!".
1273. Что такое лямбда?
Лямбда-выражения (lambda expressions) - это нововведение, которое появилось в Java 8. Лямбда-выражения представляют собой анонимные функции, которые могут использоваться вместо интерфейсов с одним абстрактным методом, таких как интерфейс Function или Comparable. Они позволяют более компактно и лаконично выражать функциональные конструкции, такие как обратные вызовы и потоки данных.
Например, вот как можно использовать лямбда-выражения для сортировки списка строк в порядке возрастания:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Collections.sort(names, (s1, s2) -> s1.compareTo(s2));
Здесь лямбда-выражение (s1, s2) -> s1.compareTo(s2) определяет функцию сравнения строк, которая используется для сортировки списка. Код выше эквивалентен следующему коду с использованием интерфейса Comparator:
Collections.sort(names, new Comparator<String>() {
public int compare(String s1, String s2) {
return s1.compareTo(s2);
}
});
Еще пример использования лямбда-выражения для создания объекта функционального интерфейса Runnable:
Runnable r = () -> {
System.out.println("This is a lambda expression");
};
Этот код эквивалентен следующему коду с использованием анонимного класса:
Runnable r = new Runnable() {
@Override
public void run() {
System.out.println("This is an anonymous class");
}
};
Лямбда-выражения также могут принимать параметры и возвращать значения. Например, следующее лямбда-выражение принимает два параметра типа int и возвращает их сумму:
IntBinaryOperator sum = (x, y) -> x + y;
Это эквивалентно следующему коду с использованием анонимного класса:
IntBinaryOperator sum = new IntBinaryOperator() {
@Override
public int applyAsInt(int x, int y) {
return x + y;
}
};
В целом, лямбда-выражения позволяют упростить код и улучшить его читабельность.
1274. Что такое ExecutorService, для чего он нужен и какие реализации есть?
ExecutorService — это интерфейс в пакете Java java.util.concurrent, который предоставляет способ управления пулом потоков для выполнения задач. Он обеспечивает более высокий уровень абстракции по сравнению с базовым интерфейсом Executor, позволяя лучше контролировать выполнение задач. Некоторые из преимуществ использования ExecutorService включают в себя:
- Повторное использование потоков в пуле, что может снизить накладные расходы по сравнению с созданием новых потоков для каждой задачи.
- Ограничение количества потоков, используемых для группы задач, что позволяет избежать нехватки ресурсов и повысить общую производительность системы.
- Управление рабочими очередями для управления потоком задач, что может уменьшить конкуренцию и повысить скорость реагирования.
В Java интерфейс ExecutorService имеет несколько реализаций, включая ThreadPoolExecutor, ScheduledThreadPoolExecutor и ForkJoinPool. Чтобы использовать ExecutorService, вы обычно создаете экземпляр реализации, который лучше всего соответствует вашему варианту использования, а затем отправляете ему задачи для выполнения. Например:
ExecutorService executor = Executors.newFixedThreadPool(10);
executor.submit(new RunnableTask());
Future<String> future = executor.submit(new CallableTask());
// делаем какую-то другую работу, пока выполняются задачи
String result = future.get(); // блокируется до тех пор, пока вызываемая задача не завершится
executor.shutdown(); // останавливаем службу-исполнитель, когда закончим
В этом примере мы создаем новую реализацию FixedThreadPool максимум с 10 потоками, а затем отправляем в нее RunnableTask и CallableTask. Затем мы можем продолжить другую работу, пока задачи выполняются в фоновом режиме. Мы можем использовать объект Future, возвращаемый CallableTask, для получения результата задачи после ее завершения. Наконец, мы выключаем службу-исполнитель, когда закончим с ней.
В целом ExecutorService предоставляет мощный и гибкий способ управления потоками и контроля выполнения задач в Java.
1275. Что такое SOLID?
SOLID — это акроним, образованный из заглавных букв первых пяти принципов ООП и проектирования. Принципы придумал Роберт Мартин в начале двухтысячных, а аббревиатуру позже ввел в обиход Майкл Фэзерс.
Вот что входит в принципы SOLID:
- Single Responsibility Principle (Принцип единственной ответственности).
- Open Closed Principle (Принцип открытости/закрытости).
- Liskov’s Substitution Principle (Принцип подстановки Барбары Лисков).
- Interface Segregation Principle (Принцип разделения интерфейса).
- Dependency Inversion Principle (Принцип инверсии зависимостей).
S - Принцип единственной ответственности (Single Responsibility Principle): Каждый класс должен иметь только одну причину для изменения. Это означает, что класс должен быть ответственным только за одну конкретную функцию или задачу.
O - Принцип открытости/закрытости (Open-Closed Principle): Программные сущности, такие как классы, модули и функции, должны быть открыты для расширения, но закрыты для модификации. Это означает, что код должен быть легко расширяемым без необходимости изменения уже существующего кода.
L - Принцип подстановки Лисков (Liskov Substitution Principle): Объекты в программе должны быть заменяемыми своими наследниками без изменения корректности программы. Это означает, что наследующий класс должен быть в состоянии использовать все методы и свойства базового класса без нарушения ожидаемого поведения.
I - Принцип разделения интерфейса (Interface Segregation Principle): Клиенты не должны зависеть от интерфейсов, которые они не используют. Это означает, что интерфейсы должны быть маленькими и специфичными для конкретных клиентов, чтобы избежать ненужной зависимости.
D - Принцип инверсии зависимостей (Dependency Inversion Principle): Модули верхнего уровня не должны зависеть от модулей нижнего уровня. Оба должны зависеть от абстракций. Это означает, что классы должны зависеть от абстракций, а не от конкретных реализаций.
Эти принципы помогают создавать гибкий, расширяемый и легко поддерживаемый код в объектно-ориентированном программировании.
1276. Что такое Single Responsibility Principle (Принцип единственной ответственности)?
Принцип единственной ответственности (Single responsibility principle) - это принцип объектно-ориентированного программирования, который утверждает, что класс должен иметь только одну причину для изменения, то есть должен быть ответственным только за одну функциональность. Если класс имеет несколько функциональностей, то изменение одной из них может привести к ошибкам в работе других функциональностей, что увеличивает сложность кода и усложняет его поддержку. Данный принцип является частью SOLID-принципов, которые были предложены Робертом Мартином в книге "Чистый код". Цель этих принципов заключается в том, чтобы улучшить качество кода, сделать его более читаемым, поддерживаемым и расширяемым.
Принцип единственной ответственности (SRP) - это принцип объектно-ориентированного проектирования, который гласит, что каждый объект должен иметь только одну ответственность и все его сервисы должны быть направлены исключительно на обеспечение этой ответственности.
Вот несколько примеров использования SRP в Java:
- Класс Customer может иметь только одну ответственность, например, хранить данные о клиенте и предоставлять методы для работы с этими данными. Класс должен быть разделен на две части: одна для хранения информации о клиенте, а другая для обработки ее.
public class Customer {
private int id;
private String name;
private String address;
// methods for getting and setting customer information
...
}
public class CustomerRepository {
// methods for saving, updating, and deleting customer data
...
}
- Класс Employee также может иметь только одну ответственность - чтобы содержать информацию о работнике и методы для работы с этой информацией. Этот класс также может быть разделен на две части - одна для хранения информации, а другая для обработки.
public class Employee {
private int id;
private String name;
private String address;
private String position;
// methods for getting and setting employee information
...
}
public class EmployeeRepository {
// methods for saving, updating, and deleting employee data
...
}
- Класс FileReader может иметь только одну ответственность - чтение данных из файла. Этот класс не должен использоваться для трансформации или обработки данных, он должен выполнять только одну задачу - чтение данных из файла.
public class FileReader {
public List<String> readFile(String filename) {...}
}
Все вышеупомянутые классы имеют только одну ответственность
1277. Что такое Open Closed Principle (Принцип открытости/закрытости)?
Принцип открытости/закрытости (Open/Closed Principle, OCP) - классы должны быть открыты для расширения, но закрыты для модификации. Иными словами, вы должны иметь возможность добавлять новую функциональность без изменения старого кода.
Принцип открытости/закрытости (Open Closed Principle, OCP) в объектно-ориентированном программировании означает, что сущность должна быть открыта для расширения, но закрыта для модификации. Суть заключается в том, что при добавлении новой функциональности к системе не следует изменять существующий рабочий код, вместо этого следует добавлять новый код. Это помогает сделать код более гибким и способствует улучшению его качества и поддерживаемости.
Примером может служить система меню, которая может иметь различный функционал в зависимости от роли пользователя. Вместо того, чтобы изменять код существующих классов, можно написать новый класс, который наследует интерфейс существующего класса и реализует новую функциональность. Такой подход позволяет оставлять существующий код неизменным, в то время как добавление новой функциональности выполняется без нарушения существующего функционала.
Еще одним примером может быть система отправки сообщений, которая может использоваться различными клиентами для отправки различных типов сообщений. Эта система может быть организована с использованием интерфейсов и классов, таким образом, чтобы при добавлении нового типа сообщений не требовалось изменять код уже существующих классов.
Изучение и применение принципа OCP в своих проектах может помочь сделать код более гибким и снизить уровень зависимости между различными частями системы.
Пример на Java:
// Плохой пример нарушает OCP
public class Shape {
private String type;
public void draw() {
if (type.equalsIgnoreCase("circle")) {
drawCircle();
} else if (type.equalsIgnoreCase("square")) {
drawSquare();
}
}
private void drawCircle() {
// логика рисования круга
}
private void drawSquare() {
// логика рисования квадрата
}
}
// Хороший пример OCP
public abstract class Shape {
public abstract void draw();
}
public class Circle extends Shape {
@Override
public void draw() {
// логика рисования круга
}
}
public class Square extends Shape {
@Override
public void draw() {
// логика рисования квадрата
}
}
В этом примере класс Shape нарушает принцип OCP, так как его метод draw() использует условную конструкцию для определения типа фигуры и выбора правильного метода рисования. Если мы добавим новый тип фигуры, нам нужно будет изменить класс Shape, что нарушает принцип OCP.
Классы Circle и Square следуют принципу OCP, так как они наследуются от абстрактного класса Shape и имеют свою собственную реализацию метода draw(). Если мы захотим добавить новый тип фигуры, нам просто нужно будет создать новый класс, наследуемый от Shape
1278. Что такое Liskov’s Substitution Principle (Принцип подстановки Барбары Лисков)?
Принцип подстановки Барбары Лисков (Liskov's Substitution Principle, LSP) - это принцип SOLID-архитектуры, который гласит, что объекты в программе должны быть заменяемыми их наследниками без изменения корректности программы.
Пример на Java:
class Bird {
public void fly() {
// выполнение полета
}
}
class Duck extends Bird {
public void swim() {
// выполнение плавания
}
}
class Ostrich extends Bird {
public void run() {
// выполнение бега
}
}
public class Main {
public static void main(String[] args) {
Bird duck = new Duck();
duck.fly(); // вызывает метод лета у объекта Duck
Bird ostrich = new Ostrich();
ostrich.fly(); // ошибка компиляции, т.к. страус не умеет летать
}
}
Здесь подклассы Bird - это наследники класса Bird, который содержит метод fly(). Однако, Ostrich не умеет летать, так что вызов метода fly() приводит к ошибке. Таким образом, Ostrich не является заменяемым на Bird без нарушения принципа LSP.
Пример, который следует принципу LSP:
class Bird {
public void move() {
// выполнение движения
}
}
class Duck extends Bird {
public void move() {
// выполнение полета или плавания
}
}
class Ostrich extends Bird {
public void move() {
// выполнение бега
}
}
public class Main {
public static void main(String[] args) {
Bird duck = new Duck();
duck.move(); // вызывает метод move() у объекта Duck, это может быть полет или плавание
Bird ostrich = new Ostrich();
ostrich.move(); // вызывает метод move() у объекта Ostrich, это бег
}
}
1279. Что такое Interface Segregation Principle (Принцип разделения интерфейса)?
Принцип разделения интерфейса (Interface Segregation Principle, ISP) является одним из пяти принципов SOLID для объектно-ориентированного программирования. Он заключается в том, что клиенты не должны зависеть от методов, которые они не используют.
Суть этого принципа заключается в том, что интерфейсы должны быть маленькими и специализированными, чтобы клиенты могли использовать только те методы, которые им нужны. Это позволяет избежать создания толстых интерфейсов, которые содержат много методов, из которых на практике используется только небольшая часть.
Вот пример реализации ISP на Java:
interface Vehicle {
void startEngine();
void stopEngine();
void speedUp();
void slowDown();
}
interface Car extends Vehicle {
void turnOnAC();
void turnOffAC();
}
interface Motorcycle extends Vehicle {
void putHelmetOn();
}
В данном примере интерфейс Vehicle содержит четыре метода, которые должны быть реализованы всеми транспортными средствами. Затем мы создаем два специализированных интерфейса - Car и Motorcycle - которые содержат только те методы, которые соответствуют конкретному типу транспортного средства. Это позволяет клиентам использовать только те методы, которые им нужны, вместо того, чтобы иметь доступ к всем методам в одном интерфейсе.
Например, если у нас есть объект car типа Car, то мы можем использовать методы turnOnAC() и turnOffAC() для управления кондиционером, но не можем использовать методы putHelmetOn(), которые присутствуют только в интерфейсе Motorcycle.
Другими словами, этот принцип говорит о том, что интерфейсы должны быть разделены на более мелкие, чтобы клиенты не зависели от методов, которые им не нужны. Это позволяет уменьшить зависимости между компонентами системы и улучшить ее модульность.
Еще пример, который демонстрирует принцип разделения интерфейса в Java:
public interface Printer {
void print();
}
public interface Scanner {
void scan();
}
public interface Fax {
void fax();
}
public class AllInOnePrinter implements Printer, Scanner, Fax {
public void print() {
// код для печати
}
public void scan() {
// код для сканирования
}
public void fax() {
// код для отправки факса
}
}
public class SimplePrinter implements Printer {
public void print() {
// код для печати
}
}
Здесь мы определили три интерфейса: Printer, Scanner и Fax, каждый из которых имеет один метод. После этого мы определили два класса: AllInOnePrinter, который реализует все три интерфейса, и SimplePrinter, который реализует только Printer.
Использование такой иерархии делает возможным создание различных комбинаций объектов в зависимости от требований клиента, не затрагивая код, который клиент не использует.
Теперь, если у клиента возникнет потребность только в печати документов, ему можно будет использовать класс SimplePrinter без необходимости создавать экземпляр класса AllInOnePrinter.
1280. Что такое Dependency Inversion Principle (Принцип инверсии зависимостей)?
Dependency Inversion Principle (Принцип инверсии зависимостей) - это принцип SOLID, который гласит, что абстракции не должны зависеть от деталей, а детали должны зависеть от абстракций. То есть, высокоуровневые модули не должны зависеть от низкоуровневых, а должны зависеть от абстракций, которые могут быть реализованы как в низкоуровневых, так и в высокоуровневых модулях.
Пример на Java:
public interface MessageSender {
void sendMessage(String message);
}
public class EmailMessageSender implements MessageSender {
public void sendMessage(String message) {
// sending email message
}
}
public class SmsMessageSender implements MessageSender {
public void sendMessage(String message) {
// sending SMS message
}
}
public class NotificationService {
private MessageSender messageSender;
public NotificationService(MessageSender messageSender) {
this.messageSender = messageSender;
}
public void sendNotification(String message) {
messageSender.sendMessage(message);
}
}
public class MyApp {
public static void main(String[] args) {
MessageSender messageSender = new EmailMessageSender();
NotificationService notificationService = new NotificationService(messageSender);
notificationService.sendNotification("Hello World!");
}
}
В этом примере зависимость между NotificationService и MessageSender инвертирована. Мы создаем экземпляр MessageSender вне NotificationService и передаем его через конструктор. Таким образом, NotificationService не зависит от конкретной реализации MessageSender, а зависит только от абстракции MessageSender. Это позволяет нам легко заменять конкретные реализации MessageSender, добавлять новые реализации и тестировать NotificationService независимо от реализации MessageSender.
1281. Паттерны проектирования (Шаблоны ООП)?
Паттерны проектирования это повторяемые решения, которые можно применять для решения конкретных проблем в рамках разработки программного обеспечения. Они представляют собой архитектурные решения, которые были протестированы и оптимизированы для конкретных сценариев использования.
Некоторые из наиболее широко используемых паттернов проектирования включают в себя:
-
Паттерн Одиночка (Singleton) - гарантирует, что у класса есть только один экземпляр, и обеспечивает глобальную точку доступа к этому экземпляру.
-
Паттерн Фабричный метод (Factory Method) - определяет интерфейс для создания объектов, но позволяет подклассам выбирать классы для создания.
-
Паттерн Команда (Command) - инкапсулирует запрос в виде объекта, позволяя передавать его как аргумент при вызове методов, модифицировать или отменять запросы, а также сохранять историю запросов.
-
Паттерн Стратегия (Strategy) - определяет семейство алгоритмов, инкапсулирует каждый из них и обеспечивает их взаимозаменяемость.
-
Паттерн Адаптер (Adapter) - преобразует интерфейс одного класса в интерфейс другого класса, который ожидается клиентом.
-
Паттерн Состояние (State) - это паттерн поведения объектов, который позволяет объектам изменять свое поведение в зависимости от своего внутреннего состояния.
-
Паттерн Посредник (Mediator) - является поведенческим шаблоном проектирования, который позволяет уменьшить уровень связности между объектами.
-
Паттерн Наблюдатель (Observer) - используется для уведомления одним объектом других, подписанных на него объектов об изменениях своего состояния.
-
Шаблонный метод (Template Method) - это паттерн проектирования, который определяет основу алгоритма в родительском классе, но позволяет дочерним классам переопределить отдельные шаги алгоритма без изменения его структуры. Этот паттерн обеспечивает гибкость проектирования и может использоваться для избежания дублирования кода.
Существуют другие паттерны, которые можно использовать в Java.
1282. Какие отличия между шаблонами ООП Стратегия и Состояние?
Паттерны проектирования Стратегия и Состояние (Strategy и State соответственно) имеют некоторые сходства, но в то же время есть и отличия.
Основное сходство заключается в том, что оба паттерна позволяют отделить логику поведения объекта от самого объекта и делегировать эту логику на другие объекты.
Но есть и отличия:
-
Паттерн "Стратегия" позволяет менять алгоритм поведения объекта во время выполнения программы. То есть, каждая конкретная стратегия реализует отдельный вариант алгоритма. Например, разные способы сортировки массива - с помощью quicksort, mergesort и т.д.
-
В паттерне "Стратегия" контекст имеет ссылку на стратегию, а в паттерне "Состояние" контекст имеет состояние.
-
В паттерне "Стратегия" замена стратегий может происходить динамически, а в паттерне "Состояние" замена состояний также происходит динамически, но инициируется извне.
-
Паттерн "Стратегия" часто используется для реализации различных форматов вывода, фильтрации и сортировки данных, а паттерн "Состояние" - для реализации поведения объектов в зависимости от их внутреннего состояния, например, в играх и управлении.
-
Паттерн "Состояние", в свою очередь, позволяет изменять поведение объекта при изменении его состояния. То есть, у каждого состояния объекта свое поведение. Например, в зависимости от состояния заказа (ожидание оплаты, обработка заказа и т.д.), у заказа будет разное поведение.
Другими словами, если в паттерне Стратегия меняется поведение объекта в зависимости от выбранного алгоритма, то в паттерне Состояние поведение объекта меняется в зависимости от его состояния.
Например, в паттерне Состояние можно использовать различные состояния для объекта Заказ: Новый, В обработке, Доставлен и т.д. Каждое состояние будет определять, какие методы вызываются при изменении состояния заказа и как происходит обработка заказа.
1283. Что такое группировка в БД? Примеры.
В базах данных группировка (GROUP BY) - это операция, позволяющая группировать строки таблицы по определённым критериям, например, значениям столбца или комбинации значений из нескольких столбцов.
Например, если у вас есть таблица "заказы" с полями "имя продукта", "цена", "количество", "дата", и вы хотите узнать, какой была общая цена продукта за каждый отдельный день, то вы можете использовать операцию GROUP BY по полю "дата":
SELECT DATE, SUM(price*quantity) as total_price
FROM orders
GROUP BY DATE
Также, можно использовать операции агрегации, такие как сумма, среднее, максимальное или минимальное значение в группе. Например:
SELECT category, COUNT(*) as count, AVG(price) as avg_price, MAX(price) as max_price
FROM products
GROUP BY category
В результате получим список категорий товаров с количеством товаров, средней ценой и наибольшей ценой товара в каждой категории.
Группировка данных позволяет получать сводную информацию о больших объемах данных и удобно использовать результаты дальнейшего анализа.
1284. Что такое ORM и какие есть реализации?
ORM (Object-Relational Mapping) - это технология программирования, которая позволяет представлять объекты из реляционной базы данных в виде объектов в языке программирования. Таким образом, ORM упрощает работу с базами данных объектно-ориентированных приложений.
В Java есть несколько реализаций ORM. Одна из самых популярных - это Hibernate. Hibernate предоставляет API для работы с базами данных через классы Java, что делает взаимодействие с базой данных более интуитивным и упрощает создание запросов. Другие популярные реализации ORM в Java включают Java Persistence API (JPA) и EclipseLink.
JPA - это стандарт Java для ORM, который определяет API для управления постоянными объектами, используя аннотации или XML-файлы для настройки маппинга объектов на базу данных. Он позволяет устанавливать единую систему управления постоянными объектами для разных ORM-реализаций.
ORM (Object-Relational Mapping) - это технология, которая позволяет связывать объектно-ориентированный код с реляционной базой данных. Она упрощает работу с базой данных, позволяя использовать объекты и методы для работы с данными, вместо использования SQL-запросов напрямую.
Основные реализации ORM для языка Java:
- Hibernate - самая популярная и широко используемая реализация ORM для языка Java. Пример использования:
@Entity
@Table(name = "employees")
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
@Column(name = "name")
private String name;
// getters and setters
}
- EclipseLink - еще одна популярная реализация ORM для языка Java, входящая в состав платформы Eclipse. Пример использования:
@Entity
@Table(name = "employees")
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
@Column(name = "name")
private String name;
// getters and setters
}
- OpenJPA - реализация ORM, разработанная в рамках проекта Apache. Пример использования:
@Entity
@Table(name = "employees")
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private int id;
@Column(name = "name")
private String name;
// getters and setters
}
Каждая из этих реализаций ORM обладает своими особенностями и преимуществами, поэтому выбор конкретной реализации зависит от требований к проекту.
1285. Какие уровни кэширования есть в Hibernate?
Hibernate поддерживает три уровня кэширования:
- Первичный кэш (First-Level Cache) - это внутренний кэш, который находится внутри фабрики сессий. Он кэширует объекты, полученные в рамках одной транзакции и позволяет избежать повторной загрузки объектов при повторном запросе к ним. Пример использования первичного кэша:
Session session = sessionFactory.openSession();
MyEntity entity = session.get(MyEntity.class, entityId); // первичный запрос
entity = session.get(MyEntity.class, entityId); // повторный запрос
session.close();
- Кэш второго уровня (Second-Level Cache) - это распределенный кэш, доступный нескольким сессиям в приложении. Он кэширует объекты, полученные при выполнении запросов к базе данных. Пример использования вторичного кэша:
@Entity
@Cacheable
@Table(name = "my_entity")
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class MyEntity implements Serializable {
// ...
}
- Кэш запросов (Query Cache) - это кэш, который используется для кэширования результатов выполнения запросов в базу данных. Пример использования кэша запросов:
Query query = session.createQuery("from MyEntity where name = :name");
query.setParameter("name", "John");
query.setCacheable(true);
List<MyEntity> entities = query.list();
1286. Как происходит запуск Spring Boot приложение?
Spring Boot приложение можно запустить несколькими способами. Рассмотрим два наиболее распространенных:
- Запуск через командную строку с помощью Maven:
mvn spring-boot:run
При этом Maven соберет проект, выполнит все необходимые действия и запустит приложение.
- Запуск .jar файла с помощью командной строки:
java -jar myproject.jar
При этом необходимо предварительно упаковать приложение в .jar файл.
- Если используется интегрированная среда разработки (IDE), то Spring Boot приложение можно запустить из нее. Например, в IntelliJ IDEA можно выбрать опцию "Run Application" для запуска приложения.
При запуске Spring Boot приложения, оно автоматически запускает встроенный сервер (по умолчанию это Tomcat или Jetty) и создает ApplicationContext. Если используется специальная аннотация, например, @SpringBootApplication, то автоматически будут сканироваться все классы внутри этого package и выполняться инициализация всех @Bean объектов. Если все прошло успешно, то Spring Boot приложение будет готово к работе и можно будет проверить его работоспособность.
Spring Boot приложения запускаются через класс, помеченный аннотацией @SpringBootApplication, которая включает в себя несколько других аннотаций, таких как @Configuration, @EnableAutoConfiguration, и @ComponentScan. Когда приложение запускается, Spring Boot автоматически сканирует все компоненты и автоматически конфигурирует их на основе определенных правил и конвенций.
Вот пример класса Application, который запускает Spring Boot приложение:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
В этом примере класс Application помечен аннотацией @SpringBootApplication, что обозначает, что этот класс является классом конфигурации Spring Boot приложения. В методе main делается вызов SpringApplication.run, который запускает приложение.
1287. В чем разница между юнит и интеграционными тестами?
Юнит-тесты и интеграционные тесты являются двумя разными типами тестирования в разработке программного обеспечения. Вот основные различия между ними:
Юнит-тесты:
- Юнит-тесты предназначены для проверки отдельных компонентов (юнитов) программного обеспечения, таких как функции, классы или модули.
- Они обычно пишутся разработчиками и выполняются автоматически в процессе сборки или разработки.
- Юнит-тесты изолируют компоненты от зависимостей и внешних факторов, чтобы проверить их корректность и функциональность в изоляции.
- Они помогают обнаруживать ошибки и проблемы на ранних этапах разработки и обеспечивают быструю обратную связь о работоспособности кода.
Интеграционные тесты:
- Интеграционные тесты проверяют взаимодействие между различными компонентами программного обеспечения.
- Они проверяют, как компоненты взаимодействуют друг с другом и как они работают вместе в рамках системы.
- Интеграционные тесты могут включать проверку внешних зависимостей, таких как базы данных, веб-сервисы или другие компоненты системы.
- Они помогают обнаруживать проблемы, связанные с взаимодействием компонентов и интеграцией системы в целом.
В целом, юнит-тесты и интеграционные тесты выполняют разные функции в процессе разработки программного обеспечения. Юнит-тесты проверяют отдельные компоненты в изоляции, в то время как интеграционные тесты проверяют взаимодействие между компонентами и работу системы в целом. Оба типа тестирования важны для обеспечения качества программного обеспечения и обнаружения ошибок на ранних этапах разработки.
1288. Что такое Docker?
Docker - это программное обеспечение, которое позволяет упаковывать приложения и их зависимости в контейнеры, которые могут быть запущены на любой машине с установленным Docker. Контейнеры Docker предоставляют легковесную виртуализацию, которая позволяет изолировать приложения от окружающей среды и обеспечивает удобную портативность и масштабируемость.
С помощью Docker можно создавать, запускать и распространять контейнеры с приложениями и сервисами, даже если они используют разные операционные системы или различные версии зависимостей. Docker также предоставляет механизмы для управления контейнерами, их масштабирования и обновления.
Одной из ключевых особенностей Docker является то, что контейнеры используют общую операционную систему и ядро, что делает их более легковесными и быстрыми, чем традиционные виртуальные машины. Контейнеры Docker также обеспечивают высокий уровень изоляции, благодаря чему каждый контейнер имеет свое собственное окружение со своими собственными зависимостями и файловой системой.
Docker используется для упрощения процесса развертывания приложений и сервисов в различных средах, облегчения масштабирования и обновления систем и уменьшения затрат на ресурсы.
Основные понятия Docker:
- Контейнеры: контейнеры Docker представляют собой изолированные среды, в которых запускаются приложения. Контейнеры содержат все необходимое для работы приложения, включая код, среду выполнения и зависимости.
- Образы: образы Docker являются основными строительными блоками контейнеров. Они содержат все необходимое для запуска приложения, включая операционную систему, среду выполнения и зависимости.
- Dockerfile: Dockerfile - это текстовый файл, который содержит инструкции для создания образа Docker. Он определяет, какие компоненты и зависимости должны быть установлены в образе, а также как запустить приложение в контейнере.
- Docker Hub: Docker Hub - это облачное хранилище образов Docker, где разработчики могут делиться и загружать свои образы. Docker Hub также предоставляет инструменты для автоматической сборки и развертывания образов.
- Docker Compose: Docker Compose - это инструмент для определения и управления многоконтейнерных приложений. Он позволяет определить конфигурацию приложения в файле YAML и запустить все контейнеры одной командой.
Преимущества Docker:
- Портативность: контейнеры Docker могут быть запущены на любой совместимой с Docker системе, независимо от операционной системы или аппаратного обеспечения.
- Изолированность: каждый контейнер работает в изолированной среде, что позволяет избежать конфликтов между зависимостями и обеспечивает безопасность приложений.
- Масштабируемость: Docker позволяет легко масштабировать приложения, добавляя или удаляя контейнеры в зависимости от нагрузки.
- Удобство разработки: Docker упрощает процесс разработки, позволяя разработчикам создавать и запускать приложения в контейнерах с минимальными усилиями.
- Эффективное использование ресурсов: Docker позволяет эффективно использовать ресурсы сервера, так как контейнеры используют общую операционную систему и ядро.
1289. В чем отличия между Docker и виртуальной машиной?
Docker и виртуальные машины - это два разных подхода к виртуализации и управлению окружениями приложений.
Виртуальная машина (VM) имитирует полноценный компьютер и позволяет запускать на нем операционную систему и приложения. В отличие от физического компьютера, на котором может быть только одна операционная система, на одном физическом сервере можно запустить несколько виртуальных машин с разными операционными системами.
Docker, с другой стороны, использует концепцию контейнеров для запуска приложений в изолированной среде, которая является частью операционной системы хоста. Контейнеры используют общую операционную систему, что позволяет запускать более легковесные и эффективные приложения, чем при использовании виртуальных машин. Docker-контейнеры также позволяют легко переносить приложения между разными средами, так как они содержат все необходимые зависимости и настройки внутри контейнера.
Основное отличие между Docker и виртуальными машинами заключается в том, что виртуальная машина эмулирует полную операционную систему, включая ядро и ресурсы (процессор, память, хранилище), тогда как Docker использует ресурсы и ядро операционной системы хоста, а контейнеры являются легковесными изолированными процессами, которые работают на базе общей операционной системы.
1290. Каким образом передаются переменные в методы, по ссылке или по значению?
1291. Какие отличия между примитивными и ссылочными типами данных?
В Java есть два типа данных: примитивные типы и ссылочные типы. Примитивные типы представляют основные типы данных, такие как числа и булевы значения. Они хранятся непосредственно в памяти и не имеют методов. Ссылочные типы, с другой стороны, представляют объекты, которые хранятся в куче (heap) и имеют методы. Объекты создаются с помощью оператора "new" и могут содержать значения примитивных типов, а также ссылки на другие объекты. Когда переменная ссылочного типа объявляется, она содержит ссылку на объект на куче.
Основные отличия между примитивными и ссылочными типами данных в Java:
-
Хранение: примитивные типы данных хранятся в стеке (stack), а ссылочные типы данных хранятся в куче (heap).
-
Размер: примитивные типы данных имеют фиксированный размер, а ссылочные типы данных могут иметь переменный размер.
-
Присваивание значения: примитивные типы данных присваиваются значениями, а ссылочные типы данных - ссылками на объекты.
-
Сравнение: примитивные типы данных можно сравнивать с помощью операторов сравнения, а ссылочные типы данных нужно сравнивать с использованием метода equals().
-
Использование: примитивные типы данных используются для хранения простых значений, а ссылочные типы данных используются для представления более сложных структур данных, таких как массивы, списки, карты.
1292. Как устроена память в JVM?
Виртуальная машина Java (JVM) имеет несколько различных областей памяти. Общий объем доступной памяти зависит от настроек JVM и характеристик операционной системы. Вот некоторые области памяти в JVM:
-
Heap (Куча): это область памяти, в которой хранятся объекты, созданные вашей программой. Это единственная область памяти, куда могут помещаться объекты, созданные вами, и она автоматически управляется сборщиком мусора, который удаляет объекты, которые больше не используются.
-
Stack (Стек): это область памяти, в которой хранятся локальные переменные, аргументы методов и адреса возврата. Это означает, что когда программа вызывает метод, происходит выделение новых фреймов стека, которые хранят все переменные и аргументы метода. Когда метод завершается, соответствующий фрейм стека удаляется.
-
PermGen/Metaspace: это область памяти, в которой хранятся метаданные, такие как информация о классах и методах, аннотации и т.д. В старых версиях JVM использовался PermGen, но в более новых версиях используется Metaspace.
-
Code Cache: это область памяти, в которой хранятся скомпилированные версии методов.
-
Non-Heap memory (Не куча) - здесь хранятся данные, которые обрабатываются JVM, такие как код класса, метаинформация и т.д.
Это только некоторые из областей памяти в JVM. Каждая область памяти имеет свою специфическую функцию, и понимание того, как они работают, может помочь оптимизировать производительность вашей программы.
1292. Что такое сборка мусора?
Сборка мусора (garbage collection) в Java - это процесс автоматического освобождения памяти, занятой объектами, которые больше не используются в программе.
Java использует сборку мусора для управления динамическим распределением памяти и предотвращения утечек памяти. Когда объект создается в Java, память выделяется для его хранения. Когда объект больше не доступен для использования, например, когда на него нет ссылок из активных частей программы, сборщик мусора автоматически освобождает память, занимаемую этим объектом.
Процесс сборки мусора в Java основан на алгоритмах, которые определяют, какие объекты считаются "мусором" и могут быть безопасно удалены. Основной алгоритм, используемый в Java, называется "алгоритмом пометки и освобождения" (mark-and-sweep). Он работает следующим образом:
- Сборщик мусора помечает все объекты, которые все еще доступны из активных частей программы.
- Затем он освобождает память, занимаемую объектами, которые не были помечены, так как они считаются недоступными и могут быть безопасно удалены.
- После освобождения памяти сборщик мусора компактизирует оставшуюся память, чтобы создать непрерывные блоки свободной памяти для будущего выделения объектов.
Сборка мусора в Java осуществляется автоматически и не требует явного управления со стороны программиста. Однако, программист может влиять на процесс сборки мусора, используя различные параметры и настройки сборщика мусора, чтобы оптимизировать производительность и использование памяти в своей программе.
1293. Многопоточность, параллелизм и асинхронность.
Многопоточность, параллелизм и асинхронность - это важные концепции в Java, связанные с одновременным выполнением кода и управлением потоками.
Многопоточность (multithreading) в Java позволяет выполнять несколько потоков кода параллельно. Потоки - это независимые последовательности инструкций, которые могут выполняться одновременно. Многопоточность полезна, когда нужно выполнять несколько задач одновременно или когда нужно отвечать на события в реальном времени.
Параллелизм (parallelism) в Java относится к выполнению нескольких задач одновременно на нескольких физических или виртуальных процессорах. Параллелизм может улучшить производительность и ускорить выполнение программы, особенно для задач, которые могут быть разделены на независимые части.
Асинхронность (asynchrony) в Java относится к выполнению задачи без блокировки основного потока выполнения. Вместо ожидания завершения задачи, основной поток может продолжать работу и получать уведомления о завершении задачи в будущем. Асинхронность полезна для обработки долгих операций, таких как сетевые запросы или операции ввода-вывода, без блокировки пользовательского интерфейса или других задач.
Java предоставляет множество классов и методов для работы с многопоточностью, параллелизмом и асинхронностью, таких как классы Thread, Executor, Future и другие. Эти инструменты позволяют создавать и управлять потоками, запускать задачи параллельно и асинхронно, а также синхронизировать доступ к общим ресурсам для предотвращения проблем, таких как состояние гонки и блокировки.
1294. Многопоточность, параллелизм и асинхронность. Kакие между ними отличия?
Между многопоточностью, параллелизмом и асинхронностью есть следующие отличия:
Многопоточность (multithreading) относится к выполнению нескольких потоков кода в пределах одного процесса. Каждый поток имеет свою собственную последовательность инструкций и может выполняться параллельно с другими потоками. Многопоточность позволяет выполнять несколько задач одновременно и может быть полезна для улучшения производительности и отзывчивости программы.
Параллелизм (parallelism) относится к выполнению нескольких задач одновременно на нескольких физических или виртуальных процессорах. Параллелизм может быть достигнут с помощью многопоточности, но не обязательно. Он позволяет ускорить выполнение программы, разделяя задачи на независимые части, которые могут выполняться параллельно.
Асинхронность (asynchrony) относится к выполнению задачи без блокировки основного потока выполнения. Вместо ожидания завершения задачи, основной поток может продолжать работу и получать уведомления о завершении задачи в будущем. Асинхронность полезна для обработки долгих операций, таких как сетевые запросы или операции ввода-вывода, без блокировки пользовательского интерфейса или других задач.
Таким образом, многопоточность относится к выполнению нескольких потоков кода, параллелизм - к выполнению нескольких задач одновременно, а асинхронность - к выполнению задач без блокировки основного потока. Важно отметить, что многопоточность и параллелизм могут быть использованы вместе для достижения более эффективного использования ресурсов и улучшения производительности программы.
1295. Разница между виртуальными и реальными потоками.
В Java виртуальные потоки (также известные как потоки планирования или потоки пользовательского уровня) являются абстракцией, предоставляемой виртуальной машиной Java (JVM) для управления выполнением задач. Они не привязаны к физическим потокам операционной системы и управляются JVM.
Реальные потоки (также известные как потоки ядра или потоки системного уровня) являются низкоуровневыми сущностями операционной системы, которые непосредственно связаны с физическими потоками процессора. Они управляются операционной системой и обеспечивают параллельное выполнение задач.
Основная разница между виртуальными и реальными потоками заключается в уровне абстракции и управлении. Виртуальные потоки управляются JVM и могут быть планированы и выполнены независимо от физических потоков процессора. Они обеспечивают более высокий уровень абстракции и удобство программирования, но могут иметь некоторые ограничения в производительности.
Реальные потоки, с другой стороны, прямо связаны с физическими потоками процессора и управляются операционной системой. Они обеспечивают более низкий уровень абстракции и могут быть более эффективными в использовании ресурсов процессора, но требуют более сложного управления и могут быть менее удобными в использовании.
В целом, виртуальные потоки обеспечивают более высокий уровень абстракции и удобство программирования, в то время как реальные потоки обеспечивают более низкий уровень абстракции и более прямой доступ к ресурсам процессора. Выбор между ними зависит от конкретных требований и ограничений вашего приложения.
1296. Future и CompletableFuture. Их назначение и отличия.
Future и CompletableFuture - это классы в языке Java, которые используются для работы с асинхронными операциями и обещаниями (promises).
Future - это интерфейс, введенный в Java 5, который представляет результат асинхронной операции. Он позволяет получить результат операции в будущем, когда он станет доступным. Future предоставляет методы для проверки статуса операции, ожидания завершения операции и получения результата.
Однако Future имеет некоторые ограничения. Например, он не предоставляет возможности для комбинирования и композиции нескольких асинхронных операций. Кроме того, он не предоставляет способа управления завершением операции или обработки исключений.
CompletableFuture - это расширение Future, введенное в Java 8, которое предоставляет более мощные возможности для работы с асинхронными операциями. CompletableFuture позволяет комбинировать и композировать несколько асинхронных операций, управлять их завершением и обрабатывать исключения.
CompletableFuture предоставляет множество методов для выполнения различных операций над результатом асинхронной операции. Например, вы можете применить функцию к результату операции, скомбинировать результаты нескольких операций, обработать исключения и т. д. Кроме того, CompletableFuture предоставляет методы для управления потоком выполнения операций, таких как thenApply, thenCompose, thenCombine и другие.
Основное отличие между Future и CompletableFuture заключается в их возможностях и гибкости. CompletableFuture предоставляет более высокий уровень абстракции и более широкий набор методов для работы с асинхронными операциями. Он позволяет более гибко управлять и комбинировать операции, а также обрабатывать исключения.
В общем, если вам нужно выполнить простую асинхронную операцию и получить ее результат в будущем, то Future может быть достаточным. Однако, если вам нужно выполнить более сложные операции, комбинировать результаты нескольких операций или обрабатывать исключения, то CompletableFuture предоставляет более мощные возможности.
1297. Коллекция HashMap. Устройство и особенности работы.
Внутренне устройство HashMap основано на массиве объектов типа Node. Каждый элемент массива представляет собой связный список (цепочку) элементов, которые имеют одинаковый хэш-код. Каждый элемент списка представлен объектом типа Node, который содержит ключ, значение и ссылку на следующий элемент списка.
Особенности работы HashMap
- Хэш-коды ключей используются для определения индекса в массиве, где будет храниться элемент.
- Если несколько ключей имеют одинаковый хэш-код, они будут храниться в одной цепочке.
- При добавлении элемента в HashMap, сначала вычисляется хэш-код ключа. Затем определяется индекс в массиве, где будет храниться элемент. Если в этом месте уже есть элементы, то новый элемент добавляется в начало цепочки.
- При поиске элемента по ключу, сначала вычисляется хэш-код ключа. Затем происходит поиск элемента в соответствующей цепочке.
- Если в HashMap содержится большое количество элементов, возможно возникновение коллизий, когда несколько ключей имеют одинаковый хэш-код. В этом случае производительность может снизиться, так как придется проходить по всей цепочке для поиска элемента.
- При удалении элемента из HashMap, сначала вычисляется хэш-код ключа. Затем происходит поиск элемента в соответствующей цепочке и удаление его из списка. Пример использования HashMap
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
// Создание объекта HashMap
HashMap<String, Integer> hashMap = new HashMap<>();
// Добавление элементов в HashMap
hashMap.put("Ключ 1", 1);
hashMap.put("Ключ 2", 2);
hashMap.put("Ключ 3", 3);
// Получение значения по ключу
int value = hashMap.get("Ключ 2");
System.out.println("Значение: " + value);
// Удаление элемента по ключу
hashMap.remove("Ключ 1");
// Проверка наличия элемента по ключу
boolean containsKey = hashMap.containsKey("Ключ 3");
System.out.println("Наличие элемента: " + containsKey);
// Проверка наличия значения
boolean containsValue = hashMap.containsValue(2);
System.out.println("Наличие значения: " + containsValue);
}
}
В данном примере создается объект HashMap, добавляются элементы с помощью метода put(), получается значение по ключу с помощью метода get(), удаляется элемент по ключу с помощью метода remove(), проверяется наличие элемента по ключу с помощью метода containsKey() и наличие значения с помощью метода containsValue().
Коллекция HashMap предоставляет эффективные операции добавления, поиска и удаления элементов. Она является одной из наиболее часто используемых коллекций в Java и широко применяется в различных приложениях.
1298. ли она потокобезопасной?
1299. Что такое индексы в базах данных?
Индексы в базах данных - это структуры данных, которые ускоряют поиск и сортировку данных в таблицах. Они создаются на одном или нескольких столбцах таблицы и позволяют эффективно находить строки, соответствующие определенным критериям.
Зачем нужны индексы? Индексы позволяют базе данных быстро находить нужные данные, ускоряя выполнение запросов. Без индексов, база данных должна была бы просматривать каждую строку таблицы для поиска нужных данных, что может быть очень медленным при больших объемах данных.
Как работают индексы? Индексы создаются на определенных столбцах таблицы и содержат отсортированные значения этих столбцов, а также ссылки на соответствующие строки в таблице. Когда выполняется запрос, содержащий условие поиска или сортировки по индексированному столбцу, база данных может использовать индекс для быстрого нахождения нужных строк.
Преимущества использования индексов:
- Ускорение выполнения запросов, особенно при работе с большими объемами данных.
- Улучшение производительности при поиске и сортировке данных.
- Снижение нагрузки на сервер базы данных.
Недостатки использования индексов:
- Индексы занимают дополнительное место на диске.
- При изменении данных в таблице (вставка, обновление, удаление) индексы также должны быть обновлены, что может замедлить операции записи.
- Создание и поддержка индексов требует дополнительных ресурсов и времени.
Типы индексов:
- B-дерево (B-tree): наиболее распространенный тип индекса, который поддерживает эффективный поиск и сортировку данных.
- Хеш-индекс (Hash index): используется для быстрого поиска по хеш-значению столбца.
- GiST (Generalized Search Tree): используется для индексации сложных типов данных, таких как геометрические объекты.
- GIN (Generalized Inverted Index): используется для индексации массивов и полнотекстового поиска.
- SP-GiST (Space-Partitioned Generalized Search Tree): используется для индексации пространственных данных.
Заключение: Индексы являются важным инструментом для оптимизации работы с базами данных. Они позволяют ускорить выполнение запросов и повысить производительность системы. Однако, необходимо тщательно выбирать и создавать индексы, чтобы избежать излишней нагрузки на систему и избыточного использования дискового пространства.
1300. Особенности удаления данных, связанных через FOREIGN KEY.
Особенности удаления данных, связанных через FOREIGN KEY Когда данные связаны через FOREIGN KEY, удаление этих данных может иметь различные последствия в зависимости от настроек FOREIGN KEY CONSTRAINT.
Вот некоторые особенности удаления данных, связанных через FOREIGN KEY:
CASCADE: Если установлено действие CASCADE, то при удалении родительской записи все связанные дочерние записи также будут удалены автоматически. Например, если у вас есть таблицы "Заказы" и "Позиции заказов", и между ними есть FOREIGN KEY CONSTRAINT, установленный с действием CASCADE, то при удалении заказа будут удалены все связанные позиции заказов.
SET NULL: Если установлено действие SET NULL, то при удалении родительской записи значение FOREIGN KEY в дочерней записи будет установлено в NULL. Например, если у вас есть таблицы "Пользователи" и "Заказы", и между ними есть FOREIGN KEY CONSTRAINT, установленный с действием SET NULL, то при удалении пользователя FOREIGN KEY в связанных заказах будет установлен в NULL.
RESTRICT: Если установлено действие RESTRICT, то удаление родительской записи будет запрещено, если существуют связанные дочерние записи. Например, если у вас есть таблицы "Компании" и "Пользователи", и между ними есть FOREIGN KEY CONSTRAINT, установленный с действием RESTRICT, то удаление компании, если у нее есть связанные пользователи, будет запрещено.
NO ACTION: Если установлено действие NO ACTION, то удаление родительской записи будет запрещено, если существуют связанные дочерние записи. Это действие аналогично RESTRICT.
Когда вы создаете таблицу с FOREIGN KEY CONSTRAINT, вы можете указать желаемое действие при удалении или обновлении связанных данных. Важно выбрать правильное действие, чтобы избежать нежелательных последствий при удалении данных.
1301. Что такое Result Set в JDBC? Особенности его конфигурации.
Result Set в JDBC представляет собой объект, который содержит набор данных, полученных из базы данных после выполнения SQL-запроса. Result Set предоставляет методы для доступа и манипуляции с этими данными.
Особенности конфигурации Result Set в JDBC включают:
Тип прокрутки (Scrollability): Result Set может быть настроен на прокрутку вперед, назад или в обоих направлениях. Это позволяет перемещаться по набору данных вперед и назад, а также выполнять операции, такие как перемещение к определенной строке или обновление данных.
Тип изменяемости (Updatability): Result Set может быть настроен на возможность обновления данных в базе данных. Это позволяет изменять значения в Result Set и сохранять изменения обратно в базу данных.
Тип чувствительности к изменениям (Sensitivity): Result Set может быть настроен на отслеживание изменений в базе данных. Это позволяет обновлять Result Set автоматически, если другой процесс или поток изменяет данные в базе данных.
Тип конкурентности (Concurrency): Result Set может быть настроен на обработку конкурентных доступов к данным. Это позволяет нескольким процессам или потокам работать с Result Set одновременно, обеспечивая согласованность данных.
Для настройки Result Set в JDBC можно использовать методы createStatement() или prepareStatement() в объекте Connection. Затем можно использовать методы executeQuery() или executeUpdate() для выполнения SQL-запроса и получения Result Set.
Пример кода для создания и использования Result Set в JDBC:
// Подключение к базе данных
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");
// Создание Statement
Statement statement = connection.createStatement();
// Выполнение SQL-запроса и получение Result Set
ResultSet resultSet = statement.executeQuery("SELECT * FROM mytable");
// Итерация по Result Set и получение данных
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
// Обработка данных
}
// Закрытие Result Set, Statement и Connection
resultSet.close();
statement.close();
connection.close();
Это основы работы с Result Set в JDBC. Result Set предоставляет мощные возможности для работы с данными из базы данных и может быть настроен для соответствия требованиям вашего приложения.
1302. Что такое хранимые процедуры и какой способ их вызова через JDBC?
Хранимые процедуры - это предварительно скомпилированные блоки кода, которые хранятся в базе данных и могут быть вызваны из приложения. Они позволяют выполнять сложные операции в базе данных, такие как вставка, обновление или выборка данных, а также выполнять бизнес-логику на стороне сервера базы данных.
JDBC (Java Database Connectivity) - это API для взаимодействия с базами данных из языка Java. JDBC предоставляет набор классов и методов для выполнения SQL-запросов и обработки результатов.
Чтобы вызвать хранимую процедуру через JDBC, необходимо выполнить следующие шаги:
Установить соединение с базой данных с помощью класса java.sql.Connection. Создать объект java.sql.CallableStatement, который представляет вызов хранимой процедуры. Установить параметры хранимой процедуры с помощью методов setXXX() класса CallableStatement, где XXX - тип параметра (например, setString() для строкового параметра). Выполнить хранимую процедуру с помощью метода execute() или executeUpdate() класса CallableStatement. Получить результаты выполнения хранимой процедуры, если они есть, с помощью методов getXXX() класса CallableStatement, где XXX - тип результата (например, getString() для получения строки результата). Вот пример кода на Java, демонстрирующий вызов хранимой процедуры через JDBC:
import java.sql.*;
public class JdbcExample {
public static void main(String[] args) {
try {
// Установка соединения с базой данных
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydatabase", "username", "password");
// Создание объекта CallableStatement для вызова хранимой процедуры
CallableStatement callableStatement = connection.prepareCall("{call my_stored_procedure(?, ?)}");
// Установка параметров хранимой процедуры
callableStatement.setString(1, "param1");
callableStatement.setInt(2, 123);
// Выполнение хранимой процедуры
callableStatement.execute();
// Получение результата выполнения хранимой процедуры
ResultSet resultSet = callableStatement.getResultSet();
while (resultSet.next()) {
String result = resultSet.getString("column_name");
System.out.println(result);
}
// Закрытие ресурсов
resultSet.close();
callableStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
В этом примере мы устанавливаем соединение с базой данных, создаем объект CallableStatement для вызова хранимой процедуры, устанавливаем параметры хранимой процедуры, выполняем ее и получаем результаты выполнения. Затем мы закрываем ресурсы, такие как ResultSet, CallableStatement и соединение с базой данных.
Обратите внимание, что код приведен в качестве примера и может потребоваться настройка в зависимости от вашей конкретной базы данных и хранимой процедуры.
1303. Что такое SessionFactory в Hibernate?
SessionFactory в Hibernate представляет собой центральный компонент, который используется для создания сеансов (Session) работы с базой данных. Он является фабрикой для создания экземпляров сеансов и обеспечивает управление жизненным циклом сеансов.
SessionFactory создается один раз при запуске приложения и обычно используется в качестве глобального ресурса. Он содержит настройки и метаданные, необходимые для работы с базой данных, такие как информация о подключении, маппинг объектов на таблицы и другие настройки.
Когда приложение нуждается в выполнении операций с базой данных, оно запрашивает у SessionFactory новый сеанс (Session). Сеанс представляет собой логическое соединение с базой данных и предоставляет API для выполнения операций CRUD (создание, чтение, обновление, удаление) и других операций, связанных с базой данных.
SessionFactory обеспечивает управление жизненным циклом сеансов, включая открытие и закрытие сеансов, управление кэшированием и транзакциями. Он также обеспечивает механизмы для настройки и настройки Hibernate, такие как загрузка конфигурации из файла hibernate.cfg.xml.
Использование SessionFactory позволяет эффективно управлять ресурсами базы данных и обеспечивает единообразный доступ к базе данных для всего приложения. Он является ключевым компонентом в архитектуре Hibernate и позволяет разработчикам легко и эффективно работать с базой данных с использованием объектно-реляционного отображения (ORM).
1304. Управление уровнями изоляции транзакций в Hibernate.
Hibernate предоставляет возможность управлять уровнями изоляции транзакций с помощью атрибута isolation в конфигурации соединения с базой данных. Уровень изоляции определяет, какие виды блокировок и чтения могут быть выполнены в рамках транзакции.
В Hibernate поддерживаются следующие уровни изоляции:
READ_UNCOMMITTED: Этот уровень изоляции позволяет транзакции видеть незафиксированные изменения, внесенные другими транзакциями. Это самый низкий уровень изоляции и может привести к проблемам согласованности данных.
READ_COMMITTED: Этот уровень изоляции гарантирует, что транзакция видит только фиксированные изменения, внесенные другими транзакциями. Однако, если другая транзакция изменяет данные во время выполнения текущей транзакции, то эти изменения не будут видны.
REPEATABLE_READ: Этот уровень изоляции гарантирует, что транзакция видит только фиксированные изменения, внесенные другими транзакциями, и предотвращает чтение незафиксированных изменений. Это обеспечивает более высокую степень изоляции, чем READ_COMMITTED.
SERIALIZABLE: Этот уровень изоляции гарантирует полную изоляцию транзакций, предотвращая конфликты параллельного доступа к данным. Он гарантирует, что транзакции выполняются последовательно, как если бы они были выполнены одна за другой.
Уровень изоляции транзакций в Hibernate можно установить с помощью атрибута hibernate.connection.isolation в файле конфигурации Hibernate (hibernate.cfg.xml). Например, чтобы установить уровень изоляции READ_COMMITTED, можно добавить следующую строку в файл конфигурации:
<property name="hibernate.connection.isolation">2</property>
Здесь значение 2 соответствует уровню изоляции READ_COMMITTED.
1305. Как работает аутентификация и авторизация в Spring Security с использованием JWT токена?
Aутентификация и авторизация в Spring Security с использованием JWT токена работают следующим образом:
Аутентификация:
- Клиент отправляет запрос на аутентификацию, предоставляя свои учетные данные (например, логин и пароль) на сервер.
- Сервер проверяет предоставленные учетные данные и, если они верны, создает JWT токен.
- JWT токен содержит информацию о клиенте (например, идентификатор пользователя, роли и другие данные), которая может быть закодирована и подписана с использованием секретного ключа сервера.
- Сервер возвращает JWT токен клиенту в ответе на запрос аутентификации.
Авторизация:
- Клиент включает полученный JWT токен в заголовок каждого последующего запроса к серверу.
- Сервер проверяет подлинность JWT токена, расшифровывает его и проверяет подпись с использованием секретного ключа.
- Если JWT токен действителен, сервер извлекает информацию о клиенте из токена и выполняет проверку разрешений для запрашиваемого ресурса или действия.
- Если клиент имеет необходимые разрешения, сервер выполняет запрошенное действие и возвращает результат клиенту. Если клиент не имеет необходимых разрешений, сервер возвращает ошибку доступа.
JWT токен позволяет серверу аутентифицировать клиента и авторизовать его для доступа к определенным ресурсам или действиям. Токен содержит информацию о клиенте, которая может быть использована для принятия решений об авторизации без необходимости обращения к базе данных или другим источникам данных.
В Spring Security существуют различные способы настройки аутентификации и авторизации с использованием JWT токена. Это может включать настройку фильтров аутентификации и авторизации, настройку провайдеров аутентификации, настройку конфигурации безопасности и другие аспекты. Конкретная настройка зависит от требований вашего приложения и может быть выполнена с использованием аннотаций или конфигурационных файлов.
Примечание: Для более подробной информации и примеров кода рекомендуется обратиться к официальной документации Spring Security и примерам реализации аутентификации и авторизации с использованием JWT токена.
1306. Виды тестирования в Java.
В Java могут проводиться различные типы тестирования, включая модульное тестирование, функциональное тестирование, тестирование производительности и интеграционное тестирование.
-
Модульное тестирование (unit testing) - это тестирование отдельных модулей или компонентов программного обеспечения для проверки, соответствует ли каждый модуль требованиям и работает ли он правильно в изоляции от других модулей.
-
Функциональное тестирование (functional testing) - это тестирование, которое проверяет, соответствует ли программное обеспечение функциональным требованиям и способно ли оно выполнять заданные функции.
-
Тестирование производительности (performance testing) - это тестирование, которое оценивает производительность программного обеспечения в различных условиях нагрузки.
-
Интеграционное тестирование (integration testing): Интеграционное тестирование в Java выполняется для проверки взаимодействия между различными модулями или компонентами программы. Оно помогает обнаружить проблемы, которые могут возникнуть при интеграции различных частей программы. Для интеграционного тестирования в Java также можно использовать фреймворк JUnit.
-
Системное тестирование (system testing): Системное тестирование в Java выполняется для проверки всей системы в целом. Оно включает тестирование функциональности, производительности, надежности и других аспектов программы. Для системного тестирования в Java можно использовать различные инструменты и фреймворки, такие как TestNG или JUnit.
-
Автоматизированное тестирование (automated testing): Автоматизированное тестирование в Java включает использование специальных инструментов и фреймворков для автоматизации процесса тестирования. Это позволяет повысить эффективность и скорость тестирования, а также обеспечить повторяемость результатов. Для автоматизированного тестирования в Java можно использовать фреймворки, такие как Selenium или TestNG.
Одним из инструментов для тестирования Java-приложений является фреймворк JUnit, который позволяет проводить модульное тестирование. Для тестирования REST API в Java можно использовать библиотеку REST Assured, которая обеспечивает удобный интерфейс для написания тестов на Java.
1307. Что такое юнит-тестирование.
Юнит-тестирование (англ. unit testing) — техника тестирования программного обеспечения, при которой отдельные блоки кода (юниты) тестируются отдельно от всей программы. Целью таких тестов является проверка корректности работы отдельных блоков кода, а не всего приложения в целом. Юнит-тесты позволяют выявлять ошибки и дефекты на ранних этапах разработки, что упрощает их исправление и снижает вероятность появления серьезных проблем в конечном продукте.
Юнит-тесты пишутся программистами для проверки отдельных функций, методов или классов. Они выполняются автоматически и могут быть запущены в любое время для проверки работоспособности кода. Юнит-тесты обычно проверяют различные сценарии использования модуля и проверяют, что он возвращает ожидаемые результаты.
Для написания юнит-тестов в Java часто используются фреймворки, такие как JUnit или TestNG. Эти фреймворки предоставляют удобные средства для создания и запуска тестов, а также проверки ожидаемых результатов.
Юнит-тестирование является важной практикой разработки программного обеспечения, так как оно помогает выявить и исправить ошибки на ранних стадиях разработки. Юнит-тесты также способствуют повышению надежности и поддерживаемости кода, так как они позволяют быстро обнаруживать проблемы при внесении изменений в код.
1308. Ключевое слово final, назначение и варианты использования?
Ключевое слово final в Java используется для указания, что значение поля (переменной) или метода не может быть изменено после инициализации. Оно может применяться к полям класса, локальным переменным, параметрам методов и классам.
В частности, применение final к полям класса делает их константами - они могут быть инициализированы только один раз при создании объекта и не могут быть изменены после этого. Кроме того, объявление метода как final запрещает его переопределение в подклассах.
Вот некоторые примеры использования ключевого слова final в Java:
public class MyClass {
final int MAX_VALUE = 100; // константа поля класса
final double PI = 3.14;
final String NAME; // константа поля класса, инициализируется в конструкторе
final int[] ARRAY = {1, 2, 3}; // константа ссылки на массив
public MyClass(String name) {
NAME = name;
}
public final void myMethod() {
// код метода
}
}
public final class MySubClass extends MyClass {
// MySubClass не может быть подклассом другого класса, потому что он объявлен как final
}
1309. Значения переменных по умолчанию - что это и как работает?
В Java значения переменных по умолчанию зависят от их типов. Для типов данных в Java существует набор значений по умолчанию, которые присваиваются переменным при их создании:
-
0для числовых типов данных: byte, short, int, long, float, double -
'\0'для типа char -
falseдля типа boolean -
nullдля ссылочных типов данных (объектов)
Это означает, что если переменная не была инициализирована явным образом, то ей будет присвоено значение по умолчанию в соответствии с её типом данных.
Например, если мы объявим переменную int a;, то ей будет присвоено значение по умолчанию 0. А если мы объявим переменную String str;, то ей будет присвоено значение по умолчанию null. При попытке обратиться к неинициализированной переменной в Java произойдет ошибка компиляции.
Если требуется задать переменной другое значение по умолчанию, то можно использовать оператор присваивания при ее создании. Например, int a = 10; задаст переменной a начальное значение 10.
1310. Иерархия Collections API
Java Collections Framework (Фреймворк коллекций Java) предоставляет классы и интерфейсы для работы с коллекциями объектов в Java. Он предоставляет удобные и эффективные способы хранения и обработки данных.
Иерархия Java Collections Framework Java Collections Framework включает в себя следующие основные интерфейсы и классы:
Интерфейс Collection: Это корневой интерфейс иерархии коллекций. Он определяет основные операции, которые можно выполнять с коллекциями, такие как добавление, удаление и проверка наличия элементов.
Интерфейс List: Это подинтерфейс Collection, который представляет упорядоченную коллекцию элементов, где элементы могут дублироваться. Он предоставляет методы для доступа к элементам по индексу и выполнения операций, связанных с порядком элементов.
Интерфейс Set: Это подинтерфейс Collection, который представляет неупорядоченную коллекцию уникальных элементов. Он не допускает наличие дублирующихся элементов и предоставляет методы для проверки наличия элементов и выполнения операций над множествами, таких как объединение, пересечение и разность.
Интерфейс Queue: Это подинтерфейс Collection, который представляет коллекцию элементов в определенном порядке. Он предоставляет методы для добавления элементов в конец очереди и удаления элементов из начала очереди.
Интерфейс Map: Это интерфейс, который представляет отображение ключ-значение. Он предоставляет методы для добавления, удаления и получения элементов по ключу.
Классы ArrayList и LinkedList: Это реализации интерфейса List. ArrayList представляет динамический массив, а LinkedList представляет двусвязный список. Они оба предоставляют эффективные операции доступа к элементам по индексу.
Класс HashSet и TreeSet: Это реализации интерфейса Set. HashSet представляет неупорядоченное множество элементов, а TreeSet представляет отсортированное множество элементов.
Класс HashMap и TreeMap: Это реализации интерфейса Map. HashMap представляет неупорядоченное отображение ключ-значение, а TreeMap представляет отсортированное отображение ключ-значение.
1311. Иерархия методов коллекций java
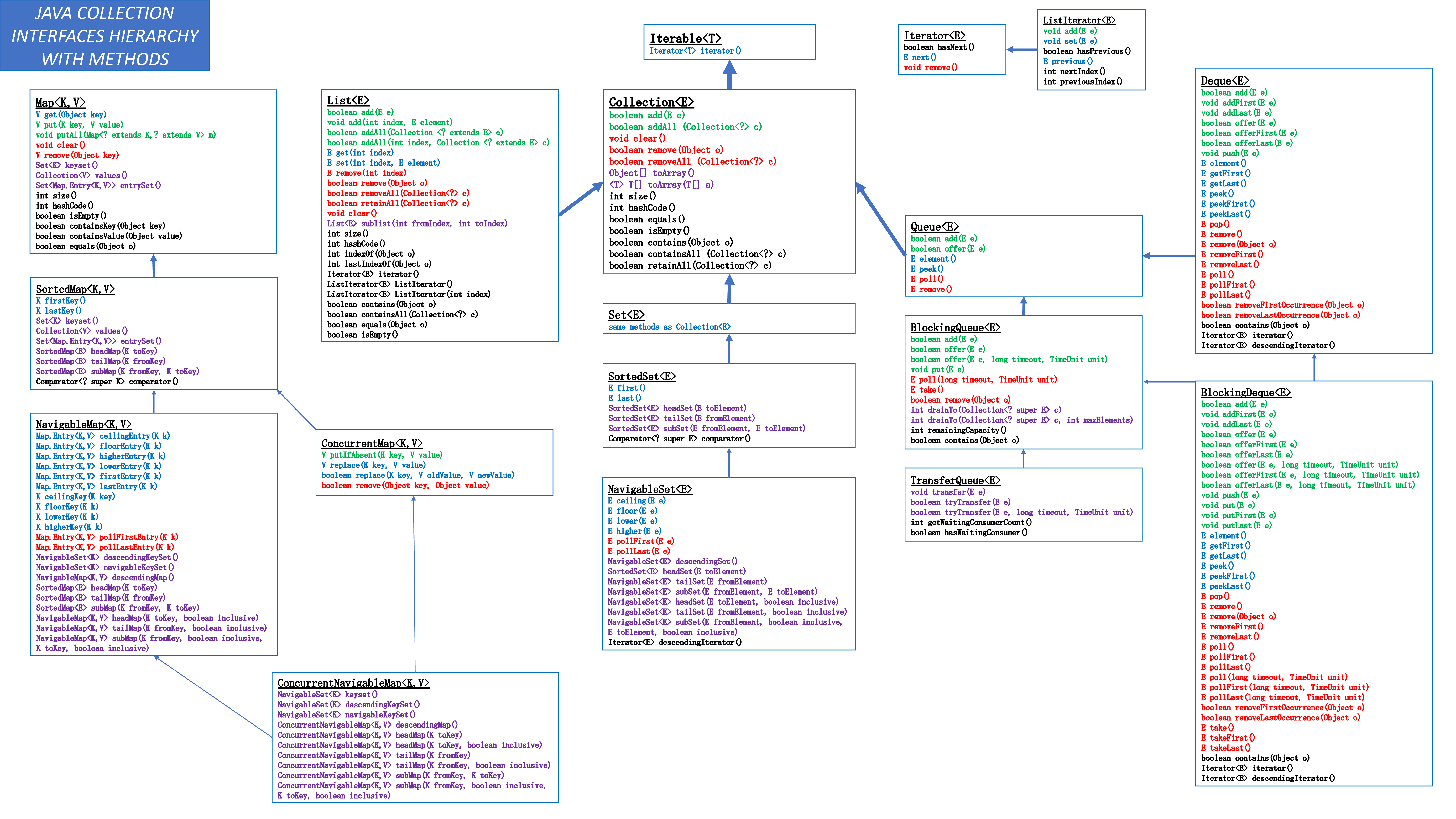
ссылка на картинку большего размера
В Java существует иерархия классов и интерфейсов, связанных с коллекциями. Они предоставляют различные методы для работы с коллекциями объектов. Вот основные классы и интерфейсы в иерархии коллекций Java:
Collection (интерфейс): Это корневой интерфейс в иерархии коллекций. Он определяет основные методы для работы с коллекциями, такие как добавление, удаление и проверка наличия элементов. Некоторые из методов, определенных в интерфейсе Collection, включают add, remove, contains, isEmpty и другие.
List (интерфейс): List - это интерфейс, расширяющий интерфейс Collection. Он представляет упорядоченную коллекцию элементов, где элементы могут дублироваться. Некоторые из методов, определенных в интерфейсе List, включают get, set, add, remove, indexOf и другие.
Set (интерфейс): Set - это интерфейс, также расширяющий интерфейс Collection. Он представляет коллекцию элементов, где каждый элемент может быть уникальным. Некоторые из методов, определенных в интерфейсе Set, включают add, remove, contains, isEmpty и другие.
Queue (интерфейс): Queue - это интерфейс, расширяющий интерфейс Collection. Он представляет коллекцию элементов, где элементы добавляются в конец и удаляются из начала. Некоторые из методов, определенных в интерфейсе Queue, включают add, remove, peek, isEmpty и другие.
Map (интерфейс): Map - это интерфейс, представляющий отображение ключей на значения. Он не наследуется от интерфейса Collection, но является важной частью иерархии коллекций Java. Некоторые из методов, определенных в интерфейсе Map, включают put, get, remove, containsKey и другие.
Это основные классы и интерфейсы в иерархии коллекций Java. Они предоставляют различные методы для работы с коллекциями объектов и позволяют эффективно управлять данными в вашей программе.
1312. Класс TreeMap - какая структура данных и алгоритмические сложности базовых операций
Kласс TreeMap в Java представляет собой реализацию интерфейса Map, который основан на структуре данных "красно-черное дерево". Он предоставляет отсортированное отображение ключей в виде пар "ключ-значение". Ключи в TreeMap хранятся в отсортированном порядке.
Структура данных и алгоритмические сложности базовых операций Структура данных TreeMap основана на красно-черном дереве, которое является сбалансированным двоичным деревом поиска. Это означает, что высота дерева ограничена логарифмически относительно количества элементов в дереве, что обеспечивает эффективность операций поиска, вставки и удаления.
Вот алгоритмические сложности базовых операций в TreeMap:
- Вставка (put): O(log n)
- Удаление (remove): O(log n)
- Поиск (get): O(log n)
- Получение наименьшего ключа (firstKey): O(log n)
- Получение наибольшего ключа (lastKey): O(log n)
- Получение предыдущего ключа (lowerKey): O(log n)
- Получение следующего ключа (higherKey): O(log n)
- Получение подотображения по ключам (subMap): O(log n + m), где m - размер подотображения Таким образом, TreeMap обеспечивает эффективный доступ к данным и поддерживает операции с временной сложностью O(log n), где n - количество элементов в дереве.
1313. Иерархия исключения в Java, их типы и способы их обработки.
В Java иерархия исключений представлена классом Throwable, который имеет два подкласса: Error и Exception.
Класс Error представляет ошибки, связанные с внутренними проблемами системы, которые обычно не могут быть исправлены, например, OutOfMemoryError.
Класс Exception представляет ошибки, которые обычно могут быть обработаны программой, например, IOException. Класс Exception имеет много подклассов, каждый из которых представляет конкретную ошибку, например, NullPointerException, IllegalArgumentException, ArrayIndexOutOfBoundsException и т.д.
Error обозначает серьезные проблемы, которые происходят во время выполнения программы и которые не могут быть восстановлены. Обработка Error не предполагается.
Exception обозначает проблемы, которые могут быть обработаны в коде. Они делятся на две категории: Checked Exceptions и Unchecked Exceptions. Checked Exceptions вынуждают производить обработку в коде, а Unchecked Exceptions не вынуждают обязательно обрабатываться.
RuntimeException - это небольшая подкатегория Unchecked Exceptions, которая указывает на ошибки, которые могут произойти в результате неправильной работы кода, к примеру, деление на ноль.
Для обработки исключений в Java используют блоки try, catch и finally. Блок try содержит код, который может породить исключение, а блок catch содержит код обработки исключения. Блок finally выполняется в любом случае, независимо от того, было ли исключение порождено или нет. Можно также использовать конструкцию throw для явного выбрасывания исключения в определенных ситуациях.
Пример использования блоков try и catch в Java:
try {
// Код, который может породить исключение
} catch (ExceptionType e) {
// Код обработки исключения
}
Также можно использовать несколько блоков catch для обработки разных типов исключений:
try {
// Код, который может порождать исключения
} catch (ExceptionType1 e) {
// Обработка исключения типа 1
} catch (ExceptionType2 e) {
// Обработка исключения типа 2
} catch (Exception e) {
// Общая обработка исключения
} finally {
// Код который сработает в любом случае
}
1314. Что делает ключевое слово volatile?
Ключевое слово volatile в Java используется для гарантии, что значения полей объектов будут согласованы между потоками и не будут кэшироваться в рантайме. Кэширование может привести к непредсказуемым результатам при доступе к изменяемым полям из разных потоков исполнения.
Когда поле объявлено как volatile, Java гарантирует, что доступ к этому полю со стороны разных потоков будет согласован и последовательным. Это обеспечивает правильную синхронизацию между потоками, когда один поток записывает в это поле, а другой поток его читает.
Например:
public class MyRunnable implements Runnable {
private volatile boolean running;
public void run() {
while (running) {
// делаем что-то здесь
}
}
public void stop() {
running = false;
}
}
Здесь мы объявляем поле running как volatile, чтобы гарантировать, что его значение будет согласовано между потоками. Мы используем это поле для остановки выполнения потока в методе run(), проверяя его значение на каждой итерации цикла. Метод stop() устанавливает значение running в false, чтобы остановить цикл while в методе run().
Важно отметить, что использование ключевого слова volatile не гарантирует атомарности операций чтения и записи. Для решения этой проблемы можно использовать блокировки.
1315. Что такое Future? Что такое CompletableFuture? Какие задачи они решают?
Future и CompletableFuture - это классы из пакета java.util.concurrent, которые позволяют делегировать выполнение асинхронных задач на другой поток, не блокируя при этом главный поток. Они предоставляют возможность получить результат выполнения задачи в будущем, в виде объекта Future.
Класс Future представляет собой обертку, которая содержит результат асинхронной операции, но не блокирует поток, который вызвал эту операцию. Для получения результата можно использовать метод get() объекта Future, который блокирует поток до того момента, пока результат не станет доступным.
Класс CompletableFuture построен поверх Future и предоставляет более широкие возможности для управления асинхронными задачами. Он позволяет объединять и комбинировать несколько асинхронных операций и определять цепочки операций, которые будут выполнены, когда все результаты будут готовы. CompletableFuture также поддерживает Callback функции, которые вызовутся после того, как операция закончится.
Использование Future и CompletableFuture может значительно улучшить производительность приложения, позволяет более эффективно использовать ресурсы компьютера и обеспечивать отзывчивость приложения.
1316. Что такое нормальная форма БД? Виды и мотивировки приведения БД к нормальной форме?
ормальная форма БД (НФБД) - это систематический подход к проектированию и оптимизации баз данных. Она определяет правила, которым должна соответствовать структура данных в базе данных, чтобы обеспечить эффективность, целостность и удобство использования.
Существует несколько уровней нормальной формы, каждый из которых имеет свои требования к структуре данных. Вот основные уровни нормальной формы:
- Первая нормальная форма (1НФ):
- Каждая ячейка таблицы должна содержать только одно значение.
- Каждая колонка таблицы должна иметь уникальное имя.
- Каждая строка таблицы должна быть уникальной.
- Вторая нормальная форма (2НФ):
- Все атрибуты таблицы должны полностью зависеть от первичного ключа.
- Если атрибуты зависят только от части первичного ключа, они должны быть выделены в отдельную таблицу.
- Третья нормальная форма (3НФ):
- Не должно быть транзитивных зависимостей между атрибутами таблицы.
- Если атрибуты зависят от других атрибутов, они должны быть выделены в отдельную таблицу.
- Бойса-Кодда-Нормальная Форма (BCNF):
-
Все зависимости функциональных зависимостей должны быть ключевыми зависимостями.
-
Мотивировки приведения БД к нормальной форме
-
Приведение базы данных к нормальной форме имеет несколько преимуществ:
-
Устранение избыточности данных: Нормализация помогает избежать повторения данных в базе данных, что позволяет сэкономить место и обеспечить целостность данных.
-
Улучшение производительности: Нормализация может улучшить производительность базы данных, так как она позволяет эффективно хранить и извлекать данные.
-
Обеспечение целостности данных: Нормализация помогает предотвратить аномалии данных, такие как потеря данных или несогласованность данных.
-
Упрощение обновлений и модификаций: Нормализация упрощает процесс обновления и модификации данных, так как изменения вносятся только в одном месте.
Улучшение понимания данных: Нормализация помогает лучше понять структуру данных и их взаимосвязи.
В целом, нормализация базы данных является важным шагом в проектировании баз данных, который помогает обеспечить эффективность, целостность и удобство использования данных.
1317. Что такое JDBC?
JDBC (Java Database Connectivity) - это API , которое позволяет Java-приложениям работать с базами данных. JDBC содержит интерфейсы и классы, которые позволяют Java-приложениям установить соединение с базой данных, отправлять SQL-запросы и осуществлять манипуляции с данными. JDBC позволяет подключаться к различным СУБД, включая Oracle, MySQL, Microsoft SQL Server и др.
Пример использования JDBC для получения данных из базы данных:
import java.sql.*;
public class Example {
public static void main(String[] args) {
try {
// Установка соединения с базой данных
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost/mydatabase", "username", "password");
// Создание запроса и выполнение его
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM customers");
// Обработка результатов запроса
while (rs.next()) {
String name = rs.getString("name");
int age = rs.getInt("age");
System.out.println(name + " " + age);
}
// Закрытие соединения
rs.close();
stmt.close();
conn.close();
} catch (Exception e) {
System.out.println("Error: " + e.getMessage());
}
}
}
Этот код подключается к MySQL базе данных с именем mydatabase и получает данные из таблицы customers.
1318. Что такое statement в контексте JDBC? Виды и отличия.
В контексте JDBC, Statement - это интерфейс для выполнения SQL-запросов к базе данных. Он позволяет создавать объекты для выполнения запросов SQL на основе подключения к базе данных. В JDBC существует три типа Statement:
-
Statement – простой объект для выполнения запросов без параметров.
-
PreparedStatement – позволяет создавать запросы с параметрами, что облегчает их использование и предотвращает SQL-инъекции.
-
CallableStatement – используется для вызова хранимых процедур в базе данных.
Основное отличие PreparedStatement от Statement заключается в том, что PreparedStatement запоминает SQL-запрос при своём создании и присваивает значения параметров только при его выполнении, делая его производительнее и безопаснее.
Для использования Statement необходимо создать объект, используя методы Connection.createStatement() или Connection.prepareCall(), затем использовать методы объекта Statement для выполнения запросов и получения результатов.
Пример создания объекта Statement и выполнения запроса SELECT с использованием него:
import java.sql.*;
public class Example {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
conn = DriverManager.getConnection("jdbc:mysql://localhost/test?" +
"user=misha&password=secret");
stmt = conn.createStatement();
rs = stmt.executeQuery("SELECT * FROM users");
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println("ID: " + id + ", Name: " + name);
}
} catch (SQLException ex) {
ex.printStackTrace();
} finally {
try {
if (rs != null) {
rs.close();
}
if (stmt != null) {
stmt.close();
}
if (conn != null) {
conn.close();
}
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
}
Этот пример создает объект Statement с помощью метода createStatement()
1319. Что такое Hibernate? Что такое JPA? Их отличия.
Hibernate - это фреймворк для объектно-реляционного отображения (ORM), который позволяет связывать объекты Java с таблицами в базе данных. Он упрощает взаимодействие между приложением и базой данных, предоставляя механизм для выполнения операций CRUD (создание, чтение, обновление, удаление). Hibernate также устраняет необходимость писать ручные SQL-запросы, что делает процесс разработки более быстрым и эффективным.
JPA (Java Persistence API) - это стандарт Java EE для ORM , который определяет интерфейсы и классы для управления постоянными объектами. JPA предоставляет программистам удобный способ описывать объектно-реляционное отображение с помощью аннотаций или XML-конфигурации. Он позволяет использовать ORM на уровне абстракции, который похож на реляционную базу данных.
Hibernate и JPA тесно связаны друг с другом. JPA является стандартом для ORM, предоставляя API для работы с объектами и сущностями. Hibernate, с другой стороны, является одной из реализаций этого стандарта, но позволяет использовать дополнительные функции и возможности, не предусмотренные JPA. Поэтому, можно сказать, что Hibernate - это более мощный ORM-фреймворк, который частично включает в себя JPA.
1320. Что такое N+1 SELECT проблема?
N+1 SELECT проблема - это проблема, возникающая при использовании объектно-реляционного отображения (ORM) в базе данных. Она возникает, когда для получения связанных сущностей объекта выполняется N+1 дополнительных запросов к базе данных.
Давайте рассмотрим пример для наглядности. Предположим, у вас есть коллекция объектов команд (строк базы данных), и каждая команда имеет коллекцию объектов участников (также строки). Другими словами, связь "команда-участники" является отношением один-ко-многим.
Теперь предположим, что вам нужно перебрать все команды и для каждой команды вывести список участников. Наивная реализация ORM будет выполнять следующие действия:
Найти все команды:
SELECT * FROM команды
Затем для каждой команды найти их участников:
SELECT * FROM участники WHERE teamID = x
Если есть N команд, то вы можете понять, почему это приведет к N+1 запросам к базе данных.
Пример запросов:
SELECT * FROM команды
SELECT * FROM участники WHERE teamID = 1
SELECT * FROM участники WHERE teamID = 2
SELECT * FROM участники WHERE teamID = 3
... Это приводит к избыточным запросам к базе данных и может существенно снизить производительность вашего приложения.
Как решить проблему N+1 SELECT?
Существует несколько способов решения проблемы N+1 SELECT:
Использование жадной загрузки (eager loading): при использовании ORM вы можете настроить запросы таким образом, чтобы они загружали все связанные сущности одним запросом, а не выполняли дополнительные запросы для каждой сущности. Это может быть достигнуто с помощью аннотаций или конфигурационных параметров ORM.
Использование пакетной загрузки (batch loading): при использовании ORM вы можете настроить запросы таким образом, чтобы они выполнялись пакетно, загружая несколько связанных сущностей одним запросом, вместо выполнения отдельного запроса для каждой сущности.
Использование кэширования: вы можете использовать механизм кэширования ORM, чтобы избежать повторных запросов к базе данных для уже загруженных сущностей.
Выбор конкретного подхода зависит от вашей ситуации и требований к производительности. Важно учитывать, что каждый подход имеет свои преимущества и ограничения, и выбор должен быть основан на анализе конкретной ситуации.
1321. Что такое REST API?
REST API (Representational State Transfer Application Programming Interface) - это архитектурный стиль, который определяет набор ограничений и принципов для создания веб-сервисов. REST API позволяет взаимодействовать с удаленными серверами и обмениваться данными посредством стандартных HTTP-запросов, таких как GET, POST, PUT и DELETE.
REST API основан на следующих принципах:
-
Ресурсы (Resources): В REST API данные представляются в виде ресурсов, которые могут быть доступны по уникальным идентификаторам (URL). Ресурсы могут быть, например, объектами, коллекциями объектов или сервисами.
-
Универсальный интерфейс (Uniform Interface): REST API использует универсальный набор методов HTTP, таких как GET, POST, PUT и DELETE, для взаимодействия с ресурсами. Каждый метод имеет свою семантику и предназначен для выполнения определенных операций над ресурсами.
-
Без состояния (Stateless): Каждый запрос к REST API должен содержать все необходимые данные для его обработки. Сервер не хранит информацию о предыдущих запросах клиента, что делает REST API масштабируемым и независимым от состояния.
-
Клиент-серверная архитектура (Client-Server): REST API основан на разделении клиента и сервера. Клиент отправляет запросы на сервер, а сервер обрабатывает эти запросы и возвращает соответствующие ответы.
-
Кэширование (Caching): REST API поддерживает кэширование, что позволяет клиентам сохранять копии ответов сервера и использовать их для повторных запросов без обращения к серверу.
REST API широко используется в различных областях, таких как веб-разработка, мобильные приложения, облачные сервисы и многое другое. Он предоставляет гибкую и масштабируемую архитектуру для обмена данными между клиентами и серверами.
Базовые понятия Rest API — HTTP-протокол и API
Application Programming Interface (API), или программный интерфейс приложения — это набор инструментов, который позволяет одним программам работать с другими. API предусматривает, что программы могут работать в том числе и на разных компьютерах. В этом случае требуется организовать интерфейс API так, чтобы ПО могло запрашивать функции друг друга через сеть.
Также API должно учитывать, что программы могут быть написаны на различных языках программирования и работать в разных операционных системах.
Пример Бухгалтерское приложение для выставления счетов. Счета хранятся на сервере: мобильное приложение обращается к нему через API и показывает на экране то, что нужно. REST API позволяет использовать для общения между программами протокол HTTP (зашифрованная версия — HTTPS), с помощью которого мы получаем и отправляем большую часть информации в интернете.
HTTP довольно прост. Посмотрим на его работу на примере. Допустим, есть адрес http://website.com/something. Он состоит из двух частей: первая — это адрес сайта или сервера, то есть http://website.com. Вторая — адрес ресурса на удаленном сервере, в данном примере — /something.
Вбивая в адресную строку URL-адрес http://website.com/something, мы на самом деле идем на сервер website.com и запрашиваем ресурс под названием /something. «Пойди вот туда, принеси мне вот то» — и есть HTTP-запрос.
Пример HTTP-запроса к серверу
Теперь представим, что по адресу website.com работает программа, к которой хочет обратиться другая программа. Чтобы программа понимала, какие именно функции нужны, используют различные адреса.
Пример В бухгалтерском сервисе работа со счетами может быть представлена в API ресурсом /invoices. А банковские реквизиты — ресурсом /requisites. Названия ресурсов придумывают по правилам формирования URL в интернете. Методы HTTP: основа работы REST API Чтобы ресурс, который вы запрашиваете, выполнял нужные действия, используют разные способы обращения к нему. Например, если вы работаете со счетами с помощью ресурса /invoices, который мы придумали выше, то можете их просматривать, редактировать или удалять.
В API-системе четыре классических метода:
GET — метод чтения информации. GET-запросы всегда только возвращают данные с сервера, и никогда их не меняют и не удаляют. В бухгалтерском приложении GET /invoices вы открываете список всех счетов.
POST — создание новых записей. В нашем приложении POST /invoices используется, когда вы создаете новый счет на оплату.
PUT — редактирование записей. Например, PUT /invoices вы исправляете номер счета, сумму или корректируете реквизиты.
DELETE — удаление записей. В нашем приложении DELETE /invoices удаляет старые счета, которые контрагенты уже оплатили.
Таким образом, мы получаем четыре функции, которые одна программа может использовать при обращении к данным ресурса, в примере — это ресурс для работы со счетами /invoices.
Построение API-системы с использованием ресурсов, HTTP и различных запросов к ним как раз и будет Representational State Transfer (REST API) — передачей состояния представления. Для чего используют REST API Архитектура REST API — самое популярное решение для организации взаимодействия между различными программами. Так произошло, поскольку HTTP-протокол реализован во всех языках программирования и всех операционных системах, в отличие от проприетарных протоколов.
Чаще всего REST API применяют:
Для связи мобильных приложений с серверными. Для построения микросервисных серверных приложений. Это архитектурный подход, при котором большие приложения разбиваются на много маленьких частей. Для предоставления доступа к программам сторонних разработчиков. Например, Stripe API позволяет программистам встраивать обработку платежей в свои приложения. Что еще важно знать при работе с REST API Каждый REST API запрос сообщает о результатах работы числовыми кодами — HTTP-статусами.
Например, редактирование записи на сервере может отработать успешно (код 200), может быть заблокировано по соображениям безопасности (код 401 или 403), а то и вообще сломаться в процессе из-за ошибки сервера (код 500). Цифровые статусы выполнения ошибок — аналог пользовательских сообщений с результатами работы программы.
Также REST API позволяет обмениваться не только текстовой информацией. С помощью этого инструмента можно передавать файлы и данные в специальных форматах: XML, JSON, Protobuf.
Есть и другие способы построения API-систем, например: JSON-RPC, XML-RPC и GraphQL. Но пока REST остается самым популярным и востребованным инструментом для построения взаимодействий между удаленными приложениями. За годы использования REST инженеры накопили много практик по разработке API, балансировке и обработке API HTTP-трафика на облачных и железных серверах, а также в приложениях, которые работают в контейнерах. Так что REST API — пример решения, которое подходят для почти любых систем.
1321. Отличие Aerospike от Redis
Aerospike и Redis - это две разные системы управления базами данных, которые имеют свои особенности и применения.
Aerospike - это высокопроизводительная NoSQL база данных, разработанная для работы с большими объемами данных и высокой нагрузкой. Она предназначена для обработки транзакций в реальном времени и аналитических запросов. Aerospike обладает масштабируемостью и надежностью, а также поддерживает горизонтальное масштабирование и репликацию данных. Она также предоставляет возможность работы с данными в оперативной памяти или на диске.
Redis - это высокопроизводительная база данных, которая работает в оперативной памяти. Она предоставляет широкий набор функций, таких как кэширование, хранение структур данных, публикация/подписка на сообщения и многое другое. Redis также обладает высокой производительностью и низкой задержкой при обработке запросов. Она поддерживает различные типы данных, включая строки, списки, хэши, множества и сортированные множества.
Отличия:
Модель данных: Aerospike и Redis имеют разные модели данных. Aerospike предоставляет гибкую модель данных, позволяющую хранить и обрабатывать сложные структуры данных, включая JSON и BLOB. Redis, с другой стороны, предоставляет набор простых типов данных и операций для работы с ними.Хранение данных: Aerospike может хранить данные как в оперативной памяти, так и на диске, что обеспечивает гибкость и масштабируемость. Redis работает только в оперативной памяти, что обеспечивает высокую скорость доступа к данным, но ограничивает объем данных, которые можно хранить.Масштабируемость: Обе системы поддерживают горизонтальное масштабирование, но Aerospike предоставляет более гибкие возможности для распределения данных и обработки запросов в распределенной среде.Производительность: Обе системы обладают высокой производительностью, но Redis, работая в оперативной памяти, может достичь еще более низкой задержки при обработке запросов.Функциональность: Redis предоставляет богатый набор функций, таких как публикация/подписка на сообщения, транзакции и сортированные множества. Aerospike также предоставляет некоторые дополнительные функции, такие как аналитические запросы и возможность работы с данными в оперативной памяти или на диске.
В зависимости от конкретных требований и задач, выбор между Aerospike и Redis будет зависеть от предпочтений и потребностей в производительности, масштабируемости и функциональности.
1322. Какие существуют функциональные фичи в Java
ava предоставляет несколько функциональных фич, которые были введены в различных версиях языка. Вот некоторые из них:
Лямбда-выражения: Лямбда-выражения позволяют передавать функции в качестве параметров или использовать их в качестве значений. Они представляют собой компактный способ определения анонимных функций. Пример:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.forEach(n -> System.out.println(n));
Функциональные интерфейсы: Функциональные интерфейсы - это интерфейсы, которые содержат только один абстрактный метод. Они используются вместе с лямбда-выражениями для создания экземпляров функциональных объектов. Пример:
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
Stream API: Stream API предоставляет возможность работать с коллекциями данных в функциональном стиле. Он позволяет выполнять операции над элементами коллекции, такие как фильтрация, сортировка, отображение и другие. Пример:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream()
.filter(n -> n % 2 == 0)
.mapToInt(n -> n)
.sum();
Методы по умолчанию в интерфейсах: В Java 8 была добавлена возможность определения методов по умолчанию в интерфейсах. Это позволяет добавлять новые методы в существующие интерфейсы без необходимости изменения всех реализаций. Пример:
interface MyInterface {
default void myMethod() {
System.out.println("Default method");
}
}
Optional: Optional - это контейнер, который может содержать или не содержать значение. Он предоставляет удобные методы для работы с возможным отсутствием значения, такими как проверка наличия значения, получение значения или выполнение действия, если значение отсутствует. Пример:
Optional<String> name = Optional.ofNullable(getName());
name.ifPresent(n -> System.out.println("Name: " + n));
1323. Отличие Unmodifiable от Immutable
Unmodifiable и Immutable - это два разных понятия в контексте Java и они имеют различные свойства и использование.
Unmodifiable (неизменяемый) относится к коллекциям, которые не могут быть изменены после создания. Это означает, что вы не можете добавлять, удалять или изменять элементы в такой коллекции. Однако, сама коллекция может быть изменена, например, вы можете изменить элементы внутри коллекции, но вы не можете изменить саму коллекцию (например, добавить или удалить элементы). Коллекции, созданные с помощью методов Collections.unmodifiableXXX(), являются неизменяемыми.
Immutable (неизменяемый) относится к объектам, которые не могут быть изменены после создания. Это означает, что вы не можете изменить значения полей объекта после его создания. Классы, объявленные с ключевым словом final или поля, объявленные с ключевым словом final, являются неизменяемыми. Неизменяемые объекты обеспечивают безопасность потоков и предотвращают неожиданные изменения состояния объекта.
Таким образом, основное различие между Unmodifiable и Immutable заключается в том, что Unmodifiable относится к коллекциям, которые не могут быть изменены после создания, в то время как Immutable относится к объектам, которые не могут быть изменены после создания.
Примеры использования:
Unmodifiable:
List<String> list = new ArrayList<>();
list.add("Java");
list.add("Python");
List<String> unmodifiableList = Collections.unmodifiableList(list);
unmodifiableList.add("C++"); // Вызовет UnsupportedOperationException
Immutable:
final class Person {
private final String name;
private final int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
Person person = new Person("John", 25);
person.setName("Mike"); // Не допустимо, так как объект неизменяемый
Важно отметить, что Unmodifiable и Immutable не являются взаимозаменяемыми понятиями. Unmodifiable относится к коллекциям, в то время как Immutable относится к объектам.
1324. Функциональные интерфейсы
Функциональные интерфейсы - это интерфейсы программного обеспечения, которые определяют только один абстрактный метод. Они являются ключевым понятием в функциональном программировании и языке Java, начиная с версии 8.
В функциональном программировании функции рассматриваются как объекты первого класса, и функциональные интерфейсы предоставляют способ определения и использования таких функций. Функциональные интерфейсы обычно используются в контексте лямбда-выражений и методов ссылки.
В языке Java функциональные интерфейсы обозначаются аннотацией @FunctionalInterface. Они могут содержать только один абстрактный метод, но могут также иметь дополнительные методы по умолчанию или статические методы.
Примером функционального интерфейса в Java является java.util.function.Predicate, который определяет метод test, принимающий аргумент и возвращающий булево значение. Этот интерфейс может быть использован для определения условий фильтрации элементов коллекции.
import java.util.function.Predicate;
public class Main {
public static void main(String[] args) {
Predicate<Integer> isEven = num -> num % 2 == 0;
System.out.println(isEven.test(4)); // true
System.out.println(isEven.test(5)); // false
}
}
В этом примере isEven является экземпляром функционального интерфейса Predicate<Integer>, определенного с помощью лямбда-выражения. Метод test проверяет, является ли число четным, и возвращает соответствующее булево значение.
1325. Метод reduce()
Метод reduce() в Java используется для выполнения агрегации элементов в коллекции или потоке данных. Он принимает функцию аккумулятора и последовательно применяет ее к элементам, чтобы получить один результирующий элемент.
Пример использования метода reduce() в Java:
import java.util.Arrays;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// Пример 1: Сумма всех чисел
int sum = numbers.stream()
.reduce(0, (a, b) -> a + b);
System.out.println("Сумма всех чисел: " + sum);
// Пример 2: Нахождение максимального числа
int max = numbers.stream()
.reduce(Integer.MIN_VALUE, (a, b) -> a > b ? a : b);
System.out.println("Максимальное число: " + max);
// Пример 3: Конкатенация строк
List<String> strings = Arrays.asList("Hello", " ", "world", "!");
String result = strings.stream()
.reduce("", (a, b) -> a + b);
System.out.println("Результат конкатенации строк: " + result);
}
}
В примере выше метод reduce() принимает начальное значение аккумулятора (0 для суммы, Integer.MIN_VALUE для поиска максимального числа, пустую строку для конкатенации строк) и лямбда-выражение, которое определяет, как применить операцию к текущему аккумулятору и следующему элементу.
Примечание: В Java 8 и выше метод reduce() также может быть использован с Optional, чтобы избежать возможности отсутствия результата.
1326. Метод reduce() чем его преимущество перед циклом
Метод reduce() в Java используется для выполнения агрегации элементов в коллекции или потоке данных. Он позволяет применить определенную операцию к каждому элементу и последовательно объединять результаты в одно значение.
Основное преимущество метода reduce() перед циклом заключается в его удобстве и выразительности. Вместо того, чтобы писать много кода для итерации по коллекции, выполнения операции и объединения результатов, метод reduce() позволяет сделать это в одной строке кода.
Пример использования метода reduce():
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// Сложение всех чисел в коллекции
int sum = numbers.stream()
.reduce(0, (a, b) -> a + b);
System.out.println(sum); // Выводит: 15
В данном примере мы используем метод reduce() для сложения всех чисел в коллекции numbers. Начальное значение суммы задано как 0, а операция сложения (a, b) -> a + b применяется к каждой паре элементов в коллекции.
Метод reduce() также может быть использован для выполнения других операций, таких как поиск минимального или максимального значения, конкатенация строк и т. д. В зависимости от требуемой операции, вы можете передать соответствующую функцию в качестве аргумента метода reduce().
Таким образом, метод reduce() предоставляет удобный и выразительный способ агрегации элементов в коллекции или потоке данных, что делает его предпочтительным в некоторых случаях перед использованием циклов.
1327. HashTable и ConcurrentHashMap - отличия и что эффективнее
Отличия между HashTable и ConcurrentHashMap HashTable и ConcurrentHashMap являются двумя различными реализациями интерфейса Map в Java. Они оба предоставляют ассоциативные массивы, где данные хранятся в виде пар "ключ-значение". Однако, у них есть несколько отличий:
1. Потокобезопасность:
HashTable является потокобезопасной реализацией Map. Все его методы синхронизированы, что означает, что только один поток может изменять HashTable в определенный момент времени. Это обеспечивает безопасность при использовании HashTable в многопоточной среде. ConcurrentHashMap также является потокобезопасной реализацией Map, но с более эффективным механизмом синхронизации. В отличие от HashTable, ConcurrentHashMap разделяет свое пространство ключей на несколько сегментов, и каждый сегмент может быть блокирован независимо от других. Это позволяет нескольким потокам одновременно изменять разные сегменты, что повышает производительность в многопоточной среде.
2. Итераторы:
Итераторы в HashTable являются fail-fast, что означает, что если HashTable изменяется во время итерации, будет выброшено исключение ConcurrentModificationException. Итераторы в ConcurrentHashMap являются fail-safe, что означает, что они работают с копией данных, полученных на момент создания итератора, и не выбрасывают исключение ConcurrentModificationException, если ConcurrentHashMap изменяется во время итерации.
3. Производительность:
В общем случае, ConcurrentHashMap обеспечивает более высокую производительность, чем HashTable, особенно в многопоточной среде. Это связано с более эффективным механизмом синхронизации и разделением данных на сегменты.
Что эффективнее: HashTable или ConcurrentHashMap?
В зависимости от конкретной ситуации и требований проекта, одна реализация может быть более эффективной, чем другая.
- Если вам нужна потокобезопасность и вы работаете в однопоточной среде, то использование HashTable может быть достаточным.
- Если вам нужна потокобезопасность и вы работаете в многопоточной среде, то рекомендуется использовать ConcurrentHashMap, так как он обеспечивает более высокую производительность и масштабируемость.
- Важно учитывать, что ConcurrentHashMap может потреблять больше памяти из-за разделения данных на сегменты. Поэтому, если вам не требуется потокобезопасность, можно рассмотреть использование других реализаций Map, таких как HashMap, которые не имеют накладных расходов на синхронизацию.
Пример использования ConcurrentHashMap:
import java.util.concurrent.ConcurrentHashMap;
public class Example {
public static void main(String[] args) {
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key1", 1);
map.put("key2", 2);
map.put("key3", 3);
int value = map.get("key2");
System.out.println(value); // Output: 2
}
}
В этом примере мы создаем экземпляр ConcurrentHashMap, добавляем несколько пар "ключ-значение" и получаем значение по ключу "key2".
1328. Классы мониторов для мониторинга многопоточки
Классы мониторов для мониторинга многопоточки В Java существуют несколько классов, которые можно использовать для мониторинга и синхронизации многопоточных операций. Некоторые из них включают:
synchronized: Ключевое слово synchronized может быть использовано для создания монитора на уровне метода или блока кода. Когда поток входит в синхронизированный блок или вызывает синхронизированный метод, он захватывает монитор объекта, на котором выполняется синхронизация. Это позволяет потокам синхронизированно выполнять операции с общими данными.
wait() и notify(): Методы wait() и notify() являются частью класса Object и используются для реализации механизма ожидания и уведомления между потоками. Поток может вызвать метод wait(), чтобы перейти в состояние ожидания, пока другой поток не вызовет метод notify() или notifyAll() для уведомления ожидающих потоков.
Lock и Condition: Пакет java.util.concurrent.locks предоставляет альтернативные механизмы блокировки и условий для управления доступом к общим ресурсам. Классы Lock и Condition предоставляют более гибкий и мощный способ управления потоками, чем ключевое слово synchronized.
Atomic классы: Пакет java.util.concurrent.atomic предоставляет классы, которые обеспечивают атомарные операции чтения и записи для примитивных типов данных. Эти классы, такие как AtomicInteger и AtomicLong, позволяют безопасно выполнять операции с общими данными без необходимости использования блокировок.
Все эти классы предоставляют различные механизмы для мониторинга и синхронизации многопоточных операций в Java. Выбор конкретного класса зависит от требований вашей программы и контекста использования.
1329. Retry block в Java
Retry block в Java - это блок кода, который позволяет повторно выполнить определенную инструкцию или группу инструкций в случае возникновения исключения или ошибки. Retry block обычно используется для обработки ситуаций, когда выполнение кода может привести к ошибке, но есть возможность восстановиться и повторить попытку выполнения.
В Java нет встроенной конструкции "retry", но вы можете реализовать retry block с помощью цикла и обработки исключений. Вот пример кода, который демонстрирует, как реализовать retry block в Java:
int maxRetries = 3;
int retryCount = 0;
boolean success = false;
while (retryCount < maxRetries && !success) {
try {
// Ваш код, который нужно повторить
someInstruction();
// Если код успешно выполнен, устанавливаем флаг success в true
success = true;
} catch (NearlyUnexpectedException e) {
// Если произошло исключение, увеличиваем счетчик попыток и продолжаем цикл
retryCount++;
// Исправляем проблему, вызвавшую исключение
fixTheProblem();
}
}
В этом примере кода мы используем цикл while для повторного выполнения инструкции someInstruction() до тех пор, пока не будет достигнуто максимальное количество попыток (maxRetries) или пока не будет достигнут успех (success = true). Если происходит исключение NearlyUnexpectedException, мы увеличиваем счетчик попыток и вызываем метод fixTheProblem(), чтобы исправить проблему, вызвавшую исключение.
Это простой пример реализации retry block в Java. В реальных сценариях вы можете настроить retry block более гибко, добавив дополнительные условия и настройки, чтобы управлять повторными попытками выполнения кода.
1330. Шаблон Builder - что такое и для каких задач
Шаблон Builder (Строитель) является одним из паттернов проектирования, который используется для создания сложных объектов пошагово. Он позволяет создавать объекты с различными конфигурациями, скрывая сложность и детали процесса создания.
Для каких задач используется шаблон Builder?
Шаблон Builder применяется в ситуациях, когда необходимо создавать объекты с большим количеством настраиваемых параметров или с различными конфигурациями. Он позволяет разделить процесс создания объекта на отдельные шаги и предоставляет гибкость в настройке каждого шага.
Некоторые примеры задач, для которых может быть полезен шаблон Builder:
- Создание сложных объектов, таких как графические интерфейсы, отчеты или конфигурации приложений.
- Создание объектов с большим количеством настраиваемых параметров, где не все параметры обязательны.
- Создание объектов с различными конфигурациями, например, различные варианты продуктов или меню.
Шаблон Builder позволяет упростить процесс создания сложных объектов и обеспечивает гибкость в настройке каждого шага. Он также способствует улучшению читаемости и поддерживаемости кода, так как позволяет изолировать процесс создания объекта от его использования.
Пример использования шаблона Builder на языке Java:
public class Product {
private String property1;
private String property2;
// ...
public Product(String property1, String property2) {
this.property1 = property1;
this.property2 = property2;
// ...
}
// Getters and setters
// ...
}
public interface Builder {
void setProperty1(String property1);
void setProperty2(String property2);
// ...
Product build();
}
public class ConcreteBuilder implements Builder {
private String property1;
private String property2;
// ...
@Override
public void setProperty1(String property1) {
this.property1 = property1;
}
@Override
public void setProperty2(String property2) {
this.property2 = property2;
}
// ...
@Override
public Product build() {
return new Product(property1, property2);
}
}
public class Director {
private Builder builder;
public Director(Builder builder) {
this.builder = builder;
}
public Product construct() {
builder.setProperty1("Value 1");
builder.setProperty2("Value 2");
// ...
return builder.build();
}
}
public class Main {
public static void main(String[] args) {
Builder builder = new ConcreteBuilder();
Director director = new Director(builder);
Product product = director.construct();
// Использование созданного объекта Product
}
}
В этом примере шаблон Builder используется для создания объекта Product с настраиваемыми свойствами. Класс Product представляет сложный объект, а интерфейс Builder определяет методы для настройки каждого свойства объекта. Класс ConcreteBuilder реализует интерфейс Builder и предоставляет конкретную реализацию методов настройки. Класс Director определяет последовательность шагов для создания объекта Product. В методе main создается экземпляр ConcreteBuilder, передается в Director, и затем вызывается метод construct(), который возвращает готовый объект Product.
Шаблон Builder позволяет создавать сложные объекты пошагово и настраивать их свойства. Он облегчает процесс создания объектов с большим количеством настраиваемых параметров и обеспечивает гибкость в настройке каждого шага.
1331. Что будет если конструктор класса будет private, и зачем это нужно
Зачем нужен приватный конструктор класса? Приватный конструктор класса ограничивает доступ к созданию объектов этого класса извне. Это может быть полезно в различных ситуациях, например:
Ограничение создания объектов: Если конструктор класса объявлен как приватный, то объекты этого класса не могут быть созданы напрямую с помощью оператора new. Это может быть полезно, когда вы хотите контролировать количество и способы создания объектов данного класса.
Ограничение наследования: Если все конструкторы класса объявлены как приватные, то этот класс не может быть наследован другими классами. Это может быть полезно, когда вы хотите предотвратить создание подклассов или ограничить наследование только внутри самого класса.
Ограничение инстанцирования: Приватный конструктор может быть использован для создания класса, который может иметь только один экземпляр (singleton). В этом случае, класс сам контролирует создание и доступ к своему единственному экземпляру.
Что произойдет, если конструктор класса будет приватным?
Если конструктор класса объявлен как приватный, то объекты этого класса не могут быть созданы извне класса. Это означает, что другие классы не смогут создавать экземпляры этого класса с помощью оператора new. Вместо этого, доступ к созданию объектов будет ограничен только внутри самого класса.
Приватный конструктор может быть полезен, когда вы хотите ограничить создание объектов данного класса или контролировать способы их создания. Например, если класс является синглтоном (имеет только один экземпляр), то приватный конструктор может быть использован для создания и инициализации этого единственного экземпляра класса.
Пример использования приватного конструктора для создания синглтона:
public class Singleton {
private static Singleton instance;
private Singleton() {
// Приватный конструктор
}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
В этом примере, конструктор класса Singleton объявлен как приватный, что ограничивает создание объектов этого класса извне. Вместо этого, для получения экземпляра класса используется статический метод getInstance(), который создает и возвращает единственный экземпляр класса Singleton.
1332. Singleton - почему его называют анти-паттерн
Singleton - это паттерн проектирования, который описывает создание класса, у которого может быть только один экземпляр, и предоставляет глобальную точку доступа к этому экземпляру. Однако, некоторые разработчики считают Singleton анти-паттерном. Давайте рассмотрим несколько причин, почему Singleton может быть рассмотрен как анти-паттерн:
1. Сложность тестирования: Использование Singleton может затруднить тестирование кода, так как он создает глобальное состояние, которое может влиять на другие тесты. Это может привести к нестабильности и сложностям в создании независимых тестовых случаев.
2. Зависимость от глобального состояния: Singleton создает глобальное состояние, которое может быть доступно из любой части программы. Это может привести к проблемам с управлением состоянием и усложнению отладки и поддержки кода.
3. Сложность расширения: Использование Singleton может затруднить расширение функциональности, так как он предоставляет только один экземпляр класса. Если вам потребуется создать другую версию класса или добавить новые возможности, вам придется изменять сам Singleton.
4. Нарушение принципа единственной ответственности: Singleton может нарушать принцип единственной ответственности, так как он отвечает не только за создание экземпляра класса, но и за предоставление глобальной точки доступа к этому экземпляру. Это может привести к нарушению модульности и усложнению понимания кода.
В целом, Singleton может быть полезным в некоторых случаях, но его использование должно быть оправдано и осознанным. Рекомендуется обдумать альтернативные подходы и рассмотреть другие паттерны проектирования, прежде чем применять Singleton.
1333. Как обойтись без synchronized в многопоточке на Singletonе
Для обхода использования synchronized в многопоточной среде при работе с синглтоном можно использовать двойную проверку блокировки (double-checked locking). Этот подход позволяет уменьшить накладные расходы на синхронизацию и обеспечить безопасность при работе с синглтоном.
Вот пример реализации синглтона без использования synchronized:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
// Приватный конструктор
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
В этом примере переменная instance объявлена как volatile, что гарантирует видимость изменений этой переменной между потоками. Двойная проверка блокировки позволяет избежать лишней синхронизации в большинстве случаев, так как большинство потоков просто получают уже созданный экземпляр синглтона без необходимости создавать новый.
Примечание: Важно отметить, что в Java начиная с версии 5, инициализация статических полей класса происходит атомарно, поэтому использование volatile в данном случае обеспечивает корректную инициализацию синглтона без необходимости использования synchronized.
1334. Что такое Double check
Double check в Java - это шаблон проектирования, который используется для создания синглтона (класса, который может иметь только один экземпляр). Он использует двойную проверку для обеспечения того, что только один экземпляр класса будет создан.
В Java double check реализуется с использованием синхронизации и ключевого слова volatile. Вот пример кода, демонстрирующего double check в Java:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
// Приватный конструктор
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
В этом примере переменная instance объявлена как volatile, чтобы гарантировать, что все потоки будут видеть последнюю запись этой переменной. Это важно, чтобы избежать проблем с кэш-кохерентностью и частичной инициализацией объекта.
Double check позволяет избежать избыточной синхронизации и улучшить производительность при создании синглтона в многопоточной среде. Однако, важно правильно реализовать double check, чтобы избежать потенциальных проблем с памятью и синхронизацией.
1335. Stateful и Stateless сервисы
Stateful и Stateless сервисы - это два разных подхода к разработке программного обеспечения в Java.
Stateful сервисы хранят информацию о состоянии клиента между запросами. Это означает, что сервис сохраняет данные о предыдущих взаимодействиях с клиентом и использует эту информацию при обработке последующих запросов. Примером Stateful сервиса может быть сессионный бин в Java Enterprise Edition (Java EE), который сохраняет состояние между вызовами методов.
Stateless сервисы, напротив, не хранят информацию о состоянии клиента между запросами. Каждый запрос обрабатывается независимо от предыдущих запросов, и сервис не сохраняет никаких данных о предыдущих взаимодействиях. Примером Stateless сервиса может быть RESTful веб-сервис, который не хранит состояние между запросами и обрабатывает каждый запрос независимо.
Выбор между Stateful и Stateless сервисами зависит от требований вашего приложения. Stateful сервисы могут быть полезны, если вам нужно сохранять состояние клиента и использовать его при обработке запросов. Однако они могут быть более сложными в масштабировании и требовать больше ресурсов. Stateless сервисы обычно более просты в разработке и масштабировании, но они не могут сохранять состояние между запросами.
В Java вы можете реализовать Stateful и Stateless сервисы с помощью различных технологий и фреймворков, таких как Java EE, Spring или JAX-RS.
1336. Optimistic vs. Pessimistic locking
Оптимистическая и пессимистическая блокировка - это две стратегии управления одновременным доступом к данным в базе данных.
Оптимистическая блокировка - это стратегия, при которой вы сначала читаете запись, запоминаете номер версии и проверяете, не изменилась ли версия перед записью обратно. При записи обратно вы фильтруете обновление по версии, чтобы убедиться, что оно атомарно (т.е. не было обновлено между проверкой версии и записью записи на диск) и обновляете версию за один раз. Если запись изменена (т.е. версия отличается от вашей), вы отменяете транзакцию, и пользователь может ее повторно запустить.
Пессимистическая блокировка - это стратегия, при которой вы блокируете данные при чтении и изменении записи. Это гарантирует целостность данных, но требует осторожного проектирования приложения, чтобы избежать ситуаций, таких как взаимоблокировка.
Оптимистическая блокировка обычно используется в высоконагруженных системах и трехуровневых архитектурах, где подключение к базе данных не поддерживается на протяжении всей сессии. В этой ситуации клиент не может поддерживать блокировки базы данных, так как подключения берутся из пула и могут не использовать одно и то же подключение при каждом доступе.
Пессимистическая блокировка полезна, когда стоимость повторной попытки выполнения транзакции очень высока или когда конкуренция настолько велика, что многие транзакции будут откатываться, если использовать оптимистическую блокировку.
Обе стратегии имеют свои преимущества и недостатки, и выбор между ними зависит от конкретных требований вашего проекта.
1337. Ключевое отличие SQL vs NoSQL DBs
SQL (Structured Query Language) и NoSQL (Not Only SQL) являются двумя различными подходами к хранению и управлению данными. Они имеют ряд ключевых отличий:
Структура данных:
- SQL базы данных используют схему, которая определяет структуру данных, типы данных и связи между таблицами. Данные хранятся в таблицах с явно определенными столбцами и строками.
- NoSQL базы данных не требуют схемы и позволяют хранить данные в более гибкой форме. Они могут использовать различные модели данных, такие как документы, ключ-значение, столбцы или графы.
Масштабируемость:
- SQL базы данных обычно масштабируются вертикально, что означает, что они могут быть улучшены путем добавления более мощного оборудования. Они обычно имеют ограничения на количество данных, которые могут быть обработаны на одном сервере.
- NoSQL базы данных обычно масштабируются горизонтально, что означает, что они могут быть улучшены путем добавления дополнительных серверов. Они могут легко масштабироваться для обработки больших объемов данных.
Гибкость запросов:
- SQL базы данных используют язык структурированных запросов (SQL) для выполнения запросов и извлечения данных. SQL предоставляет мощные возможности для фильтрации, сортировки и агрегации данных.
- NoSQL базы данных обычно имеют свои собственные языки запросов, которые могут быть менее мощными, но более гибкими. Они обычно предоставляют простые операции чтения и записи, а также поддерживают индексацию для улучшения производительности.
Применение:
- SQL базы данных обычно используются для приложений, где требуется строгая структура данных и поддержка сложных запросов. Они хорошо подходят для транзакционных систем, таких как системы управления заказами или банковские системы.
- NoSQL базы данных обычно используются для приложений, где требуется гибкость и масштабируемость. Они хорошо подходят для систем с большим объемом данных, таких как системы управления контентом или системы аналитики больших данных.
В конечном счете, выбор между SQL и NoSQL базами данных зависит от требований вашего приложения и характеристик данных, с которыми вы работаете.
1338. Возможна ли изоляция транзакций в распределенных системах
В распределенных системах возможна изоляция транзакций, однако это может быть сложной задачей из-за нескольких факторов, таких как сетевая задержка, конкуренция за ресурсы и неоднородность системы.
ACID-транзакции
ACID (атомарность, согласованность, изолированность, долговечность) - это набор свойств, которые обеспечивают надежность и целостность транзакций. В распределенных системах, чтобы обеспечить изоляцию транзакций, используются различные протоколы и алгоритмы, такие как двухфазный коммит (2PC) и трехфазный коммит (3PC).
Двухфазный коммит (2PC)
2PC - это протокол, который обеспечивает атомарность и согласованность транзакций в распределенных системах. Он состоит из двух фаз: подготовка и фиксация. В фазе подготовки, координатор системы отправляет запросы на подтверждение транзакции всем участникам. Участники выполняют необходимые действия и отправляют ответы о готовности. Затем, в фазе фиксации, координатор принимает решение о фиксации или откате транзакции на основе полученных ответов. Если все участники подтвердили готовность, транзакция фиксируется, иначе она откатывается.
Трехфазный коммит (3PC)
3PC - это улучшенная версия протокола 2PC, которая добавляет третью фазу - предварительную подготовку. В этой фазе, координатор запрашивает участников подтверждение о готовности к фиксации транзакции. Если все участники готовы, то во второй фазе происходит фиксация, иначе транзакция откатывается. Трехфазный коммит устраняет некоторые проблемы, связанные с блокировкой ресурсов и отказами участников.
CAP-теорема
CAP-теорема утверждает, что в распределенной системе невозможно одновременно обеспечить согласованность (Consistency), доступность (Availability) и устойчивость к разделению (Partition tolerance). Поэтому в распределенных системах приходится делать компромиссы между этими тремя свойствами. Например, в системах, где требуется высокая доступность и устойчивость к разделению, может быть снижена согласованность.
NoSQL и ACID
В некоторых NoSQL базах данных, таких как MongoDB или Cassandra, изоляция транзакций может быть ограничена или отсутствовать полностью. Это связано с тем, что NoSQL базы данных обычно стремятся к высокой доступности и масштабируемости, а не к полной поддержке ACID-транзакций. Однако, некоторые NoSQL базы данных предоставляют механизмы для обеспечения изоляции транзакций, такие как многоверсионность (MVCC) в MongoDB или локальные транзакции в Cassandra.
Saga паттерн
Saga паттерн - это альтернативный подход к обработке транзакций в распределенных системах. Вместо использования одной большой транзакции, Saga разбивает ее на несколько маленьких шагов, каждый из которых выполняется в рамках отдельной транзакции. Если один из шагов не удался, Saga паттерн позволяет откатить уже выполненные шаги и восстановить систему в предыдущее состояние.
API Gateway
API Gateway - это прокси-сервер, который предоставляет единый точку входа для внешних клиентов к микросервисной архитектуре. Он может выполнять различные функции, включая маршрутизацию запросов, аутентификацию, авторизацию и управление транзакциями. API Gateway может использоваться для обеспечения изоляции транзакций в распределенных системах, например, путем использования транзакционных координаторов или паттернов, таких как Saga.
Примечание: Важно отметить, что реализация изоляции транзакций в распределенных системах может быть сложной и зависит от конкретных требований и характеристик системы. Различные подходы и технологии могут быть применены в зависимости от контекста и конкретных задач.
1339. Доказать CAP теорему
CAP-теорема (теорема о согласованности, доступности и устойчивости разделения) является фундаментальным результатом в области распределенных систем. Она утверждает, что невозможно создать распределенную систему, которая одновременно обладает следующими тремя свойствами:
Согласованность (Consistency): Каждое чтение из системы должно вернуть последнее записанное значение или ошибку. Это означает, что все узлы в системе должны видеть одинаковые данные в один и тот же момент времени.
Доступность (Availability): Каждый запрос должен получить ответ, успешный или неуспешный. Это означает, что система должна быть всегда доступна для обработки запросов.
Устойчивость разделения (Partition tolerance): Система должна продолжать работать даже при возникновении сбоев в сети, которые могут привести к разделению системы на несколько частей.
CAP-теорема утверждает, что в распределенной системе можно обеспечить только два из трех свойств CAP (согласованность, доступность, устойчивость разделения). Это означает, что при проектировании распределенной системы необходимо сделать компромисс между этими свойствами в зависимости от требований системы и ее контекста.
Доказательство CAP-теоремы в языке Java не является простой задачей, так как оно требует формальной математической логики и анализа. Однако, вы можете изучить работы Эрика Брюера (Brewer) и Сета Гильберта (Gilbert) для получения более подробной информации о доказательстве CAP-теоремы.
1340. Почему нет смысла гнаться за 100% или 99.999% надежности, если есть 99.99%
Когда речь идет о надежности программного обеспечения, важно понимать, что достижение абсолютной надежности практически невозможно. Независимо от языка программирования, даже самые надежные программы могут иметь ошибки или сбои. Поэтому стремиться к 100% или 99.999% надежности может быть нецелесообразно.
Java является одним из популярных языков программирования, который известен своей надежностью и стабильностью. Однако, даже при использовании Java, невозможно гарантировать 100% или 99.999% надежность. Всегда существует вероятность возникновения ошибок или проблем, связанных с программным обеспечением.
Вместо того, чтобы стремиться к абсолютной надежности, разработчики обычно стремятся к достижению определенного уровня надежности, который считается приемлемым для конкретного приложения или системы. Этот уровень надежности может быть определен на основе требований пользователя, бизнес-целей и других факторов.
Кроме того, повышение уровня надежности может потребовать дополнительных ресурсов, времени и затрат. Это может быть нецелесообразно с точки зрения бизнеса или разработки программного обеспечения. Поэтому важно найти баланс между достижением приемлемого уровня надежности и затратами, связанными с его достижением.
В итоге, хотя Java известна своей надежностью, нет смысла стремиться к абсолютной надежности, так как это практически невозможно. Вместо этого, разработчики должны стремиться к достижению определенного уровня надежности, который будет соответствовать требованиям и целям конкретного приложения или системы.
1341. Какие минусы Rest в высоконагруженных системах?
Есть несколько минусов у REST API в высоконагруженных системах:
-
REST API взаимодействует с HTTP протоколом, который не подходит для решения всех задач.
-
REST API требует большого количества запросов к серверу для получения всей необходимой информации, что может приводить к задержкам.
-
REST API не всегда может гарантировать безопасность при передаче конфиденциальной информации.
-
REST API может быть трудным в использовании для неопытных разработчиков.
-
Разработка и поддержка REST API может быть трудоемким процессом, особенно при работе с большим количеством конечных точек.
-
REST API может оказаться неэффективным при работе с большим количеством пользователей, особенно при необходимости частой передачи больших объемов данных.
-
Узкие места в производительности: Rest API может иметь узкие места в производительности из-за проблем с сетью, нагрузкой на БД и других причин. В таких случаях может потребоваться более сложная архитектура, как, например, микросервисная архитектура.
-
Проблемы с безопасностью: Rest API может стать уязвимым для атак, таких как атаки DDoS или инъекции SQL/NoSQL. Однако, правильное проектирование и реализация Rest API может снизить вероятность таких атак.
-
Сложность масштабирования: Если Rest API не был проектирован с учетом масштабируемости, то его масштабирование может стать сложной задачей.
-
Проблемы с совместимостью: Rest API предоставляют некоторые ограниченные возможности для изменения структуры данных, что может привести к проблемам совместимости при обновлении API в дальнейшем.
Однако следует помнить, что REST API все же является одним из наиболее распространенных и удобных методов взаимодействия с сервером, и эти ограничения могут быть разрешены с помощью правильной оптимизации и скорректированных настроек.
1342. Что такое JRPC
JSON-RPC (JavaScript Object Notation Remote Procedure Call) - это протокол удаленного вызова процедур, который использует JSON для кодирования данных. Он позволяет клиентскому приложению вызывать методы на удаленном сервере и получать результаты обратно в формате JSON.
JSON-RPC является одним из множества протоколов API, которые могут использоваться для взаимодействия между клиентскими и серверными приложениями. Он предоставляет простой и легковесный способ обмена данными между разными системами.
JSON-RPC поддерживает различные языки программирования и платформы, что делает его универсальным и гибким в использовании. Он может быть использован для создания распределенных систем, клиент-серверных приложений и многое другое.
JSON-RPC определяет структуру запросов и ответов, которые передаются между клиентом и сервером. Запросы содержат имя метода и параметры, а ответы содержат результат выполнения метода или сообщение об ошибке.
JSON-RPC может быть использован в различных сценариях, таких как веб-разработка, мобильные приложения, микросервисы и другие. Он предоставляет простой и эффективный способ взаимодействия между разными компонентами системы.
Пример использования JSON-RPC:
// Пример запроса JSON-RPC
{
"jsonrpc": "2.0",
"method": "getUser",
"params": {
"userId": 123
},
"id": 1
}
// Пример ответа JSON-RPC
{
"jsonrpc": "2.0",
"result": {
"name": "John Doe",
"age": 30
},
"id": 1
}
В этом примере клиент отправляет запрос на сервер с методом "getUser" и параметром "userId". Сервер выполняет метод и возвращает результат в ответе.
JSON-RPC является одним из множества протоколов API, которые могут использоваться для взаимодействия между клиентскими и серверными приложениями. Другие примеры включают REST, SOAP, GraphQL и gRPC. Каждый из этих протоколов имеет свои особенности и применение в различных сценариях разработки программного обеспечения.
1343. Процесс от пуша кода до продакшена
Процесс от пуша кода до продакшена в Java обычно включает несколько этапов. Вот общий обзор этого процесса:
Разработка и тестирование: Разработчики пишут код на языке Java и тестируют его на локальных машинах или в специальной тестовой среде. Они используют инструменты разработки, такие как IntelliJ IDEA или Eclipse, для написания и отладки кода.
Контроль версий: Разработчики используют систему контроля версий, такую как Git, для отслеживания изменений в коде и совместной работы с другими разработчиками. Они коммитят свои изменения и пушат их в репозиторий.
Непрерывная интеграция (CI): После пуша кода в репозиторий запускается процесс непрерывной интеграции. В этом этапе происходит сборка и тестирование кода автоматически. Различные инструменты CI, такие как Jenkins или GitLab CI/CD, могут быть использованы для автоматизации этого процесса.
Создание пакета (Build): Если процесс CI проходит успешно, то происходит создание исполняемого пакета, такого как JAR или WAR файл. В этом этапе код компилируется, зависимости скачиваются и упаковываются вместе с кодом.
Тестирование: После создания пакета происходит запуск автоматических тестов для проверки работоспособности кода. Это может включать модульные тесты, интеграционные тесты и тесты производительности.
Развертывание (Deployment): Если все тесты проходят успешно, то пакет разворачивается на целевой среде, например, на сервере приложений или в облаке. Инструменты развертывания, такие как Docker или Kubernetes, могут быть использованы для автоматизации этого процесса.
Мониторинг и обслуживание: После развертывания приложения оно мониторится и поддерживается в рабочем состоянии. Можно использовать инструменты мониторинга, такие как Prometheus или ELK Stack, для отслеживания производительности и обнаружения проблем.
Обратная связь и улучшение: Весь процесс от пуша кода до продакшена является итеративным, и важно получать обратную связь от пользователей и разработчиков для улучшения приложения. Это может включать сбор метрик использования, анализ ошибок и обновление функциональности.
Это общий обзор процесса от пуша кода до продакшена в Java. Конкретные детали и инструменты могут различаться в зависимости от организации и проекта.
1344. Сколько нужно instance-ов чтобы обеспечить CI\CD
Для обеспечения CI/CD (непрерывной интеграции и непрерывной доставки) необходимо иметь как минимум два инстанса: один для среды разработки и тестирования (например, staging), а другой для производственной среды (например, production). Это позволяет разделить процессы разработки и тестирования от процессов развертывания и эксплуатации приложения.
Однако, количество необходимых инстансов может варьироваться в зависимости от конкретных требований и масштаба проекта. Например, для более сложных проектов может потребоваться наличие дополнительных сред разработки и тестирования, а также отдельных инстансов для различных окружений (например, staging, QA, production).
Также стоит учитывать, что CI/CD может быть реализован с использованием различных инструментов и платформ, таких как Jenkins, GitLab CI/CD, Travis CI и другие. Каждый инструмент может иметь свои собственные требования к количеству инстансов.
В целом, оптимальное количество инстансов для обеспечения CI/CD зависит от конкретных потребностей и требований проекта. Рекомендуется провести анализ требований и ресурсов проекта, чтобы определить оптимальное количество инстансов для вашего случая.
1345. Kлючевое слово final
Ключевое слово "final" в Java используется для обозначения константности. Когда переменная или метод объявлены с ключевым словом "final", их значение или реализация не может быть изменена после инициализации.
Переменные final Когда переменная объявлена с ключевым словом "final", она становится константой, то есть ее значение не может быть изменено после присваивания. Попытка изменить значение переменной final приведет к ошибке компиляции.
Пример:
final int x = 10;
x = 20; // Ошибка компиляции: значение переменной final не может быть изменено
Методы final Когда метод объявлен с ключевым словом "final", он не может быть переопределен в подклассах. Это означает, что реализация метода остается неизменной и не может быть изменена или расширена в подклассах.
Пример:
public class Parent {
public final void display() {
System.out.println("Parent class");
}
}
public class Child extends Parent {
public void display() { // Ошибка компиляции: метод final не может быть переопределен
System.out.println("Child class");
}
}
Классы final Когда класс объявлен с ключевым словом "final", он не может быть наследован. Такой класс считается завершенным и не может быть расширен другими классами.
Пример:
public final class FinalClass {
// Код класса
}
public class ChildClass extends FinalClass { // Ошибка компиляции: класс final не может быть наследован
// Код подкласса
}
Использование ключевого слова "final" позволяет создавать надежный и безопасный код, защищая значения переменных, реализацию методов и предотвращая наследование классов.
1346. Класс String
Класс String в Java представляет собой неизменяемую последовательность символов. Он является одним из наиболее часто используемых классов в Java и предоставляет множество методов для работы со строками.
Создание объекта String: Объекты класса String можно создавать с помощью ключевого слова new или с помощью литерала строки. Например:
String str1 = new String("Hello"); // создание объекта с использованием ключевого слова new
String str2 = "World"; // создание объекта с использованием литерала строки
Неизменяемость строк: Одной из особенностей класса String является его неизменяемость. Это означает, что после создания объекта String его значение не может быть изменено. Вместо этого, любые операции над строками создают новые объекты String.
Операции со строками: Класс String предоставляет множество методов для работы со строками. Некоторые из наиболее часто используемых методов включают:
- length(): возвращает длину строки.
- charAt(int index): возвращает символ по указанному индексу.
- substring(int beginIndex, int endIndex): возвращает подстроку, начиная с указанного индекса и до указанного индекса.
- concat(String str): объединяет текущую строку с указанной строкой.
- toUpperCase(): преобразует все символы строки в верхний регистр.
- toLowerCase(): преобразует все символы строки в нижний регистр.
- trim(): удаляет начальные и конечные пробелы из строки.
- equals(Object obj): сравнивает текущую строку с указанным объектом на равенство.
- startsWith(String prefix): проверяет, начинается ли текущая строка с указанного префикса.
- endsWith(String suffix): проверяет, заканчивается ли текущая строка указанным суффиксом.
Пример использования методов класса String:
String str = "Hello, World!";
int length = str.length(); // длина строки
char firstChar = str.charAt(0); // первый символ строки
String substring = str.substring(7, 12); // подстрока "World"
String newString = str.concat(" Welcome!"); // объединение строк
String upperCase = str.toUpperCase(); // преобразование в верхний регистр
String lowerCase = str.toLowerCase(); // преобразование в нижний регистр
String trimmedString = str.trim(); // удаление пробелов
boolean isEqual = str.equals("Hello, World!"); // сравнение строк
boolean startsWith = str.startsWith("Hello"); // проверка на начало строки
boolean endsWith = str.endsWith("World!"); // проверка на конец строки
Класс String в Java также поддерживает оператор + для конкатенации строк. Например:
String str1 = "Hello";
String str2 = "World";
String result = str1 + " " + str2; // результат: "Hello World"
Класс String в Java имеет много других методов, которые предоставляют различные возможности для работы со строками. Это лишь некоторые из основных методов, которые могут быть полезны при работе с классом String.
1347. Передача значение по ссылке/по значению
В Java значения могут передаваться по ссылке или по значению, в зависимости от типа данных.
Передача значения по значению При передаче значения по значению в Java, копия значения передается в метод или функцию. Это означает, что изменения, внесенные внутри метода, не влияют на оригинальное значение.
Пример:
public class Main {
public static void main(String[] args) {
int num = 5;
System.out.println("Before method call: " + num);
modifyValue(num);
System.out.println("After method call: " + num);
}
public static void modifyValue(int value) {
value = 10;
System.out.println("Inside method: " + value);
}
}
Вывод:
Before method call: 5
Inside method: 10
After method call: 5
В приведенном примере значение переменной num не изменяется после вызова метода modifyValue(), поскольку значение передается по значению.
Передача значения по ссылке При передаче значения по ссылке в Java, ссылка на объект передается в метод или функцию. Это означает, что изменения, внесенные внутри метода, будут отражены на оригинальном объекте.
Пример:
public class Main {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder("Hello");
System.out.println("Before method call: " + sb);
modifyValue(sb);
System.out.println("After method call: " + sb);
}
public static void modifyValue(StringBuilder value) {
value.append(" World");
System.out.println("Inside method: " + value);
}
}
Вывод:
Before method call: Hello
Inside method: Hello World
After method call: Hello World
В приведенном примере значение объекта sb изменяется после вызова метода modifyValue(), поскольку ссылка на объект передается по ссылке.
Обратите внимание, что в Java все примитивные типы передаются по значению, а все объекты передаются по ссылке.
1348. LinkedHashSet
LinkedHashSet - это класс в Java, который реализует интерфейс Set и представляет собой коллекцию элементов, не содержащих дубликатов, и сохраняющих порядок вставки элементов.
Особенности LinkedHashSet:
-
Уникальность элементов: LinkedHashSet не содержит дубликатов элементов. Если вы попытаетесь добавить элемент, который уже присутствует в коллекции, он не будет добавлен. -
Порядок вставки: LinkedHashSet сохраняет порядок вставки элементов. Это означает, что элементы будут возвращаться в том порядке, в котором они были добавлены. -
Быстрый доступ: LinkedHashSet обеспечивает быстрый доступ к элементам благодаря использованию хэш-таблицы для хранения элементов. -
Итерация: LinkedHashSet поддерживает эффективную итерацию по элементам коллекции. -
Неупорядоченность: В отличие от класса TreeSet, LinkedHashSet не сортирует элементы в естественном порядке или по заданному компаратору. Он сохраняет порядок вставки элементов.
Пример использования LinkedHashSet в Java:
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args) {
// Создание объекта LinkedHashSet
LinkedHashSet<String> set = new LinkedHashSet<>();
// Добавление элементов в коллекцию
set.add("яблоко");
set.add("банан");
set.add("апельсин");
set.add("груша");
// Вывод элементов коллекции
for (String fruit : set) {
System.out.println(fruit);
}
}
}
Вывод:
яблоко
банан
апельсин
груша
В этом примере мы создаем объект LinkedHashSet и добавляем в него несколько фруктов. Затем мы проходимся по коллекции и выводим каждый элемент. Обратите внимание, что элементы выводятся в том порядке, в котором они были добавлены.
1349. HashSet
HashSet в Java является реализацией интерфейса Set и представляет собой коллекцию, которая не содержит дублирующихся элементов. В HashSet элементы не упорядочены и не имеют индексов. Основные особенности HashSet:
Уникальность элементов: HashSet гарантирует, что каждый элемент в коллекции будет уникальным. Если вы попытаетесь добавить элемент, который уже присутствует в HashSet, он будет проигнорирован.
Быстрый доступ: HashSet обеспечивает быстрый доступ к элементам благодаря использованию хэш-таблицы. Время выполнения операций добавления, удаления и поиска элементов в HashSet обычно является постоянным, то есть O(1).
Неупорядоченность: Элементы в HashSet не упорядочены и не имеют определенного порядка. Порядок элементов может меняться при каждой операции добавления или удаления.
Не поддерживает дубликаты: HashSet не позволяет хранить дублирующиеся элементы. Если вы попытаетесь добавить элемент, который уже присутствует в коллекции, он будет проигнорирован.
Не синхронизирован: HashSet не является потокобезопасной коллекцией. Если необходимо использовать HashSet в многопоточной среде, следует обеспечить синхронизацию доступа к нему.
Пример использования HashSet в Java:
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
// Создание объекта HashSet
HashSet<String> set = new HashSet<>();
// Добавление элементов в HashSet
set.add("яблоко");
set.add("банан");
set.add("апельсин");
set.add("груша");
// Вывод содержимого HashSet
System.out.println(set); // [яблоко, груша, банан, апельсин]
// Проверка наличия элемента в HashSet
System.out.println(set.contains("яблоко")); // true
// Удаление элемента из HashSet
set.remove("банан");
// Вывод обновленного содержимого HashSet
System.out.println(set); // [яблоко, груша, апельсин]
// Очистка HashSet
set.clear();
// Проверка, является ли HashSet пустым
System.out.println(set.isEmpty()); // true
}
}
В данном примере создается объект HashSet, в который добавляются несколько элементов. Затем выводится содержимое HashSet, проверяется наличие элемента, удаляется один элемент, выводится обновленное содержимое и проверяется, является ли HashSet пустым.
1350. Kласс Phaser
Класс Phaser в Java представляет собой синхронизационный механизм, который позволяет координировать выполнение потоков. Он является частью пакета java.util.concurrent и был введен в Java 7.
Основные особенности класса Phaser:
Фазы (Phases): Класс Phaser разделяет выполнение на несколько фаз. Каждая фаза представляет собой точку синхронизации, в которой потоки могут остановиться и дождаться, пока все остальные потоки достигнут этой фазы.
Регистрация потоков (Thread Registration): Потоки могут зарегистрироваться в экземпляре класса Phaser с помощью метода register(). После регистрации, потоки могут участвовать в синхронизации фаз.
Синхронизация фаз (Phase Synchronization): Когда все зарегистрированные потоки достигают определенной фазы, Phaser переходит к следующей фазе. Потоки могут использовать метод arriveAndAwaitAdvance() для ожидания достижения фазы всеми потоками.
Динамическое изменение количества потоков (Dynamic Thread Count): Класс Phaser позволяет динамически изменять количество зарегистрированных потоков с помощью методов register() и arriveAndDeregister().
Фазы с действиями (Phases with Actions): Класс Phaser также поддерживает фазы с действиями, которые выполняются только одним потоком при достижении определенной фазы.#### Класс Phaser в Java
Класс Phaser в Java представляет собой синхронизационный механизм, который позволяет контролировать выполнение потоков. Он является частью пакета java.util.concurrent и предоставляет возможность синхронизации потоков на определенных фазах выполнения.
Основные особенности класса Phaser:
Фазы выполнения: Phaser разделяет выполнение на несколько фаз. Каждая фаза представляет собой точку синхронизации, где потоки могут остановиться и дождаться, пока все остальные потоки достигнут этой фазы.
Регистрация потоков: Потоки могут зарегистрироваться в Phaser с помощью метода register(). После регистрации, поток будет участвовать в синхронизации на каждой фазе выполнения.
Синхронизация на фазах: Потоки могут вызывать метод arriveAndAwaitAdvance(), чтобы дождаться, пока все остальные потоки достигнут текущей фазы. После этого, все потоки продолжат выполнение на следующей фазе.
Динамическое изменение количества потоков: Количество зарегистрированных потоков может быть изменено во время выполнения с помощью методов register() и arriveAndDeregister().
Управление завершением: Phaser предоставляет методы для определения завершения выполнения всех фаз. Методы isTerminated() и awaitTermination() позволяют проверить, завершено ли выполнение всех фаз.
Пример использования класса Phaser:
import java.util.concurrent.Phaser;
public class PhaserExample {
public static void main(String[] args) {
Phaser phaser = new Phaser(1); // Создание Phaser с одной зарегистрированной партией
// Создание и запуск потоков
for (int i = 0; i < 3; i++) {
new Thread(new Worker(phaser)).start();
}
// Регистрация главного потока
phaser.arriveAndAwaitAdvance();
// Выполнение работы в несколько фаз
for (int i = 0; i < 3; i++) {
// Выполнение фазы
phaser.arriveAndAwaitAdvance();
System.out.println("Фаза " + i + " завершена");
}
// Проверка завершения выполнения всех фаз
if (phaser.isTerminated()) {
System.out.println("Выполнение всех фаз завершено");
}
}
static class Worker implements Runnable {
private final Phaser phaser;
public Worker(Phaser phaser) {
this.phaser = phaser;
phaser.register(); // Регистрация потока в Phaser
}
@Override
public void run() {
// Выполнение работы в каждой фазе
for (int i = 0; i < 3; i++) {
System.out.println("Поток " + Thread.currentThread().getId() + " выполняет фазу " + i);
phaser.arriveAndAwaitAdvance(); // Ожидание остальных потоков
}
phaser.arriveAndDeregister(); // Отмена регистрации потока
}
}
}
В этом примере создается Phaser с одной зарегистрированной партией и тремя потоками. Каждый поток выполняет работу в каждой фазе и ожидает остальные потоки с помощью метода arriveAndAwaitAdvance(). После выполнения всех фаз, проверяется завершение выполнения с помощью метода isTerminated().